MyBlog
缓存设计的三种策略
last modified: 2021-05-12 15:39
DB cache是分层设计的一个场景,是局部性原理的一个应用。分层会产生数据一致性的问题,这与操作系统Page cache存在脏数据的原理是一样的。
如果抽象一下,这本质上是同一个数据放在不同存储节点上引起的问题。要想让两个节点上的同一个数据一致,首先可以使用共识算法,比如Paxos日志复制状态机来实现。共识算法的原理是使各节点对同一个Key的Value的值达成共识。
另外还可以使用2PC事务的方式来解决。共识算法是对一个值的共识,但2PC更多是保证多个节点上的原子性操作,比如在A节点扣10块钱,在B节点加10块钱。但是如果我们把扣/加钱的操作换成set某一个K/V,可以跟共识算法达到一样的效果。
但是无论是2PC还是Paxos,它们的实现都太复杂了。因此在实际的cache设计中,通常使用一些trade-off的方案,来尽量保证数据一致。注意这里的尽量,是指除了Paxos或2PC的实现,其它所有实现都会存在不一致的问题。
下面是3种Cache的实现策略:
一、Cache aside(最常用)
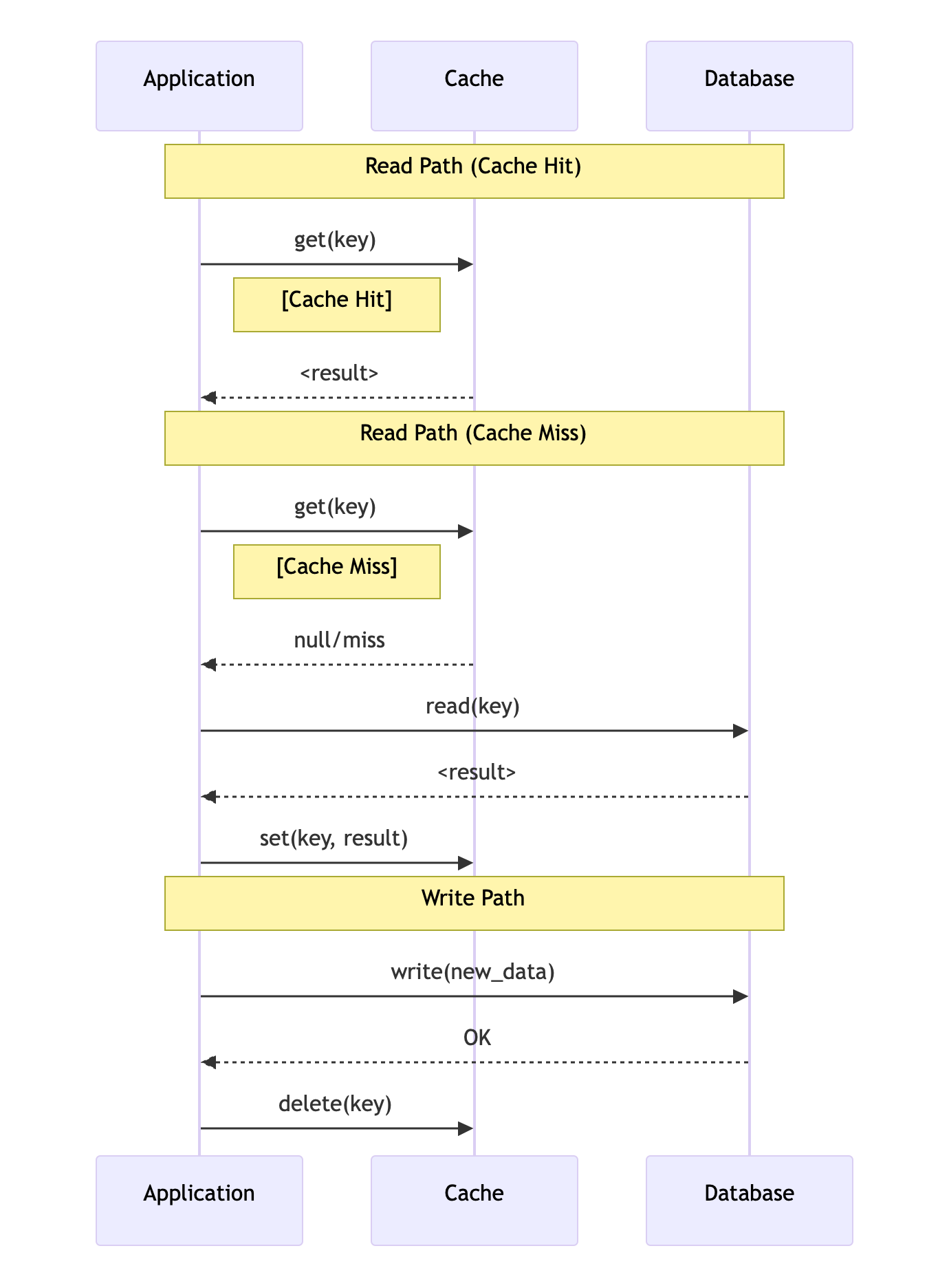
第一个cache aside的策略,
