MyBlog
【课程笔记】CMU 15-445⁄645: Intro to Database Systems
last modified: 2023-01-09 20:35
把数据库,从大的方面分为两个部分,可以称为内部和外在。
其外在是与用户和业务交互相关的部分,有,
- SQL(解析、优化、执行等)
- 数据模型(关系等模型)
内部部分有,
- 数据怎么存的(涉及到数据文件在block设备上如何组织)
- 数据怎么检索的(涉及到索引,及索引文件在block设备上如何组织)
- 数据的Partition、Replication实现(分布式关注的问题)
- Transaction(AICD)
这份总结只涉及内部,不涉及外在。
数据文件存储
数据文件存储,主要关注的问题是,field在record中怎么存储(field就是一个字段,record就是row),record在文件中怎么存储。
但计算机中,不管HDD还是SSD用的都是块存储设备,操作系统提供的读写磁盘的最小单位是block,文件实际是由一个个的block构成。
所以record在文件中怎么存储,要看的是record在block中的存储。
field在record中的存储
field有定长(如long)和变长(如varchar),对于record全部field都是定长的情况,只需要根据字段类型的元数据,可以直接定位到field。
对于变长的情况,可以记录各field的offset和size,变长的内容本身放到record的尾部,同样可以直接定位。
变长record的存储示例:
Bytes 0-4的内容表示,offset为21,长度为5,即field:10111,
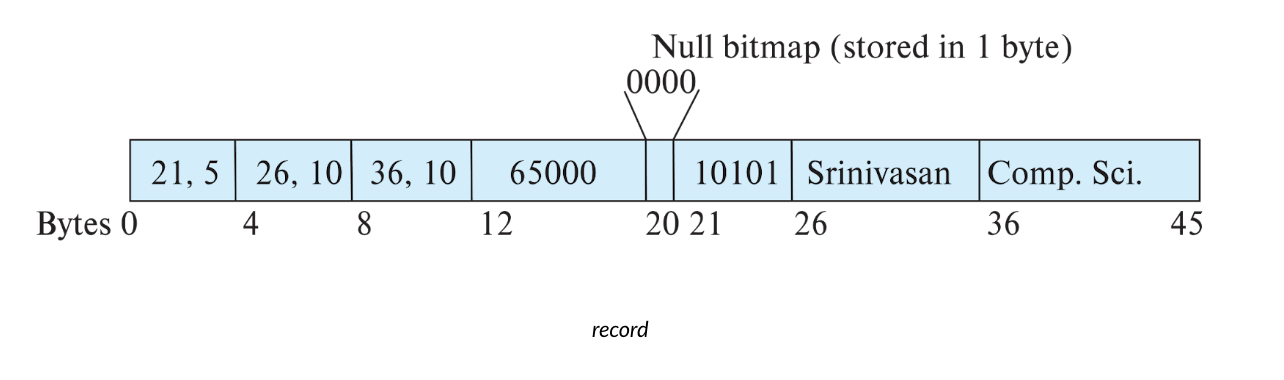
