MyBlog
【课程笔记】CS 144: Introduction to Computer Networking
last modified: 2023-01-05 18:57
Princeples
网络设计,遵循了最基本的3个原则。
Packet Switching, Layering和Encapsulation是网络运行的本质。
Packet Switching
网络抽象为:end-hosts, switch, link
Packet hop-by-hop的,通过link在end-host->switch,switch->switch之间传输。
Packet 是自包含的一个结构,由data和header组成,header中包含了packet进行转发所需要的全部信息。Switch的职责是根据header中的信息,进行转发,它不关心flow,不知道flow的拓扑,不关心flow的状态。这是网络设计的关键。
Layering
为什么需要layering?
1. 良好定义的API,下层给上层提供服务,上层调用下层。很好的屏蔽了细节,每层只做它concern的工作
2. 每层的能力复用
3. 独立升级,而不影响其它层的功能
Internet的Layering具体:Link,Network,Transport,Application
Link: Switch工作在这里
Network: IP(Internet Protocol), Router工作在Network层,它与Switch general的工作原理相同,说它是Switch也没什么问题
Transport: TCP协议(Connection, Flow control, Congestion control)
Encapsulation
Link: frame
Network: [IP]datagram
1. Best effort deliver
2. 不关心数据是否:重复,丢失,损坏
Layering的好处在这里有所体现,因为有的网络应用中,比如直播中丢掉的帧再重传没有任何意义,Network层则保留了这种可能性。
Transport: [TCP]segment
Application: packet
A Bit of History
- 1974: 3-way handshake
- 1978: TCP and IP split into TCP/IP
- 1983: January 1, ARPAnet switches to TCP/IP
- 1986: Internet begins to suffer congestion collapses
- 1987-8: Van Jacobson fixes TCP, publishes seminal paper (Tahoe)
- 1990: Fast recovery and fast retransmit added (Reno)
TCP可靠性保证
TCP在不可靠的IP层之上提供可靠的字节流传输,核心机制包括:
1. 序列号(Sequence Number)与确认机制(ACK)
- 每个字节都有序列号,TCP segment的seq number标识该segment中第一个字节的序号
- ACK number表示期望接收的下一个字节序号(累积确认)
- 通过seq/ack机制检测:丢包、重复、乱序
2. 超时重传(Timeout Retransmission)
- 发送segment后启动定时器,超时未收到ACK则重传
- 超时时间基于RTT动态计算(EWMA算法,见后续RTT Estimation章节)
- 这是TCP可靠性的根本保障机制
3. 校验和(Checksum)
- TCP header包含16位校验和,覆盖header + data + 伪首部
- 接收方验证数据完整性,检测传输过程中的bit错误
- 校验失败则丢弃segment,等待超时重传
4. 顺序交付(In-Order Delivery)
- 接收方缓存乱序到达的segment,按序交付给应用层
- 保证应用层看到的是正确顺序的字节流
以上机制配合Flow Control和Congestion Control,共同实现了TCP的可靠传输。
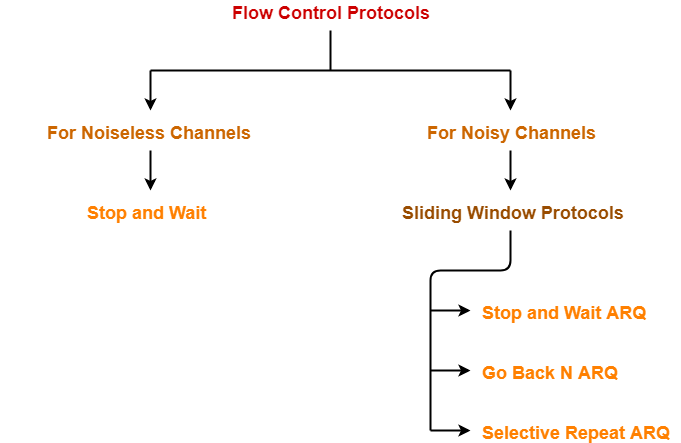