读的过程:读cache,如果hit则成功返回,如果miss则读DB,并将读的结果顺便更新到cache,这也是aside命名的来源。
写的过程:写DB,成功后使cache失效。
时序图如下:
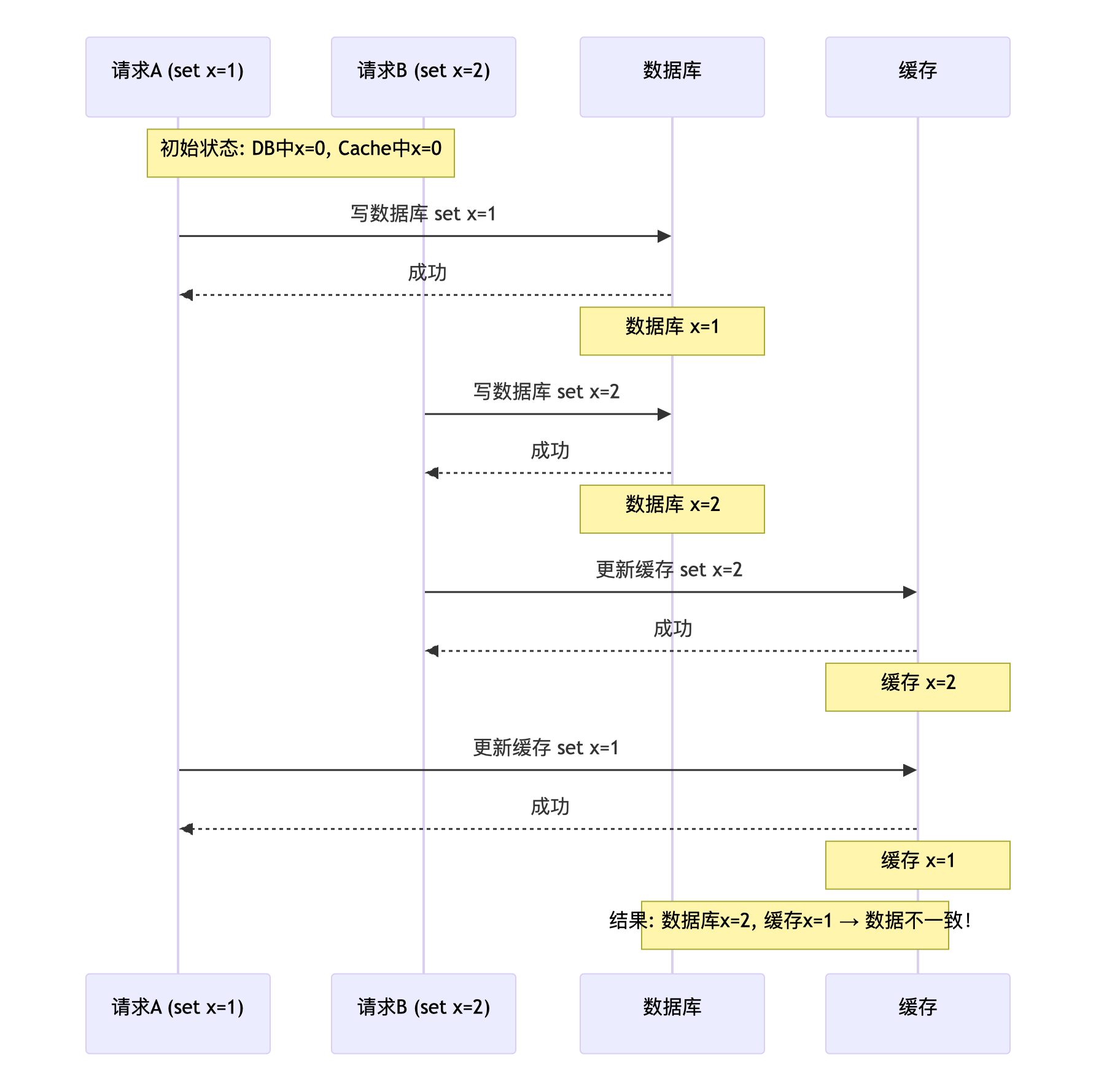
为什么写DB成功是失效掉cache,而不是去更新cache呢?
想像这样一个场景,两个并发写请求A和B,如果A先更新数据库(set x=1),B后更新数据库(set x=2),B先更新了cache,A因为网络等各种原因后更新的cache(set x=1)。那么最终数据库是x=2,而cache中x=1导致数据不一致。
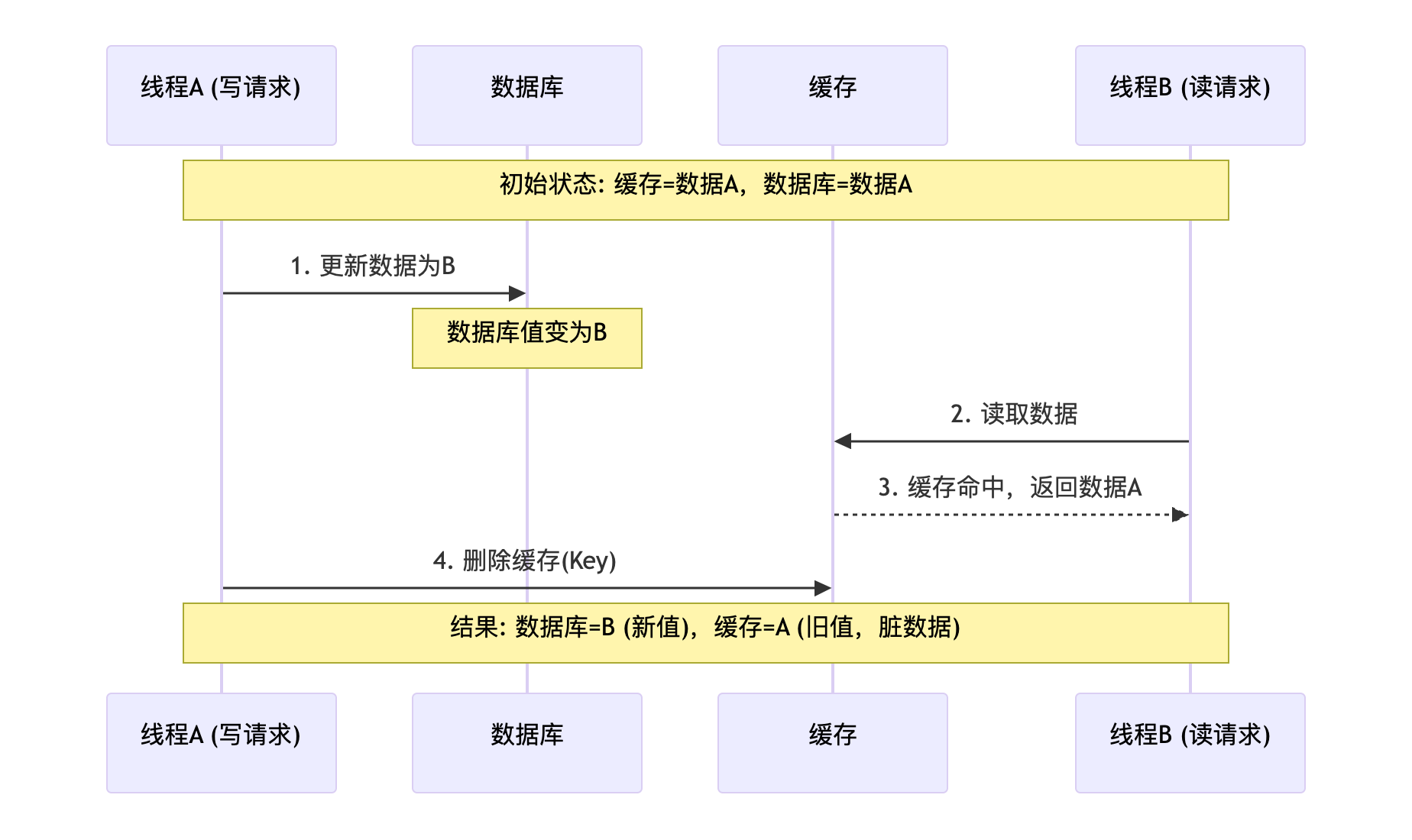