record在block中的存储
fields全部为定长的record,record本身也是定长。所以根据block_id和record size就可以遍历截取数据。
对于含有变长fields的record,record长度亦不定,则需要一个特殊的结构来从block中取数据,这个结构叫 Slotted Page Structure
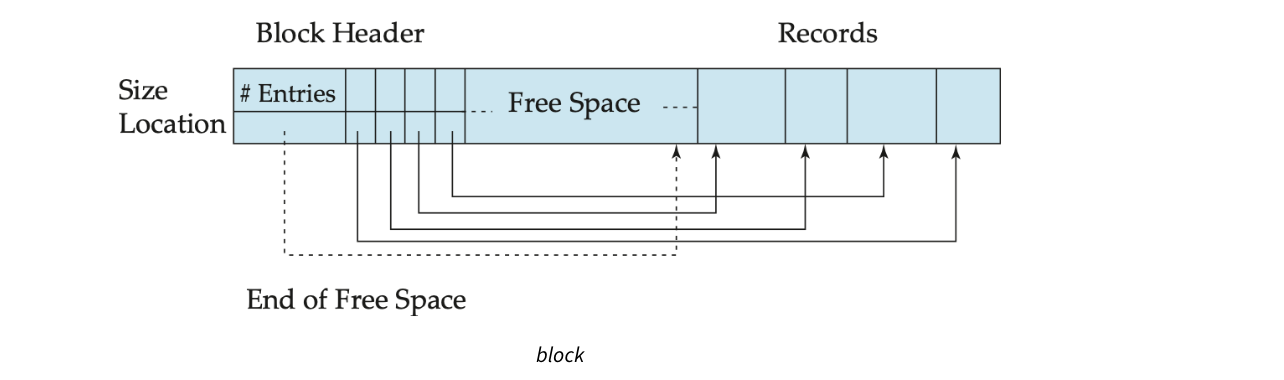
在Block header中存储Records在Block中的Index位置及长度,而records本身存在block尾部。
文件与block的关系
我们的数据库都是文件的形式存在,至于文件放在哪些block里面,这个信息是记录在inode中(linux),通过stat命令可以看inode的部分信息,比如下面nohup.out文件由56个block组成,block大小为4K:
:~# stat nohup.out
File: nohup.out
Size: 24023 Blocks: 56 IO Block: 4096 regular file
Device: fc01h/64513d Inode: 1310941 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2022-03-28 16:11:12.115055464 +0800
Modify: 2023-01-09 02:25:06.695382964 +0800
Change: 2023-01-09 02:25:06.695382964 +0800
Birth: -
列式存储
上述的record,指的是数据的行存,另外数据亦可以进行列存:同一列的数据在文件中聚集在一起。
