MyBlog
【Paper】Flink End-to-End Exactly-Once语义实现
last modified: 2021-03-17 12:37
这是几篇论文阅读的综合笔记,主要内容范围,
3) Flink基于分布式快照(checkpoint)和2PC实现的End-to-End Exactly-Once
一、分布式快照
分布式系统为Fault Tolerant,系统各节点需要对State达成全局一致并持久化,以便Failure发生时,各节点能从一个一致的State进行恢复。
为达成上述全局一致,直观来讲,可以在某一刻让系统静止,用快照(Snapshot)的方式,记录下此刻整个系统State。但在分布式系统中,由于时钟同步问题,这个方案无法实现。
而《Distributed Snapshots: Determining Global States of Distributed Systems》论文中,则提出了该问题的一个解决方案。
先做一个抽象:
假设系统由进程,及进程之间的Channel组成(Channel视作一个无限容量的FIFO),构成一个有向图,进程间通过Channels连接,分别是Input Channels和Output Channels。Message通过Channel在系统中传播,并假设这些Message满足1)有序,2)不丢不重。
进程收到Message后,会根据业务逻辑改变Local State。一个进程的Local State和Channel State(Input Channels中的Message)构成了该进程的局部快照。所有进程的局部快照总和,即为系统全局快照。这就是Chandy&Lamport算法的核心思想。
具体的,该算法分为3个步骤,
- 快照初始化
- 进程Pi启动快照
- 发起者Pi,记录自己的Local State,并创建Marker Message
- Pi通过N-1个Out Channels将Marker Message发送到其它进程。Out Channels:Cij(j = 1 to N & j != i).
- Pi开始记录Input Channels中所有Message。Input Channels: Cji (j = 1 to N & j != i).
- 快照传播
- 如果进程Pj从Input Channel Ckj收到Marker Message, 并且这是Pj第一次收到:
- Pj记录自己的Local State,并将Ckj Channel标记为Empty
- Pj将Marker Message通过N-1个Output Channels发送到其它进程。Output Channels:Cjm(m = 1 to N & m != j)
- Pj开始记录所有Input Channels中的Message。Input Channels: Clj (l = 1 to N & l != j & l != k)
- 如果Pj不是第一次收到Marker Message:
- 将Input Channel Ckj标记为记录结束,即从开始Ckj记录后,所有的Messages都已到达
- 如果进程Pj从Input Channel Ckj收到Marker Message, 并且这是Pj第一次收到:
- 快照结束
- 快照算法结束,当:
- 所有进程都已收到Marker Message (表示所有进程Local State都已记录)
- 所有进程,都已在N-1个Input Channel收到了Marker Message (表示所有Channel State都已记录)
- 以上所有Local State和Channel State即构成了全局快照
- 快照算法结束,当:
二、分布式快照Flink实践
Chandy&Lamport的算法,在工程实现上,有2处性能缺陷:
- 所有节点需要停止工作等待全局Snapshot完成,影响时效性和处理速度
- Snapshot包含Local State,和Channel State(未处理及传输过程中所有的Message),导致Snapshot比较大(本来一个pv,却Snapshot了1000条raw messages)
Flink在工程上进行了相关优化 —— Asynchronous Barrier Snapshot(ABS)
Flink中,分布式的参与者类型有Source,Window,Sink Operator,构成一个DAG;Source Operator消费数据,Window Operator处理数据,Sink Operator落地结果数据。
ABS算法的执行流程如下:
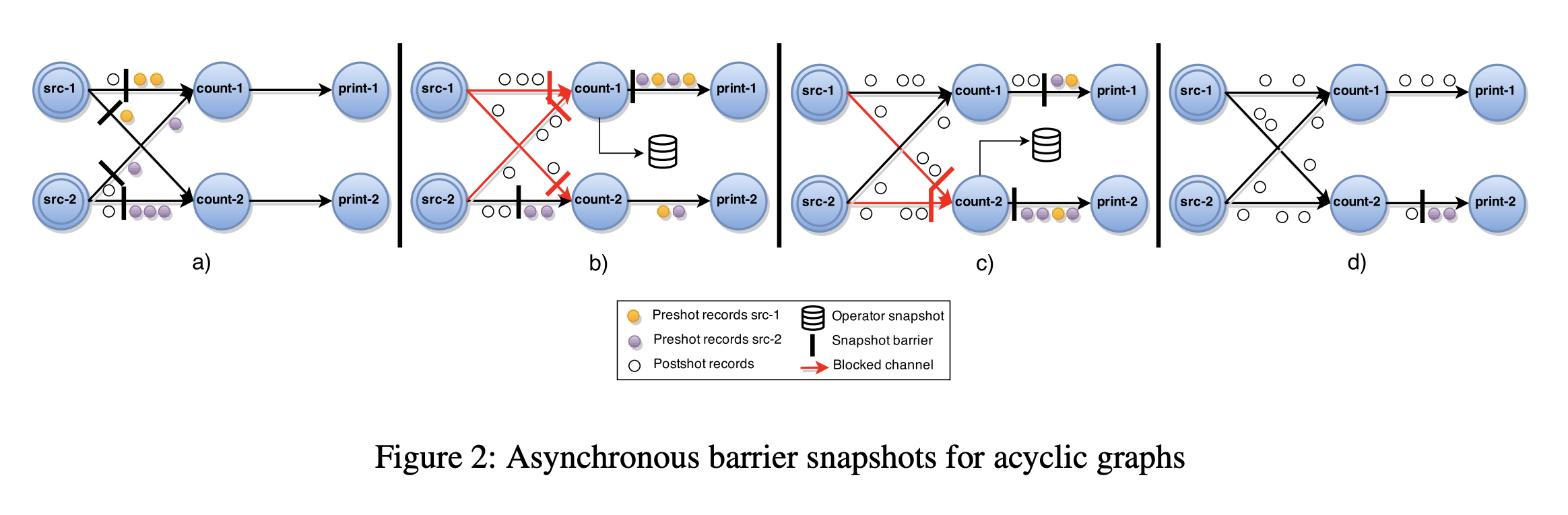
论文中的算法伪码:
# Algorithm 1 Asynchronous Barrier Snapshotting for Acyclic Execution Graphs
1: upon event <Init | input_channels, output_channels, fun, init_statei> do
2: state := init_state; blocked_inputs := 0;
3: inputs := input_channels;
4: out_puts := output_channels; udf := fun;
5:
6: upon event <receive | input, <barrier>> do
7: if input != Nil then # 非Source节点收到Barrier,阻塞当前Input Channel
8: blocked_inputs := blocked_inputs ∪ {input};
9: trigger {block | input};
10: if blocked_inputs = inputs then # 所有的Input Channels都收到Barrier;#优化1所在,不再做Channel State快照
11: blocked_inputs := 0;
12: broadcast {send | outputs, <barrier>>; # Barrier广播到所有Output Channels
13: trigger {snapshot | state}; # 触发Snapshot
14: for each inputs as input # Unblock所有Blocked的Input Channels;#优化2所在,继续处理Message
15: trigger <unblock | input>;
16:
17:
18: upon event <receive | input, msg> do # 非Barrier的数据处理
19: {state1 ,out_records} := udf(msg, state);
20: state := state1;
21: for each out_records as {out_put, out_record}
22: trigger <send | output, out record>;
Coordinator周期性地在所有Source插入Barrier(Marker在Flink的叫法)
当一个Source节点接收到Barrier时,对Local State做Snapshot,并且Broadcast Barrier到所有的下游节点(图a)
当一个非Source节点从它的Input Channel中接收到一个Barrier时,它会Block当前的Channel直到接收该节点所有Input Channels发送的Barrier(图b & 伪码第9行)
当从所有Input Channel都接收到Barrier之后,节点做Local Snapshot,并Broadcast Barrier到所有的Output Channels(图c & 伪码12-13行)
最后,Unblock所有Input Channels,继续进行计算(图d & 伪码第15行)
以上,
节点等待所有Input Channels到达再做Local State Snapshot,此时Channel State为空,因为已经没有Messages在Input Channels。所以全局Snapshot即等于所有节点Local Snapshot的总和,这解决了原算法Snapshot Channel State(Input Channel Messages)导致的大Snapshot问题
节点在广播完Barrier,并做完Local Snapshot后,可以继续处理后面的Messages,而无需等待全局Snapshot完成,即实现了全局视角异步Snapshot能力
三、Flink基于分布式快照(Checkpoint)和2PC的End-to-End Exactly-Once实现
在分析End-to-End Exactly-Once之前,先看一下Flink如何保证的自身消息处理的Exactly-Once;Flink自身的Exactly-Once是通过周期性的Checkpoint机制来保障的,Checkpoint即是分布式快照的实现,Checkpoint中保存了:
Application的当前状态
消费到Input流的位置(以Kafka为例,指的是consumer offset)
当进行故障恢复时,Flink从最新的Checkpoint中读取状态(如pv=10),及Input流的位置(如kafka topic=tracking, partition=12, offset=19),则只需要从offset=19处继续消费,且Metric从pv=10开始重新累加即可。
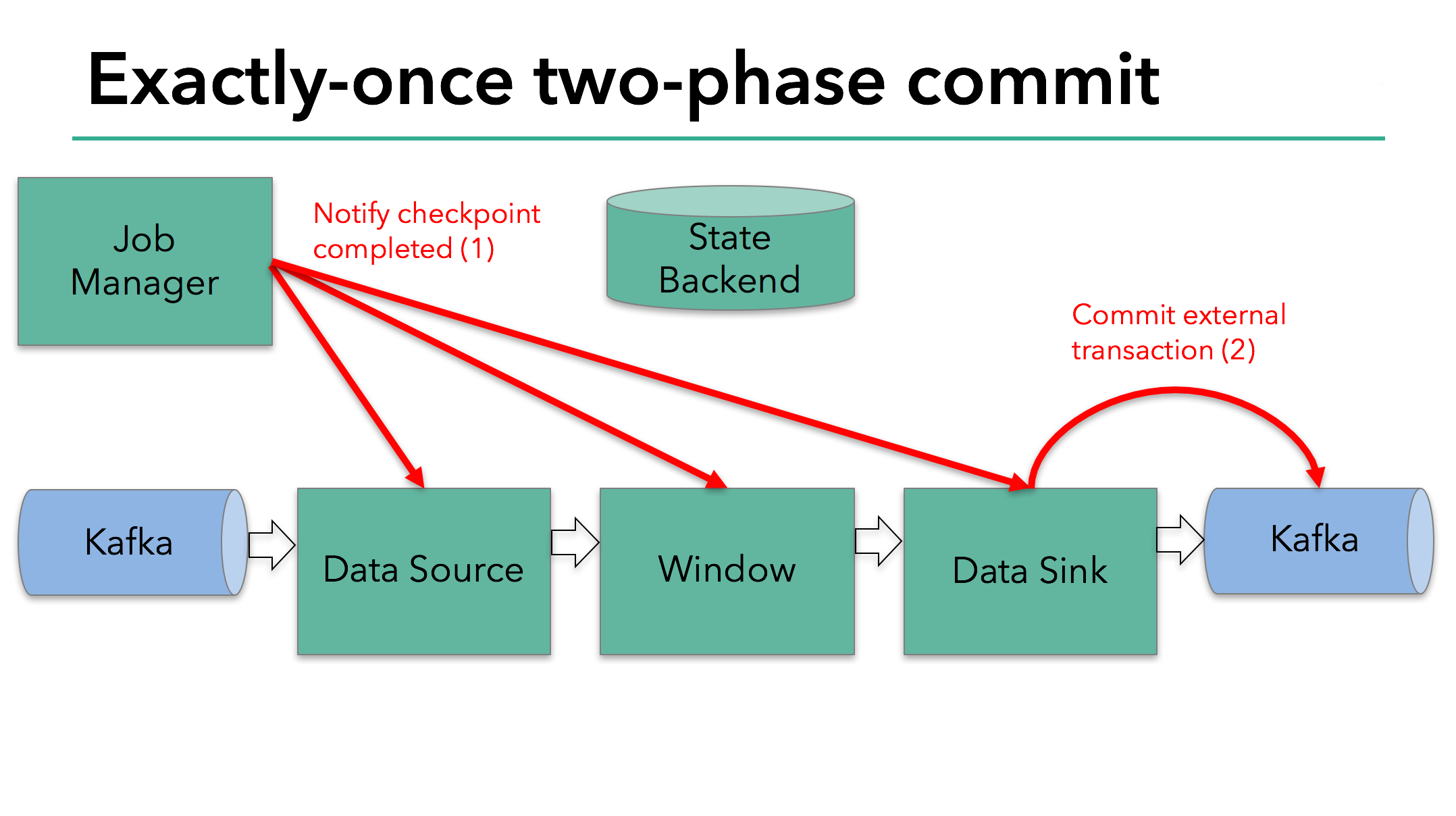
而End-to-End Exactly-Once,则需要Sink的外部组件支持2PC事务,2PC分为2个阶段,1)pre-commit,2)commit
下面以Kafka为例(Kafka0.11开始,支持Producer的2PC事务提交)其过程如下,
Flink通过开启一个Checkpoint,进入2PC的pre-commit阶段,这个阶段,由Flink JobManager向Source Operator插入一个Checkpoint Barrier.
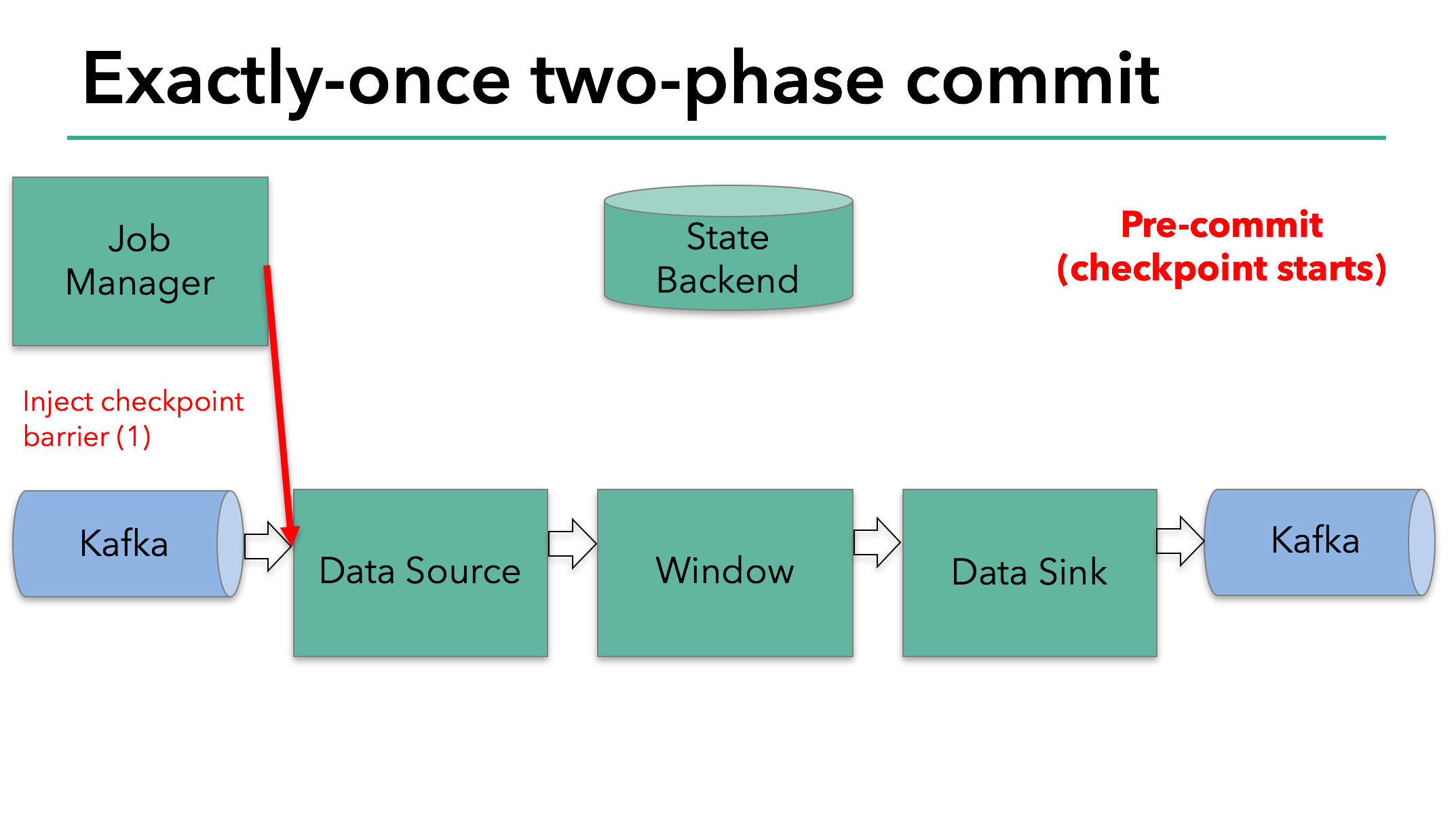
Barrier在Operator中传播,每到达一个Operator,它都触发该节点对State状态后端进行Snapshot,使该节点进入pre-commit阶段。任意一个Operator pre-commit失败,则全局Abort,回滚到上一个成功的Checkpoint.
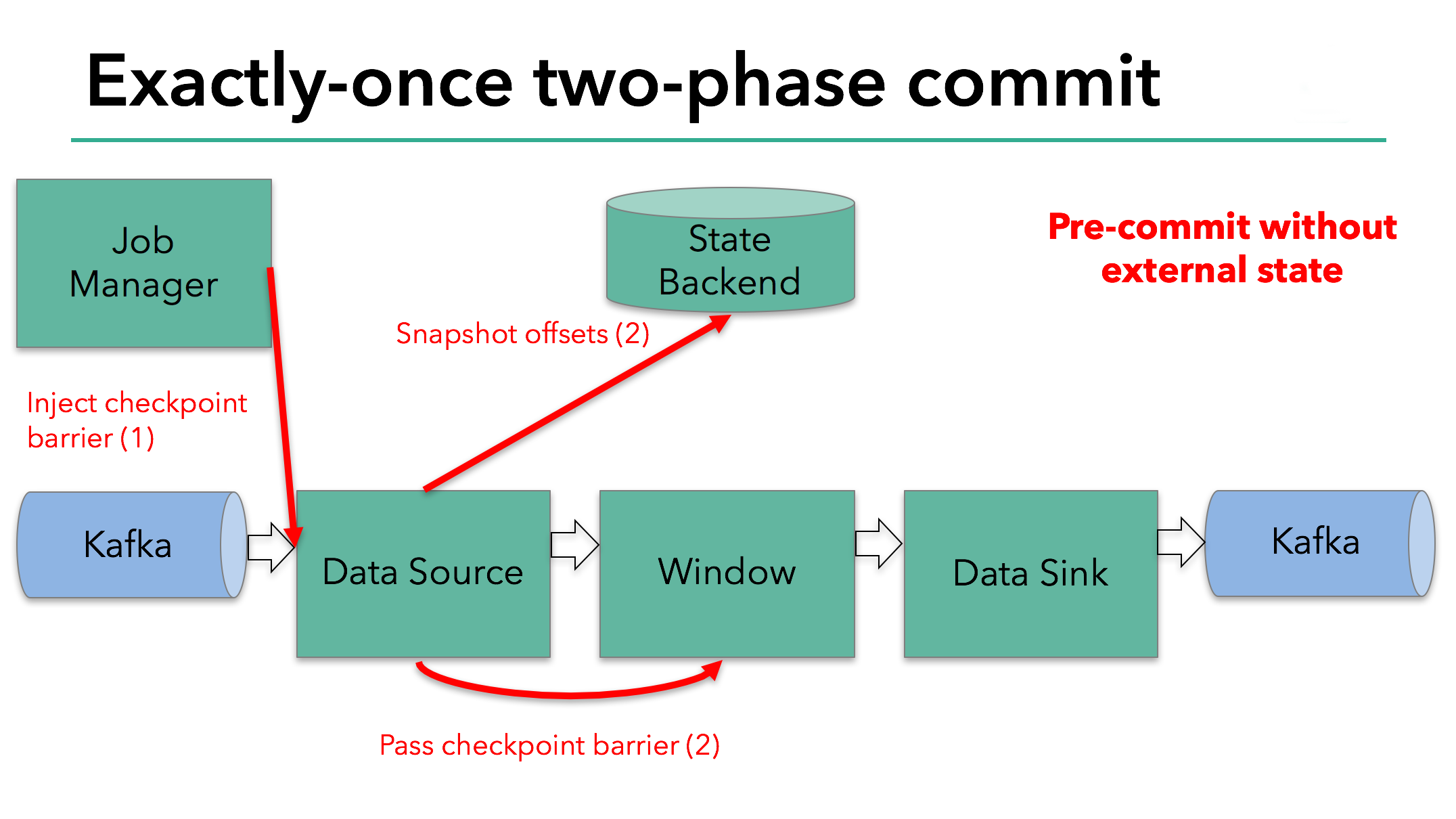
Source Operator保存Kafka offset后,将Barrier发往下游Operator. 注意,Snapshot State只针对由Flink状态后端保存的Internal State适应,如果是一个External State,比如该例中Sinker的状态是External的(保存到Kafka),则需要External组件提供Exactly-Once保障。
该例的pre-commit阶段,除了Snapshot状态后端的State,Sink还需要发起Kafka事务的pre-commit.
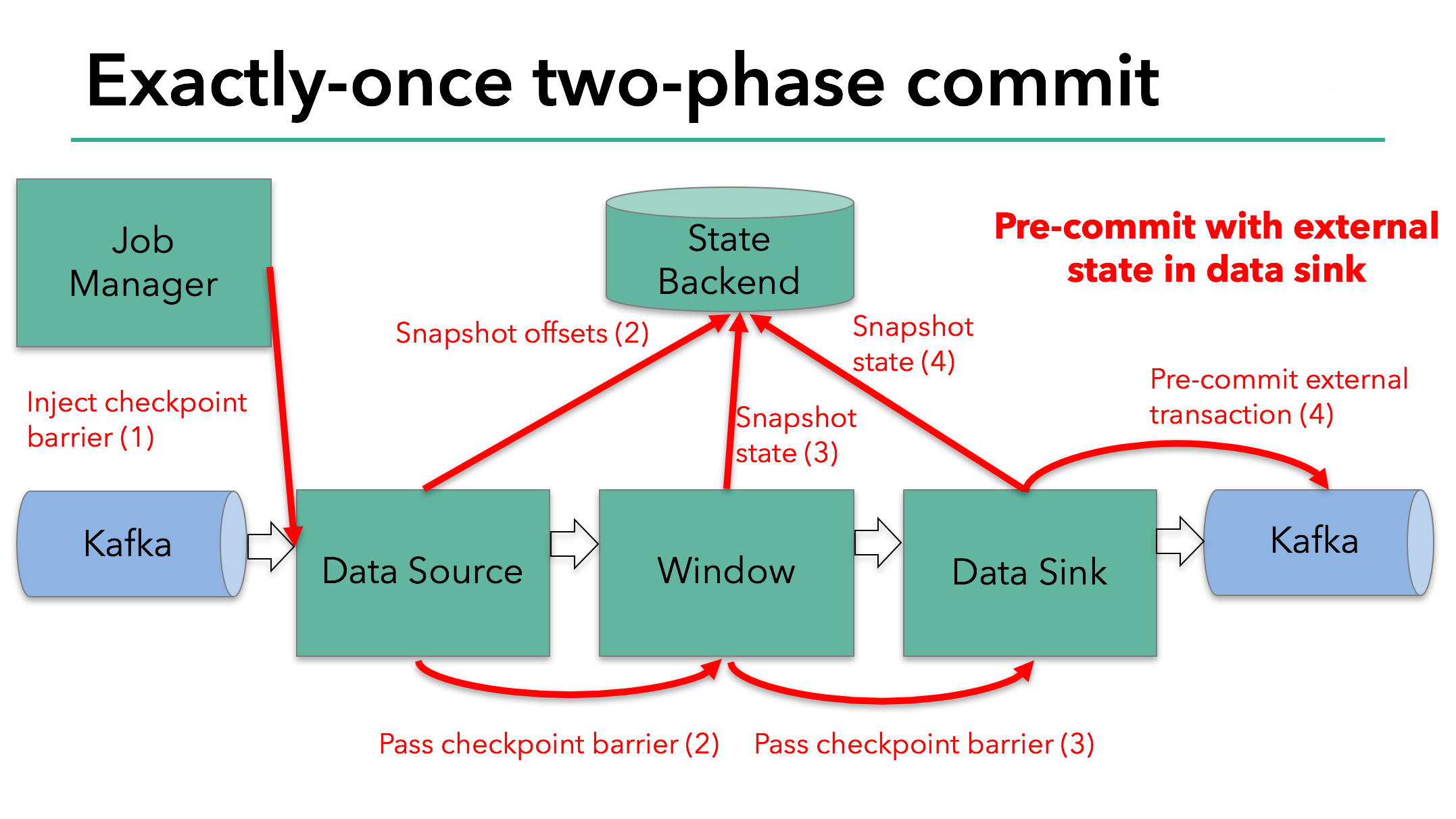
当Barrier到达了所有Operator,并且所有触发的Snapshot都完成后,pre-commit阶段结束。这时,整个Checkpoint完成,包含了Internal State和pre-commit的External State。这时若发生Failure,Application将从这个Checkpoint进行恢复。
接下来进入commit阶段,JobManager通知所有Operators Checkpoint已成功。由于Source和Window Operator没有External State,因此不需要进行任何操作。Sink Operator进行Kafka的commit。pre-commit成功后,所有人都需要保证各自的commit一定成功。
如果因为如网络原因,Kafka commit失败,则整个Application失败,重启后继续commit,这一步非常关键,如果允许commit失败,则数据会丢失,不能实现Exactly-Once语义。
四、参考资料
- An example run of the Chandy-Lamport snapshot algorithm
- Let’s study distributed systems — 3. Distributed snapshots
- Distributed Snapshots: Determining Global States of Distributed Systems
- Lightweight Asynchronous Snapshots for Distributed Dataflows
- Global Snapshot, Chandy Lamport Algorithm & Consistent Cut
- High-throughput, low-latency, and exactly-once stream processing with Apache Flink™
- An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)