Cache aside策略是否就没问题呢?当然也有问题。
Cache aside问题一(短暂数据不一致)
由于更新DB与使缓存失效不是原子操作,期间的读请求从Cache中读到的都是旧数据。缓存不一致的时间即更新DB与使缓存失效之间的时间。
解决这个问题的方法是写操作加一个锁,保障更新DB与缓存失效的原子性。但会带来性能损耗,适合写少读多的场景。
Cache aside问题二(不特殊处理,会导致长期数据不一致)
想象这样一种场景,B读cache miss去读DB,读出一个值x=3,此时A写DB x=4成功后将cache失效,B接着将x=3写cache,最终cache中x=3,而DB中x=4。这种场景是存在的,即B先读,后写cache,在此期间一个写操作先执行完成。
如果后序缓存不过期 & 没有写操作,则Cache中一直是旧数据,DB与Cache数据不一致。
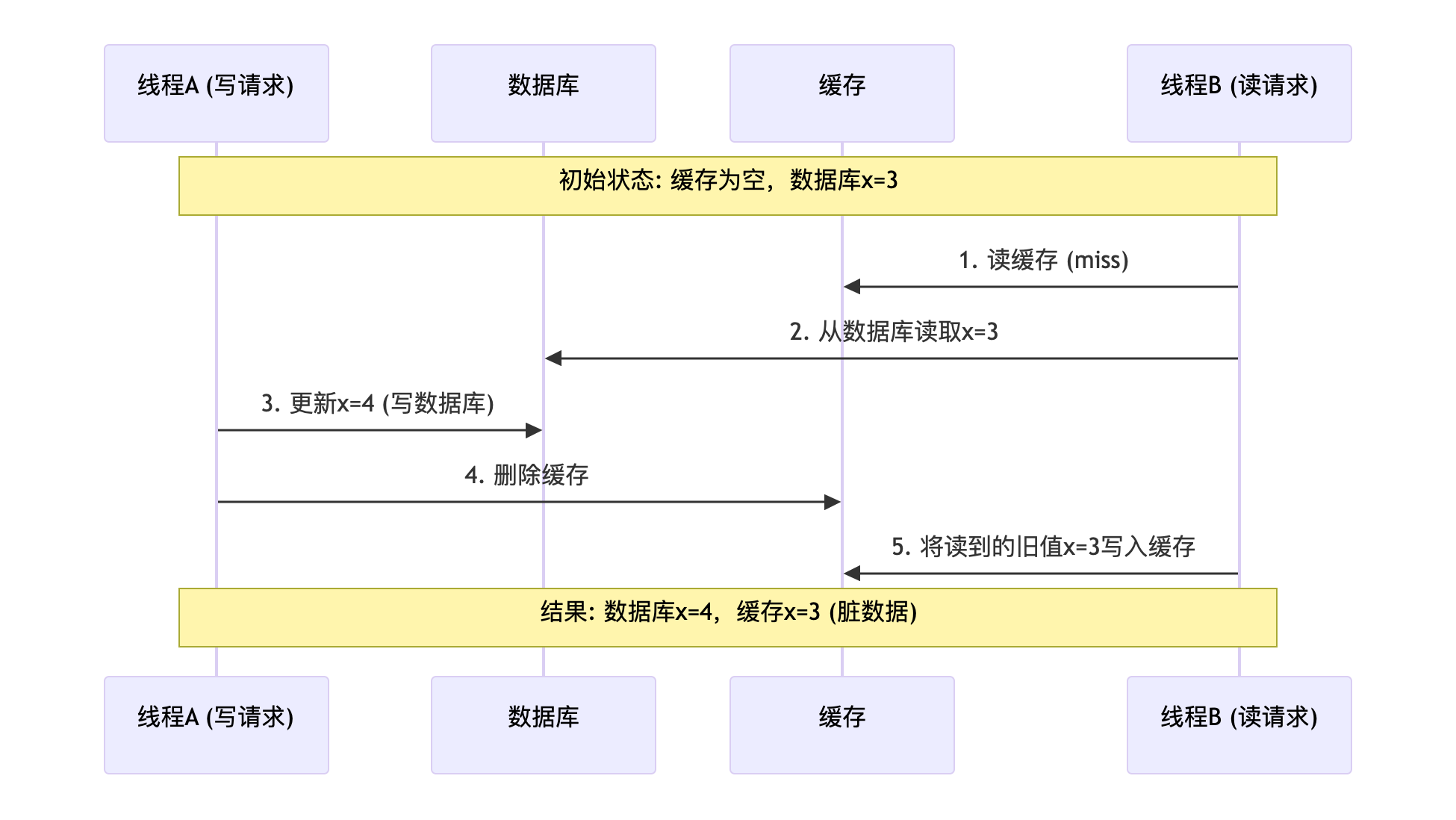
解决这个问题的方法:
为缓存设置过期时间(基本方案)
延迟双删,即写操作后进行两次删除缓存操作,一次立即执行,一次间隔一段时间执行,如500ms以等待可能并发的读操作完成(优化方案)
但是,通常来说,DB的读都比写执行快很多的,先到的读请求后于写请求完成的情况出现概率非常低,所以在工程上也是一个make sense的方案。