列存是面向decision support来设计的(行存面向的是transaction processing),它比较适合大数据场景,因为大数据场景中经常需要做整列的SUM/DISTINCT等计算工作,列存下只需要读取部分列数据以减小I/O,并且列的数据类型都相同,可以为它选择更好的编码算法。
但本质上,列存的数据文件存储与行存相比,没什么特殊之处。
索引文件
如果没有索引,并且数据文件中的record是随机存储的,那么取想要的数据,只能通过遍历所有数据文件。而因为磁盘I/O慢的缘故,通过文件遍历来查找数据的效率是极低的。
如果希望快速检索数据,则需要为数据建立索引。这些索引列也叫:Search key。
Search key列的数据本身如果是按顺序排列的,则即可以建Dense索引,也可以建Sparse索引,Sparse索引只对部分record建立索引,但因为数据列本身有序,可以通过先使用Sparse索引进行初步定位,再局部遍历的方式取到数据。比如可以令每个block的数据一个索引,而不是一行一个索引。
有序列上的索引也称Clustering index(聚簇索引)。需要注意的是,Clustering index是指数据行按照该索引的顺序物理存储,而Primary index是主键索引。在InnoDB存储引擎中,主键索引就是聚簇索引,但在其他存储引擎(如MyISAM)中,主键索引也是非聚簇的。比如MySQL InnoDB的主键索引(AUTO_INCREMENT id)就是聚簇索引
下面讨论三种索引技术:
- 顺序索引(以B+树为例)
- hash索引
- Write-optimized索引(以LSM-Tree为例)
1. 顺序索引
顺序索引指,索引数据 按search key排序,以B+树为例,
假设以下表结构:
id, name, object, salary
若为name列建立顺序索引,B+树结构为,
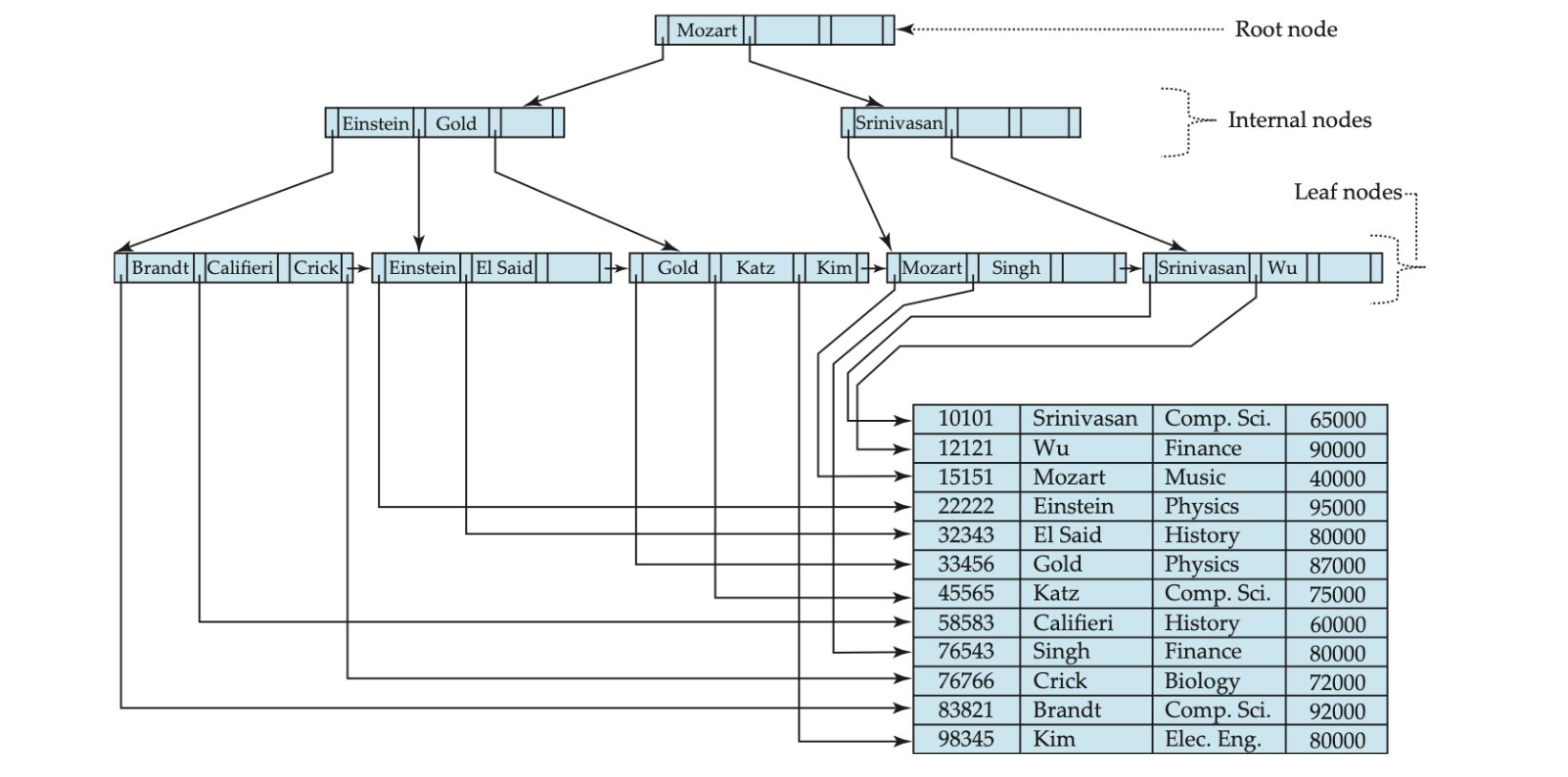
叶子节点存储name值,及name值对应的数据文件指针(block_id),亦或者是name对应的Primary id,再通过Primary index索引,定位到数据文件指针。
2. hash索引
相同hash值的search key,其在索引文件中聚集。表现在存储上,相同hash值的search key保存在相同block中,若block存满,则溢出到其它block中,这些block间拉链。
hash索引适合点查,不适合范围查找。
3. Write-optimized索引
LSM-Tree是为大数据量写入而优化的索引结构,它的变种在大数据领域应用广泛,如ClickHouse,HBase,TiDB等底层存储,均使用了LSM-Tree及其变种技术。
对其的详细分析: LSMTree compaction
Partition
有三种数据partition方式,
Round-robin partition
在数据库中很少使用,在Kafka等消息队列产品中使用比较多,因为其balance性最好,缺点是查询要访问所有partition,而MQ一般不提供查询功能,因此MQ使用场景下不算什么缺点。
Hash partition
优点是点查性能良好,缺点是range查询需要访问所有节点,效率较差。
Range partition
定义:
- Choose an attribute as the partition attribute
- A partition vector [vo, v1, …, vn-2] is chosen
- Let v be the partition attribute value of a tuple. Tuples such that vi <= vi+1 go to node i+1. Tuples with v < v0 go to node 0 and tuples with v >= vn-2 go to node n-1
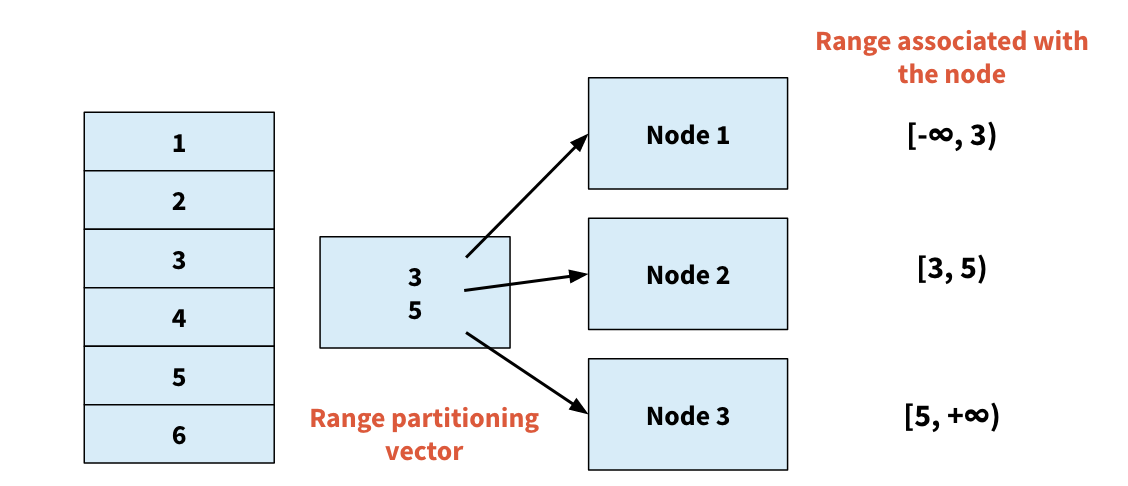
它的核心设施是range vector table,记录了节点与数据range之间的映射关系。
Range partition 的数据倾斜问题
但Range partition会面临由于Range vector table选择和维护不好,而导致的数据倾斜问题:一些range内的元素数多,一些range内的元素数少。因为range是放在节点的,就导致有的节点数据量多,有的节点数据量少,发生数据倾斜。
因为业务使用场景(比如用month做partition,某月的数据量特别大)、业务的不同周期(如按shop做partition,但某个shop突然大卖,其所在的range数据变多)出现倾斜。
解决这个问题的核心,是需要让Range vector table动态变化,满足业务数据的动态变化,确保每个range包含的数据条目动态平衡。
Range partition 的数据倾斜问题解决方案
解决Range partition的数据倾斜问题,有个组合方案,
- 虚拟节点(Virtual node)
- 动态re-partition(Dynamic re-partition)
虚拟节点的原理是将数据range到物理节点的关系,变为数据range到虚拟节点的关系,物理节点与虚拟节点是1:N,这样一个倾斜的数据range会分散到不同的虚拟节点。
虚拟节点(包括存储的数据)可以很方便的在物理节点间做迁移,从负载高的节点迁移到负载低的节点。如果数据range的数据量增长,可以增加物理节点,并将该range的部分虚拟节点迁移到新物理节点上,它实现了存储的弹性。
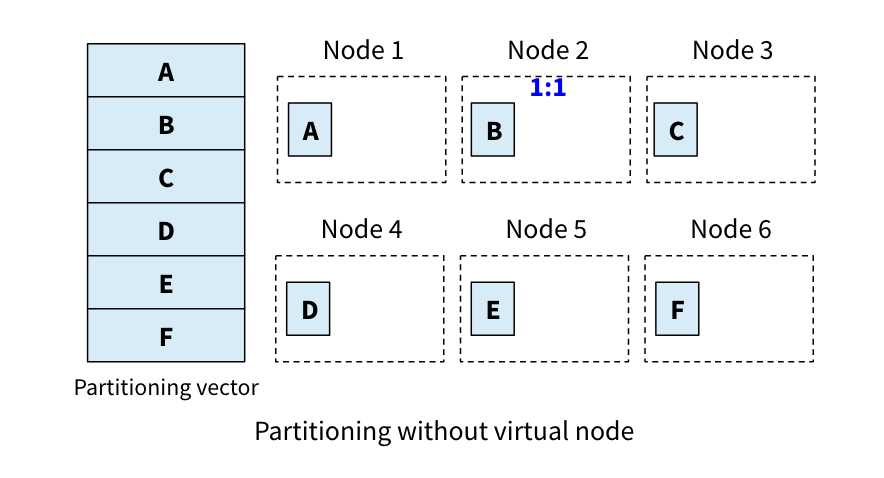
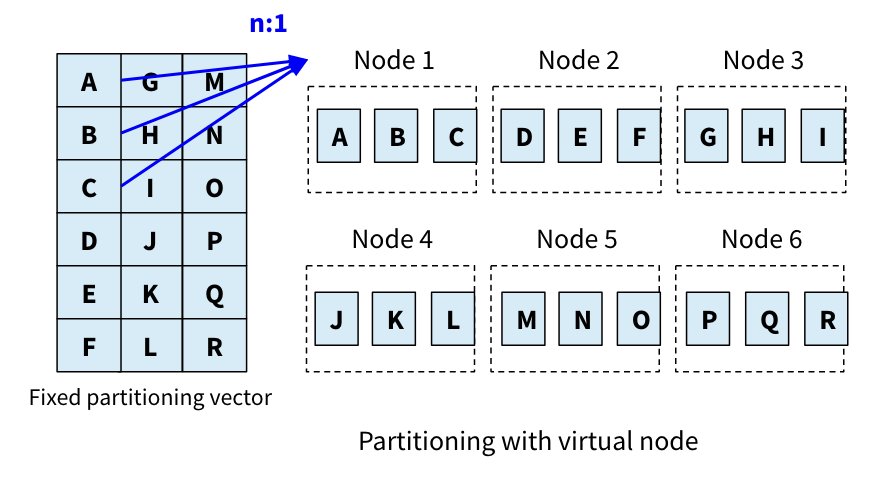
虚拟节点fixed partition vector的方式,解决不了range数据量随时间持续变化的问题,这个问题可以使用动态re-partition来解决。
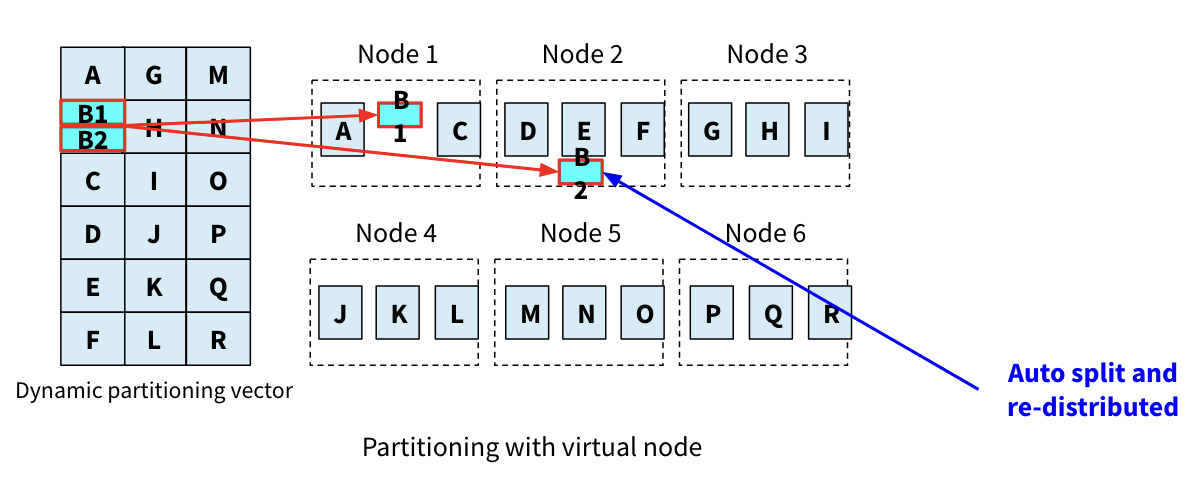
当virtual node增长到一定大小,可以split成2个新virtual node,其中一个virtual node即可以分布到其它负载较低的节点。(HBase里的auto split,这种场景下的virtual node也叫tablet)
Range partition 的数据访问
一个方案是Master模式,有专门的Router节点,它同步Master的Partition vector table信息。专门负责路由请求。
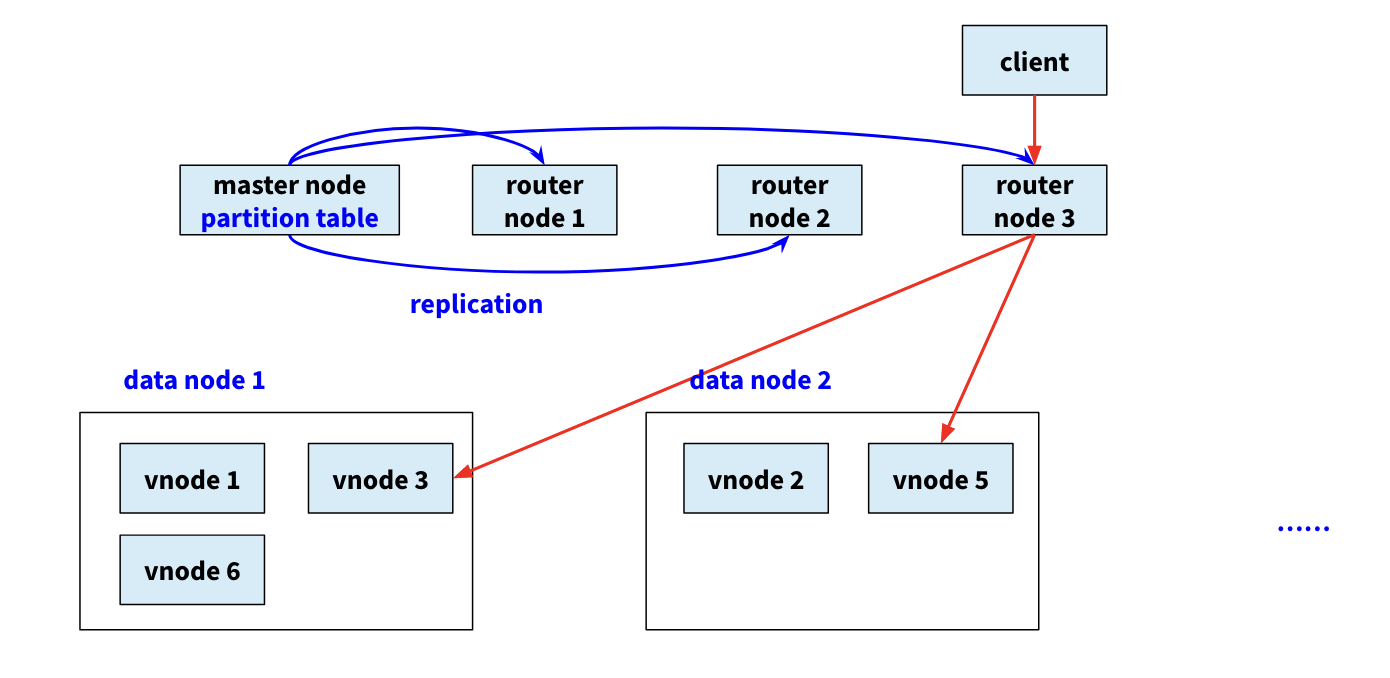
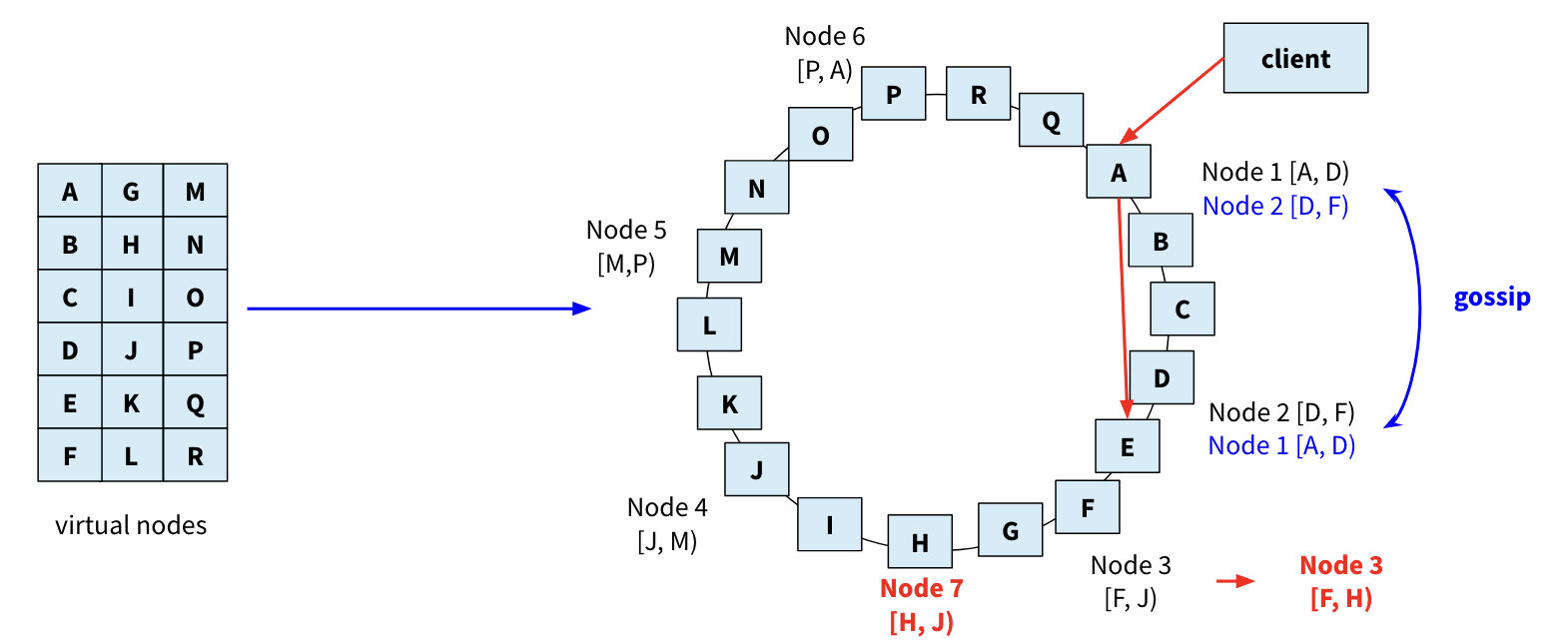
另一种是P2P方案,它没有Master节点,也没有Router节点。它使用的是Consistent hashing(一致性哈希)和DHT(Distributed Hash Table)技术,DHT基于Consistent hashing技术。
首先有一个环,环上分布了非常多的vnode(比如2的20次方个),数据通过一个hash函数分布到vnode上,物理节点通过另一个hash函数分布到环上。
每个物理节点负责存储逆时针方向的vnode上的数据。请求到达任意一个node(物理),该node称为这次请求的coordinater,它已经通过Gossip协议同步了Vector table信息:物理node所负责的vnode。
如:一个get操作,coordinater计算其hash得到其vnode,通过Vector table知道请求具体转发到哪个物理node。
数据Replication机制
这里讨论的Replication,不是record level的,而是上面讨论的partition level(range->partition->virtual node/tablet)。
Replication主要存在lost update,即数据一致性的问题,
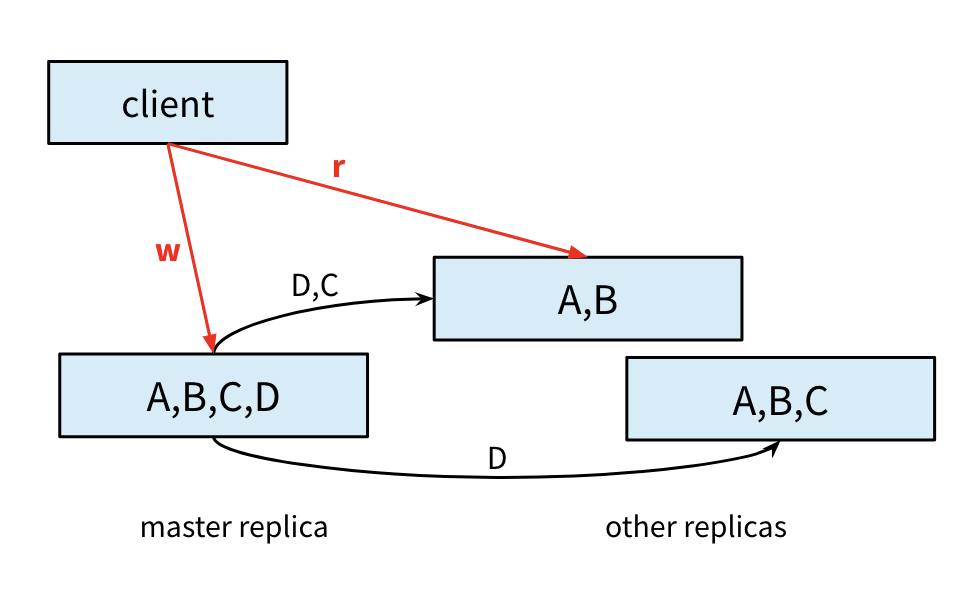
不同Replica数据的一致是我们的目标,Replica间的数据同步,我们通常使用,
- Master Schema(Primary copy)
- 2PC(两阶段提交)
- 可靠消息投递(Persistent messaging)
- 共识协议(如Raft)
- Quorum(区别是没有一个master/primary节点,replica写入由client负责完成)
2PC是分布式事务的经典解决方案,它本质是做多节点的原子提交(atomic commit protocol)。但如果把多节点的不同操作,都变成set x=y的相同赋值操作,也变相实现了数据同步的功能。需要注意的是,2PC存在blocking问题,在生产环境中需要谨慎使用,很多场景会采用最终一致性方案(如Saga、本地消息表)或TCC来替代。