Flow control
TCP的流控机制很简单,简要说就是Sliding Window + Go Back N retransmission + Timeout Timer + Sequence Number。这里分析下其设计思路。
Stop and Wait
理想的信道中(Noiseless Channels),Frame在其上的传输不会出现:丢失、重复和损坏的情况。在Noiseless Channels传输数据,Stop and Wait即可。
具体步骤是:
- Sender发送Data Packet
- Data Packet到达Receiver端,Receiver处理完成后发送Acknowledgement Packet
- Acknowledgement Packet到达Sender端,Sender处理之
- Sender发送下一个Data Packet
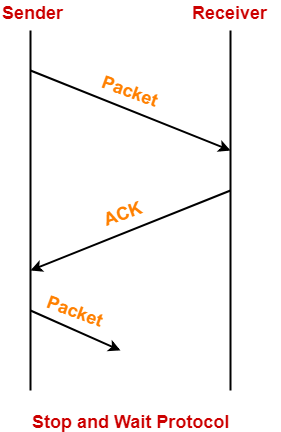
Stop and Wait协议很简单,因此也存在一些问题:
- Efficiency问题。因为每次只有一个inflight的packet,它不能完全利用Link
- Data Packet可能丢失、损坏,它处理不了
- Acknowledgement Packet可能丢失,它亦处理不了
Stop and Wait ARQ(Automatic Repeat Request)
ARQ是在不可靠的信道上可靠传输数据的一种机制。它解决了 Packet 丢失、损坏的问题,但没有解决 Efficiency 的问题
Stop and Wait ARQ 在 Stop and Wait协议的基础上,引入了Timeout Timer,Sequence Numbers for Data Packets和Sequence Numbers for Acknowledgement Packet三个工具,来解决上述问题。
下面分别讨论4个问题:
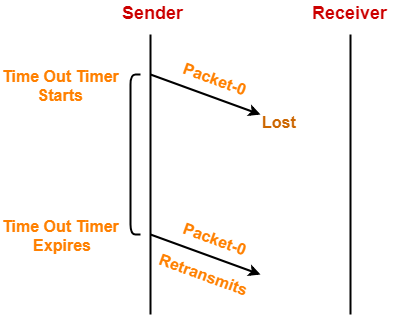
- Data Packet 丢失
Data Packet-0丢失,Sender 在timeout后重发Data Packet-0即可。
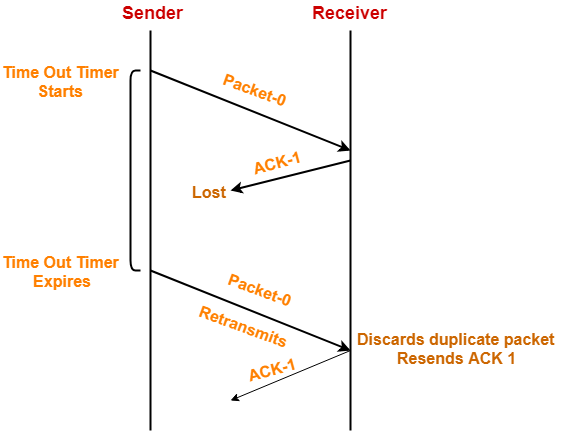
- Acknowledgement Packet 丢失
Data Packet-0的Acknowledgement丢失,则timeout后,Sender重发Data Packet-0,Receiver收到后,通过seq number发现包重复,则忽略该Data Packet并重发ACK-1的Acknowledgement Packet。
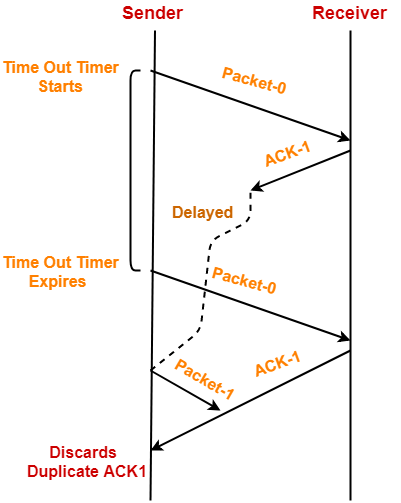
- Acknowledgement Packet 延迟到达
Sender接收ACK超时,重发Data Packet-1,Receiver收到后,通过seq number发现包重复,则忽略该Data Packet并重发ACK-1的Acknowledgement Packet。则Sender会先后收到2个ACK-1包。忽略第二个即可。
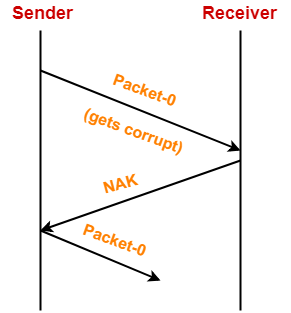
- Packet 损坏
Receiver检测到包损坏,则ACK给Sender一个 NAK包(negative acknowledgement),Sender重发Data Packet。
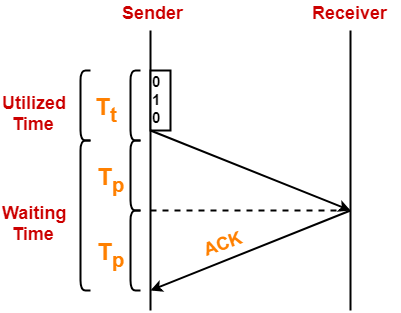
看一下Stop and Wait ARQ的效率问题。
Tt表示Transmission delay,Tp表示Propagation delay。
我们忽略Queuing delay和Processing delay。可以看到,因为stop and wait,2*Tp的时间是浪费的,该段时间Sender和Receiver不做任何事情。(由于Acknowledgement Packet比较小,我们忽略其Tt)
量化一下这个问题。
假设:带宽1.5 Mbps,RTT 为 45ms,数据包大小为1KB,Link利用效率为多少?