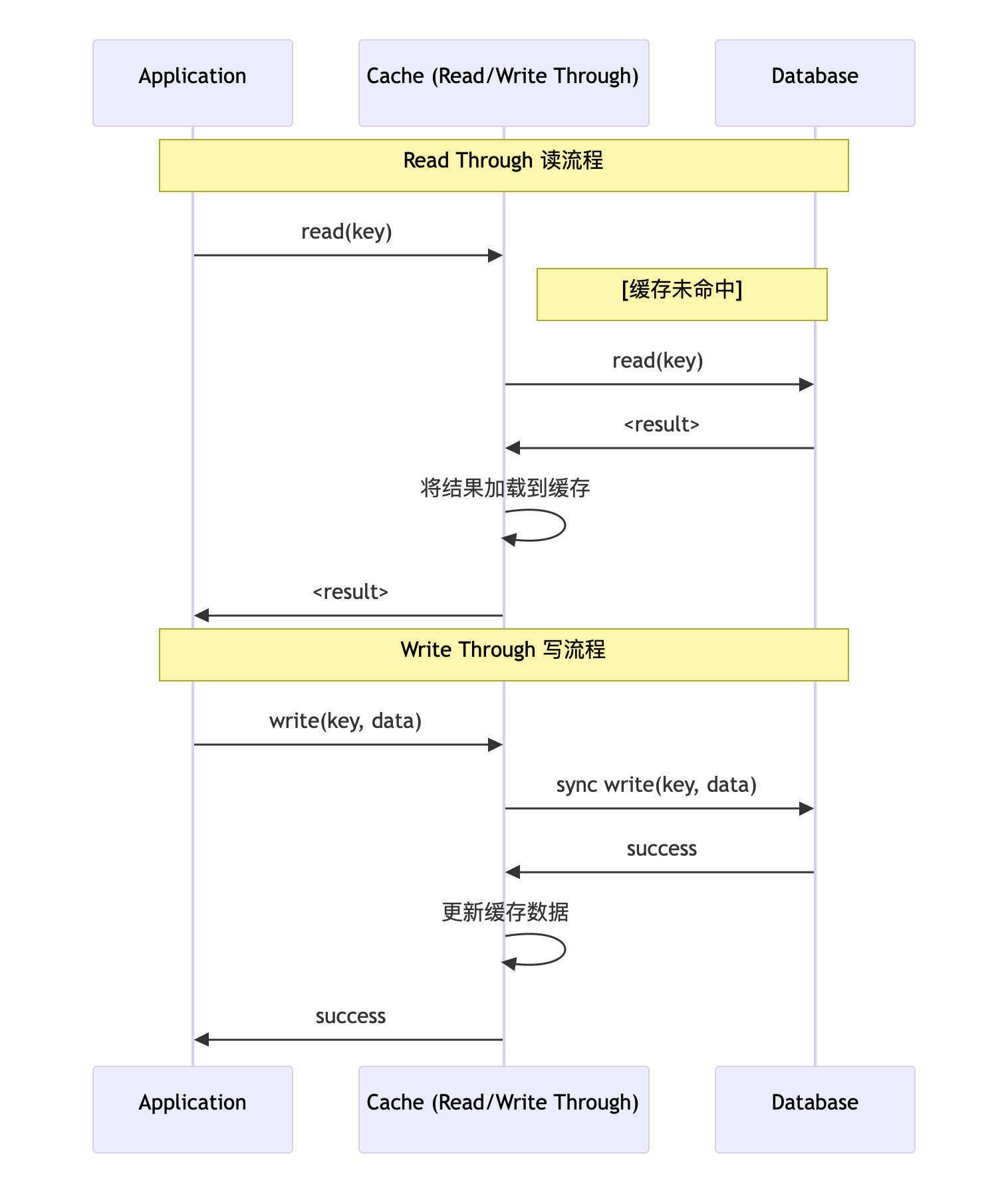
二、Write through/Read through
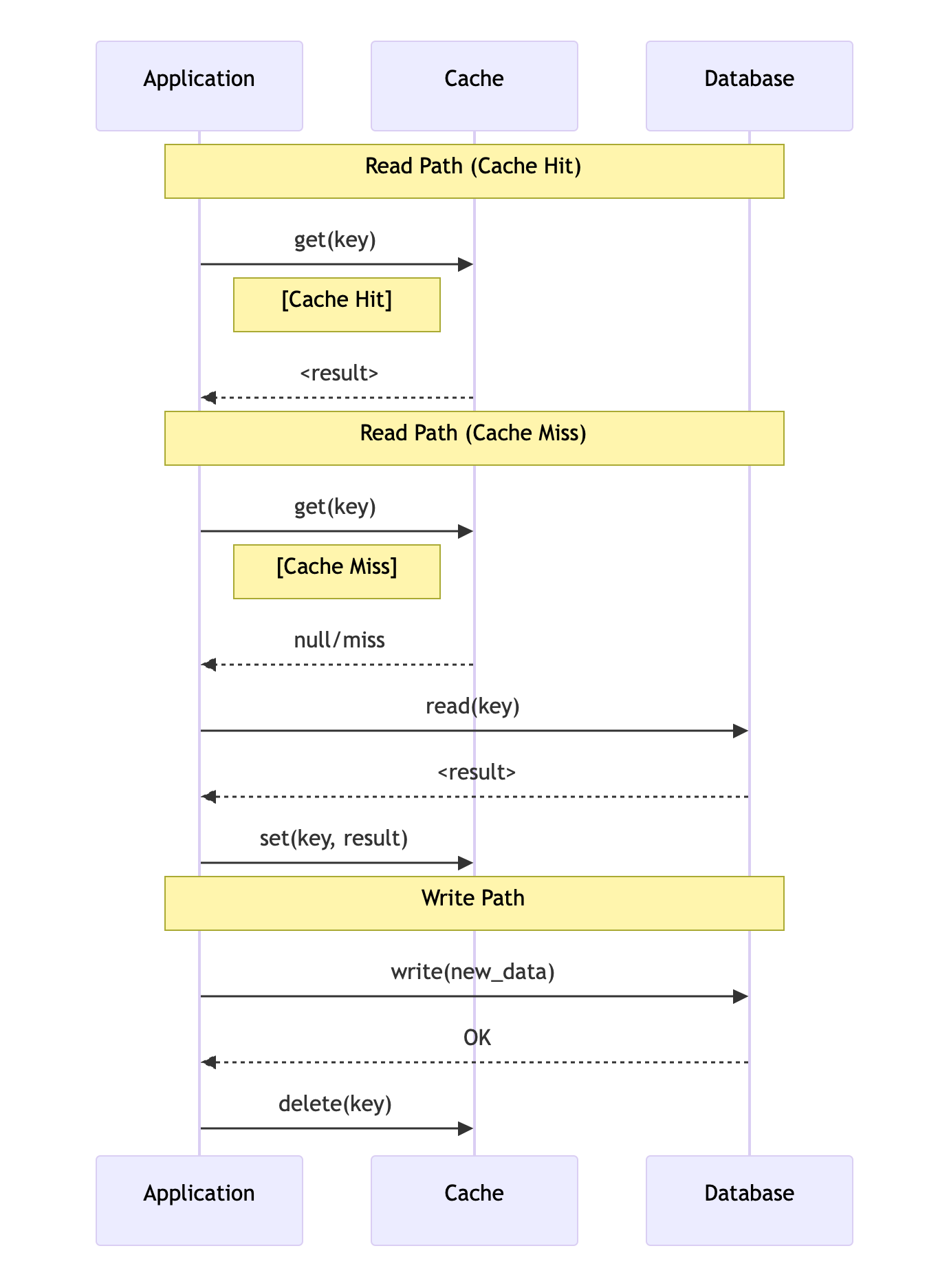
cache aside的实现,客户端需要做很繁杂的工作,与cache和DB都进行交互。Write through和read through可以简化这种操作。
它的cache与DB,cache与application交互,而application与DB不进行直接交互。数据写入cache时,cache同步写到DB。
读cache时,cache如果miss,会自动请求DB,将结果装载到cache并返回。但这样虽然简化了application的代码,也有一些问题。cache aside的cache是不需要有schema的,但write/read through要负责更新和读取DB,因此需要cache的数据拥有schema,没有cache aside那么灵活(比如只想cache某几个字段)
write/read through的时序图如下:
三、Write back
write back比较简单,跟write through的区别是不需要同步写DB,从而实现异步batch写DB来提升吞吐,适合于write heavy场景。
write back的时序图如下: