MyBlog
【Paper】The Google File System
last modified: 2020-04-06 12:25
GFS由2种类型节点组成,master和chunk-server. master保存系统的元数据信息,chunk-server存储实际数据文件。
数据在GFS中被切分为chunk,chunk保存在chunk-server中,默认64MB一个。
MASTER DATA
- filename -> array of chunk handle(the unique ID of a chunk){nv: non-volatile}
- handle -> list of chunk-servers(primary, secondaries) {v}
- 另外还保存了version number{nv}, 谁是primary{v}和lease expiration{v}
- log, checkpoint -> disk
通过文件名和offset,master可以找到对应的chunk handle。通过handle找到chunk-server。对于nv的数据,使用write ahead log保证其可靠性。
STARTUP
系统启动后,chunk-severs向master注册自己,然后周期性由master向chunk-server发送心跳,用于保活及状态信息同步(piggybacked)。
这样做的好处是简化了master处理chunk-sever上下线的复杂度,master在系统中是个单点,它的实现越简单越好。
master在全局视角下存在单点故障,但实际上他也通过WAL将状态持久化并同步给其它backup节点来保障可用性。
READ
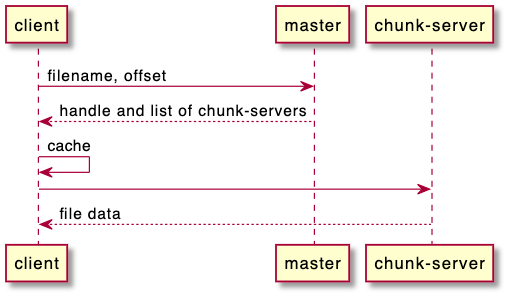
读取很简单,client向master询问filename,及offset。master返回chunk-server地址列表。client请求chunk-server读取数据,并把filename-> chunk-servers的mapping缓存到本地,以减少master的请求次数。
WRITE
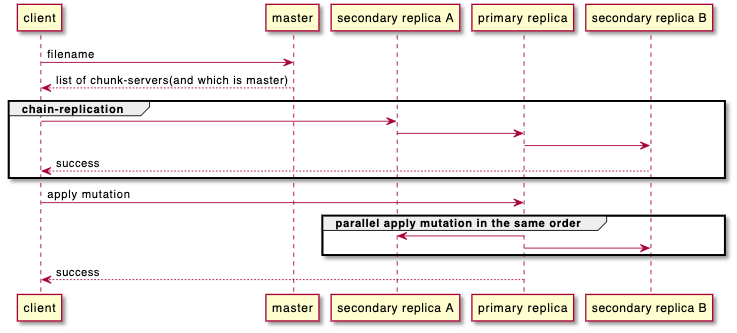
- client发送写文件请求到master(with filename)
- master返回给client要写的chunk-server列表(包括谁是primary)
- client执行写入(使用chain优化带宽占用,client只需要写离自己最近的server,比如同rack或同机房,注意这个chunk-server并不需要是primary)
- chain成功后,client再通知primary chunk-server执行写入操作。为什么有这步呢?因为同一个file可能存在并发写入,这样有很多mutation操作,在不同的replica上的顺序是不一样的(取决于client位置,pick了谁作为first chain node)。primary的作用是使所有secondary replica也按自己的mutation顺序来执行写操作。
写入异常的场景
上面是一个正常数据写入流程,如果写入过程某个chunk-server写失败了怎么办?
| replica A | replica B | replica C |
|---|---|---|
| B(retry success) | B(retry success) | B(retry success) |
| C | C | C |
| B | B | N/A(写入失败) |
| A | A | A |
某个secondary replica写入失败client会重试,这样导致,如A副本中:ABCB的结果,与我们预期不一致。GFS不提供数据一致性的保证。
一般有2种办法解决这个问题:
- 用户给数据加seq number,使用时自己排序、去重
- 避免多个client并发写同一个文件,用一个client写
GFS没有提供回滚的机制,比如replica C写B失败时,回滚replica A/B的写入,来保证数据正确性和强一致。这样的设计可以把系统复杂度降低,试想一下如果要处理这个出错,一种方法是需要master重新选择一个新的replica节点,重新走一遍chain replica和apply mutation过程,这个类似整个流程的重试动作,使primary和master的实现都变复杂,另一种方式是使用paxos写入,性能就差多了。这里牺牲强一致性是一个trade-off,出错后复用garbage-collect的逻辑,使整个设计变的自然、简洁,chain-replication也使性能出色。
FAULT TOLERANCE
- master failure
切换到backup master。可以认为master和backup master是CNAME下2条记录,backup master通过WAL同步master的操作记录。当master挂掉以后,自动切换到backup即可。切换期间GFS短暂不可用。
- primary replica failure
假设master与primary发生网络分区,master通过heartbeat检测到primary失败,等待lease过期后,选一位新的primary节点(lease过期前写不可用)。
对于旧的primary节点,若从网络分区中恢复,master检测其chunk version #,检查是否成为stale节点。若是则选一些新的节点代替stole节点,stole节点在执行完garbage-collect后重新加入集群。
- secondary replica failure
secondary replica失败会导致client mutation操作失败,此时client会负责重试。多次重试失败后,返回错误。
这时该replica因为缺少了这部分mutation,会变成stale节点。对其后续处理过程如primary。
client可能是从stale replica上读数据。用户需要自行处理这些stale read,GFS不保障chunk的强一致性读。(stale节点GC需要一个过程)