Tt = 1KB/1.5 Mbps = 5.461ms
Tp = Round Trip Time / 2 = 22.5ms
利用效率 = Tt/(Tt+2Tp) = 10.8%
Efficiency (η) = Useful Time / Total Time
- Useful time = Transmission delay of data packet = (Transmission delay)packet
- Useless time = Time for which sender is forced to wait and do nothing = 2 x Propagation delay
- Total time = Useful time + Useless time
Sliding Window - Go Back N Protocol
通过ARQ的一些机制,已经解决了Noisy 信道的问题。下面是Efficiency的问题。
Sliding Window的定义:
- 它是一种流控协议
- 它允许Sender在收到ACK前发送多个frames(Window框住的)
- Sender每收到ACK,就向前滑动其Window。这让其可继续发送更多frames
其实Stop and Wait ARQ也是一种特殊的Sliding Window协议,它的Sender Window为1.
结合Efficiency的计算公式:
Efficiency (η) = Useful Time / Total Time
= Tt /(Tt+2Tp)
如果要得到100%的Efficiency,则需要:
Tt / (Tt+2Tp) = 100%
则: Tt = Tt+2Tp
因此:
- 传输delay必须是Tt+2Tp,而非Tt
- 这意味着,在Waiting 时间内,也要发送frames(而Sliding Window正是干这个的,不需要Waiting发送更多的frames)
那在Tt+2Tp时间内,最多可发送多少frames呢?
Tt可以发送1个frame,则在Tt+2Tp时间内,可发送(Tt+2Tp)/Tt 个frames
使Tp/Tt = a,则为:1+2a个frames.
因此为达到100% 的Efficiency,Sender Window是1+2a。
再看一下Stop and Wait ARQ的Efficiency计算,因为其Sliding Window是1,而最大Efficiency的Sender Window是1+2a,则其效率为:
1/(1+2a) 与上面的公式一致。
Go Back N协议是一种Sliding Window协议,它的Sender Window为N,Receiver Window 为1.
Receiver使用cumulative ack的机制,即每收到一个按序到达的Data Packet,就立即发送ACK,确认序号为期望接收的下一个Data Packet的Seq Number。Receiver不缓存乱序到达的包,只维护一个期望接收的Seq Number。
当Receiver收到损坏或乱序的Data Packet后,会静默忽略掉(即不发送negative acknowledgement (NACK))。它不能接收乱序的Data Packet,因为Receiver Window只有1.
当Receiver忽略掉Data Packet,则Sender会收不到该Packet的ACK,这时它重传该Packet以及该Window后面全部的Packet。(仍是因为Window为1,如果一个Packet损失或丢失或乱序,都会导致Seq Number不能前推,后面的Packet都处理不了)
这是该协议Go Back N命名的原因。
Go Back N的Efficiency为:N/(1+2a)。当丢包严重时,因为要重传整个Widnow,它的带宽浪费很严重。
Sliding Window - Selective Repeat(SR) Protocol
SR协议一些关键点:
- Sender Window = Receiver Window(因此允许乱序的Packet,Receiver端会进行排序)
- 它只使用independent acknowledgements(与Go Back N累积的ACK不同,因为单个Packet的ACK,重传时也就不需要Go Back N了)
- 损坏的Packet,Receiver会发送NACK包(而不是静默处理,这与Go Back N协议不同)
- 因为Receiver可以接收乱序的Packet,并且损坏的Pakcet也会有NACK,并且每个Data Packet都有单独的ACK。所以对于丢失的包,得Sender端来搜索并重传丢的包。这是Selective Repeat 命名的原因。
SR协议的Efficiency也是N/(1+2a)。
相较来说SR是更好的协议,但是它的实现很复杂,因此实际使用的较少,Go Back N的应用更多。
Congestion control
Congestion在Packet Switching的系统中,是重要且无法避免的问题,Congestion会导致Packet丢失。
AIMD 是一种通用的feedback control算法,TCP congestion control是其应用之一。
Congestion control指TCP中如何解决Congestion的问题,其方法是:
减少Sender Window Size
Sender Window Size由两个因素决定:
1. Receiver window size
2. Congestion window size
1. Receiver window size
Receiver window size is an advertisement of- "How much data (in bytes) the receiver can receive without acknowledgement?"
Sender发送的数据不能超过Receiver window size,否则会导致数据丢失并引起TCP重传。
Receiver通过TCP Header告知Sender其window size。
2. Congestion window size
Sender发送的数据不能超过Congestion window size,否则会导致数据丢失并引起TCP重传。
Congestion window size只有Sender知道,它不通过网络传递。Sender可以使用不同的方法计算Congestion window size。比如通过超时,重复ack以及Google的BBR算法等。
因此
Sender window size = Minimum (Receiver window size, Congestion window size)
TCP Congestion Policy
TCP进行Congestion控制的策略由3个阶段组成。
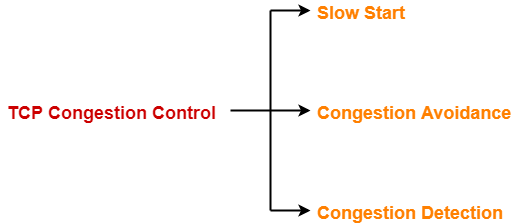
1. Slow start阶段
- 首先,Sender设置congestion window size = Maximum Segment Size (1 MSS)
- 每收到一个ACK,congestion window size增大一个1 MSS,这个阶段,size指数增长。
计算公式为:
Congestion window size = Congestion window size + Maximum segment size
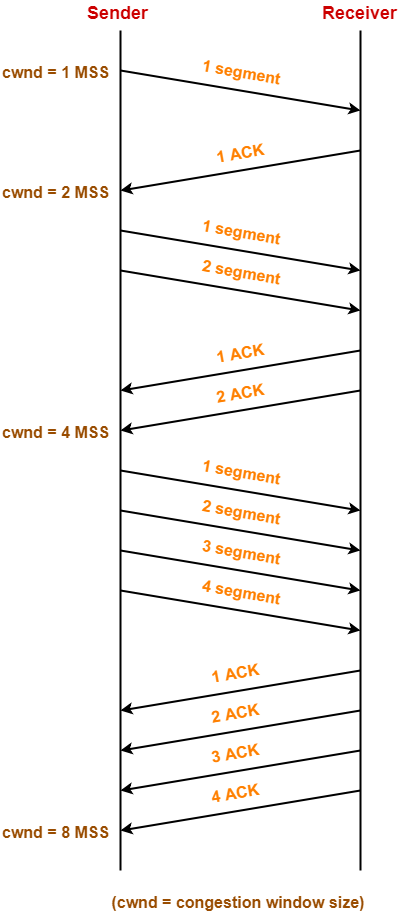
Slow start直到Congestion window size达到慢启动阈值。
Threshold = Maximum number of TCP segments that receiver window can accommodate / 2
= (Receiver window size / Maximum Segment Size) / 2
2. Congestion Avoidance阶段
达到Slow start阈值后,window size变为线性增长。拥塞避免阶段每收到一个ACK,congestion window size增加约 1/cwnd 个MSS,即每经过一个RTT(收到一个窗口的所有ACK),congestion window size增加1个MSS。
计算公式为:
Congestion window size = Congestion window size + MSS * (MSS / Congestion window size)
当Congestion window size长到receiver window size时,停止。
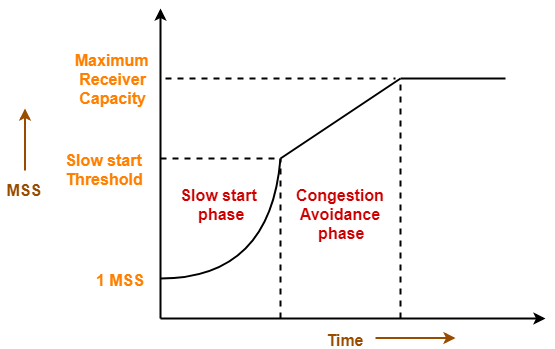
3. Congestion Detection阶段
TCP协议中,根据Congestion方法的不同,有不同的处理方式。具体的:
3.1 通过Timer Timeout检测(TCP Tahoe/Reno/RenoNew)
!!!重要:在TCP Tahoe中,timeout与triple duplicate ACK的处理一样,都是这里描述的timeout处理方式。
超时发生时,很大概率是网络Congestion。(也可能是其它原因导致的Packet丢失,但Congestion是最主要的原因)
TCP的处理方式是:
- 将当前congestion window size的Slow start阈值减半
- 将congestion window size 减为1MSS
- 回到Slow start阶段
3.2 通过收到triple duplicate ACK检测(TCP Reno)
检测到同一个Segment的3个重复ack,小概率是Congestion发生了。另外也可能是该Segment丢失了,但后续的segment正常到达。
为什么是triple duplicate ACK?
丢包和乱序都肯定会造成重复ack的,不管几次,强调这个意义不大。重点还是n个重复ack代表丢包的概率。
3次重复ack很有可能是丢包导致的。这是个经验的值。(丢包肯定会造成三次duplicated ACK!)
四次、五次太慢了,三次的时候丢包的概率就已经很大了,可以直接重传。
TCP的处理方式是:
- 将当前congestion window size的Slow start阈值减半
- 将congestion window size 设置为Slow start阈值
- 回到Congestion Avoidance阶段
3.3 Google BBR算法
BBR (Bottleneck Bandwidth and Round-trip propagation time) 是Google开发的拥塞控制算法,与3.1、3.2的核心区别在于:
传统方法(3.1⁄3.2)的问题:
- 基于丢包(packet loss)来判断拥塞
- 被动反应:必须等到丢包发生才降速
- 在高带宽长延迟网络中表现不佳(需要填满buffer才能达到高带宽,但填满buffer会导致高延迟)
BBR的核心思想:
不依赖丢包信号,而是主动测量网络的两个关键参数:
- BtlBw(Bottleneck Bandwidth):瓶颈链路的带宽
- RTprop(Round-trip propagation time):最小往返传播时延
理想工作点:
发送速率 = BtlBw,且inflight数据量 = BtlBw × RTprop
工作机制:
BBR通过两个探测阶段循环工作:
- ProbeBW(探测带宽):周期性地略微增加发送速率来探测带宽是否增加
- ProbeRTT(探测RTT):周期性地降低inflight数据量来测量真实的最小RTT
这种方式让BBR能在高吞吐和低延迟之间取得更好的平衡,特别适合高带宽长延迟网络(如跨洲际光纤)。
TCP性能优化技术
除了拥塞控制算法本身的演进,TCP还引入了多项性能优化技术:
1. 快速重传(Fast Retransmit)
问题: 依赖超时重传延迟较高(通常数百毫秒到数秒)。
解决:
- 收到3个重复ACK(triple duplicate ACK)立即重传,无需等待超时
- 原理:接收方收到乱序包会立即发送重复ACK,3个重复ACK强烈暗示丢包
- 显著降低重传延迟(通常几十毫秒内完成重传)
- 注意:这只是性能优化,超时重传才是可靠性的根本保障
2. 选择性确认(SACK - Selective Acknowledgment)[RFC-2018]
问题: Go Back N机制下,一个包丢失会导致整个窗口重传,浪费带宽。
解决:
- 在TCP Options中携带SACK信息,告知发送方哪些segment已收到
- 发送方只重传真正丢失的segment,而非整个窗口
- 显著提升丢包场景下的性能
3. 窗口缩放(Window Scaling)[RFC-7323]
问题: TCP header的window size字段只有16位,最大65535字节,在高带宽长延迟网络中不够用。
解决:
- 在连接建立时通过TCP Options协商缩放因子(scale factor)
- 实际窗口大小 = header中的值 × 2^scale
- 最大可支持1GB的接收窗口
4. Nagle算法
问题: 应用层频繁发送小数据包(如telnet每按一个键发一个包),造成大量小包,header开销大,网络效率低。
解决:
- 如果有未确认的数据,缓存小数据包直到:
- 累积到MSS大小,或
- 收到之前数据的ACK
- 减少小包数量,提升网络利用率
- 可通过TCP_NODELAY选项禁用(低延迟场景如游戏)
5. 延迟确认(Delayed ACK)[RFC-1122]
问题: 每收到一个segment就立即发送ACK,ACK包过多。
解决:
- 延迟最多200ms或收到2个segment后再发送ACK
- 减少ACK包数量(约减少50%)
- 如果延迟期间有数据要发送,可捎带ACK(piggybacking)
6. TCP Fast Open(TFO)[RFC-7413]
问题: 3次握手增加1个RTT延迟,对短连接影响大。
解决:
- 首次连接时服务器生成cookie
- 后续连接在SYN包中携带cookie和数据
- 服务器验证cookie后可立即处理数据,无需等待握手完成
- 减少1个RTT的建立时间
7. TCP NewReno [RFC-3782]
NewReno改进了Reno的快速恢复阶段:
- Timeout与TCP Tahoe/Reno一致
- triple duplicate ACK进入快速恢复阶段:
- 记录进入快速恢复时最后一个未确认的包
- 每收到一个重复ACK,临时扩大cwnd一个MSS(允许发新数据)
- 当最后的包被确认,返回拥塞避免阶段,恢复cwnd
- 解决了Reno在单个窗口多个包丢失时性能下降的问题
一份文档:Congestion Control overview
Connection
TCP state diagram
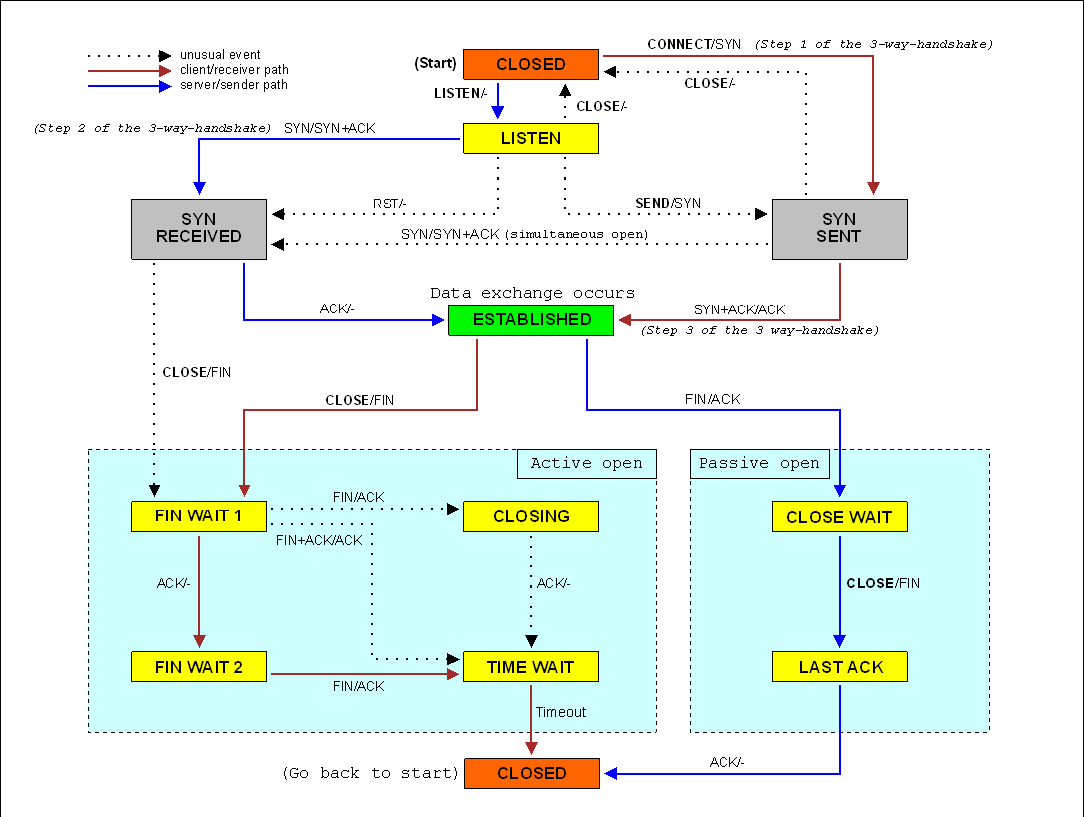
Connection establishment
TCP是个全双工的协议,因此要双向建立连接,连接建立的工作其实是做一些TCP协议参数的通知,具体的(Server和Client互相告诉对方):
- 自己的Receiver window size(双方都作为Receiver)
- 自己的MSS
- Sequence Number(各自随机生成)

在TCP segment中:
- 如果 SYN bit = 1 且 ACK bit = 0,那这是一个 request segment
- 如果 SYN bit = 1 且 ACK bit = 1, 这是一个 reply segment
- 如果 SYN bit = 0 且 ACK bit = 1, 它是一个pure ACK 或 data segment
- 如果 SYN bit = 0 且 ACK bit = 0, oops,这个组合不存在
需要特殊说明的是,前两步双工的连接已经建立好,第三步Pure ack并不是必须的,它可以与Data segment 一起发送。
Connection teardown
因为Connection是全双工的,连接的关闭也需要双向。
Client->Server方向关闭阶段
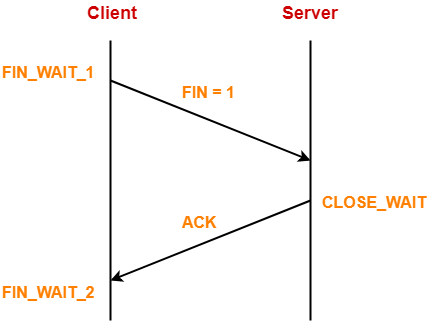
主动关闭方(这里我们称为Client)发送FIN(set FIN bit to 1),Server收到FIN,释放buffer,发送ack后进入CLOSE_WAIT状态。
Client收到ack进入FIN_WAIT_2状态。
这个阶段,Client->Server方向的连接已经关闭了,因为Server已经释放buffer,Client不能再发送data(但还可以发送ack)
Server->Client方向的连接未关闭,因此Server还可以向Client发送data或ack。
Server->Client方向关闭阶段
接下来关闭Server->Client方向的连接,Server发送一个FIN包(也可以与前面的ack一起发送)
Client收到FIN后,释放buffer,ack并进入TIME_WAIT状态。
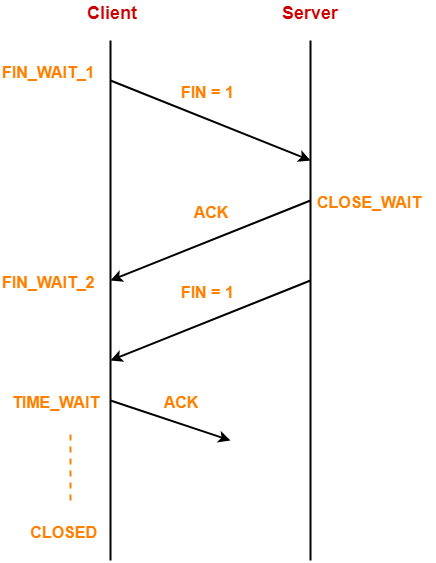
这个过程有什么问题?
- 如果Client最后的ack在网络中丢失了怎么办?(Server会重发FIN)
- 如果新的connection使用了相同的port pair怎么办?
解决方案:主动关闭的一方进入TIME_WAIT状态,保证连接继续存活2MSL (2倍的 “maximum segment lifetime”)。
2MSL的原因: Client发的ack,经过1MSL到达Server(极限的假设,ack无限接近1MSL时丢了)。Server重发的FIN,经过1MSL到达Client,共2MSL
假设如果发送完ack,没有TIME_WAIT直接关闭,或者等待时间少于2MSL的话。如果Client和Server建立了一个新连接,恰好用了上面关闭的连接相同port pair,则Client会收到一个奇怪的报文(Server重发的FIN)。
但TIME_WAIT可能会导到Client端太多打开并等待在TIME_WAIT的连接。优化方法有2种:
- 设置SO_LINGER为0,直接发送RST报文关闭连接,这个过程不经过4次交互的teardown,也就没有TIME_WAIT状态问题
- 通过SO_REUSEADDR,禁止端口短时间重用
RTT Estimation and self-clocking
目前TCP Tahoe还有两个功能没有介绍,
1. RTT Estimation
RTT预测关系到Timeout timer的设置,如果Timeout时间偏大,则传输delay过大,表现的结果是网络delay高。
如果Timeout过小,则本来不需要重传的包被重传,导致带宽浪费。所以RTT预测值最好能等于每个Packet的实际传输值,但这是很难的。
因为对Packet Switching的系统来说,每个flow,每个Packet传输的当下条件都是不同的。
TCP Tahoe的RTT Estimation逻辑为EWMA(Exponentially Weighted Moving Average):
EstRTT = (1 − α) · EstRTT + α · SampleRTT
- Recommended α is 0.125
Dev(deviation)RTT = (1−β)·DevRTT + β · |SampleRTT −EstRTT|
- Recommended β is 0.25
Timeout is EstRTT + 4 · DevRTT
2. Self Clocking
Self Clocking机制简要来说即:send a data packet for each ack. 对于Thin pipeline,不将过多的Packet发送到网络上,在Sender端限流,避免congestion发生。
QUIC 协议
由于TCP协议内置在操作系统中,Linux的更新比较谨慎(缓慢),所以在网络环境发生变化时,一些新的更优的算法和特性不能被及时的引入。
QUIC是Google开发的基于UDP实现的可靠协议(类似KCP)。所以分析完TCP协议后,对比看下QUIC做了什么。
1. 解决TCP的Head-of-line Blocking问题
TCP的head-of-line blocking问题源于TCP是字节流协议。当某个TCP segment丢失时,即使后续的segment已经到达,应用层也无法读取这些数据,必须等待丢失segment的重传和按序交付。在多路复用场景(如HTTP/2),一个TCP连接承载多个逻辑流,某个流的一个包丢失会阻塞所有其他流。
QUIC的解决方式是在UDP之上实现了stream级别的多路复用,每个stream独立进行可靠传输和流控。QUIC使用单调递增的Packet Number标识每个数据包(重传时Packet Number也递增),并用Stream ID+Stream offset标识数据在stream中的位置。当某个stream的packet丢失时,只阻塞该stream,其他stream可以继续交付数据给应用层。
QUIC的这种设计复杂度较高,但通过在用户态实现避免了内核态的性能开销。
2. 减少Connection establishment的开销
连接的建立,就是交换一些参数的过程,比如MSS,Receiver Window Size,这些参数与操作系统配置相关而很少变化,如果之前建立过连接,则可以保存这些参数,通过一次协商完成参数确认。
TCP协议也提供了快速建立连接的方案:TFO (TCP Fast Open) [RFC-7413]
初次建立连接时以cookie形式保存参数,连接建立时带上,这样服务器验证ok后即可快速恢复连接。
3. TCP connection migration
在移动弱网环境下,经常发生4G到WIFI等的网络切换,网络切换会带来连接重建,这是TCP协议的4元组机制导致的。
如果不使用4元组,而有其它的设备的维一标志,即可避免连接重建的问题。
TCP为了保持向前兼容,不能重新设计连接标志(4元组),为了解决这个问题,它推出了MPTCP (Multipath TCP) [RFC-6824]
但跟TFO类似,因为操作系统更新慢的缘故未普及。
4. Congestion control改进
QUIC优化的主要是网络delay问题。
delay问题产生的原因,主要源于:
- Packet的超时重传
- Packet的丢失重传
4.1 RTT测算方法改进
对于超时,其实只要改进RTT Estimation测试准确度即可。可以从2个方面优化:
其一,由于Sender无法区分收到的ack是原始请求的ack,还是重传请求的ack,因此会影响RTT Estimation计算准确度。QUIC采用单向递增的Packet Number来标识Packet,原始请求的数据包与重传请求的Packet number不一样,采样RTT的测量更准确。
![]()
其二,QUIC计算RTT 时去掉了接收端的Processing delay,更准确的反映了网络往返时间,降低了数据包超时重传的概率。
![]()
4.2 通过带宽换低delay
对于Packet损坏或丢失问题,因为TCP中只有校验码,没有纠错码,如果出现数据损坏或丢失,只能重发该Packet。
而QUIC引入了FEC: Fowrard Error Correcting,它通过传输冗余的纠错码,当出现少量包丢失或损坏时,通过纠错码可直接在Receiver端恢复(类似于RAID-5),避免了重传。
这是一种通过增加带宽使用换取delay下降的方案。
4.3 Congestion control算法改进
QUIC即支持TCP的CUBIC(Slow start,Congestion Avoidance,Fast Retransmission,Fast Recovery),也通过插件式支持BBR等新算法。它的优势在于:
协议在应用层实现,随网络环境的优化,可以通过浏览器的更新而快速迭代更新Congestion control算法。这对内嵌在操作系统的TCP协议栈来说,是难以达到的。
Paper:”CUBIC: A New TCP-Friendly High-Speed TCP Variant”, ACM SIGOPS Operating System Review , 2008.