Replication的实现在Transaction Replica稍详细总结。
Transaction
Transaction的目的是C,C除了一致性的解释以外,在这个场景下有个更贴近的描述:使数据库的数据恰如你预期。
举个例子:
张三李四原本分别有10元钱,张三给李四转账5元,当数据库告诉你转账成功后,则任何时机查询,张三都应该有5元,李四都应该有15元,SUM(张三,李四)都应该是20元。不会存在错误的状态,比如张三5元,李四仍10元。
Transaction的实现办法是A(Atomicity原子性)和D(持久性Durability)。A和D都保证了,也就实现了C。
A和D已经实现了C,但前提是,不同的Transaction都要One by one的串行执行,不存在并发执行的情况。串行带来了性能问题。要解决Transaction的性能问题,引入了Concurrency control机制,而Concurrency引起了I(Isolation)的问题。
Transaction之AD - Recovery system
数据库的Recovery子系统,负责实现A和D。要理解其实现,首先要理解不一致的问题出在哪里。如果我们有一个no failure的理想数据库,我们的每次写入原子且必然成功,就什么也不用做了,问题出在failure。
具体到数据的写入阶段:
- 操作系统的写入有缓存(Page Cache),write系统调用成功不代表数据落Disk了,程序crash数据丢了
- 数据写入过程不是原子的,可能会存在部分成功的状态(写入是block level的:如4K,但物理上中扇区level的:如512byte,如若写入过程中断电,则block处理部分写入,部分没写入的状态)。这种情况比较糟糕,我们要把写坏的那部分数据恢复到原来的样子。
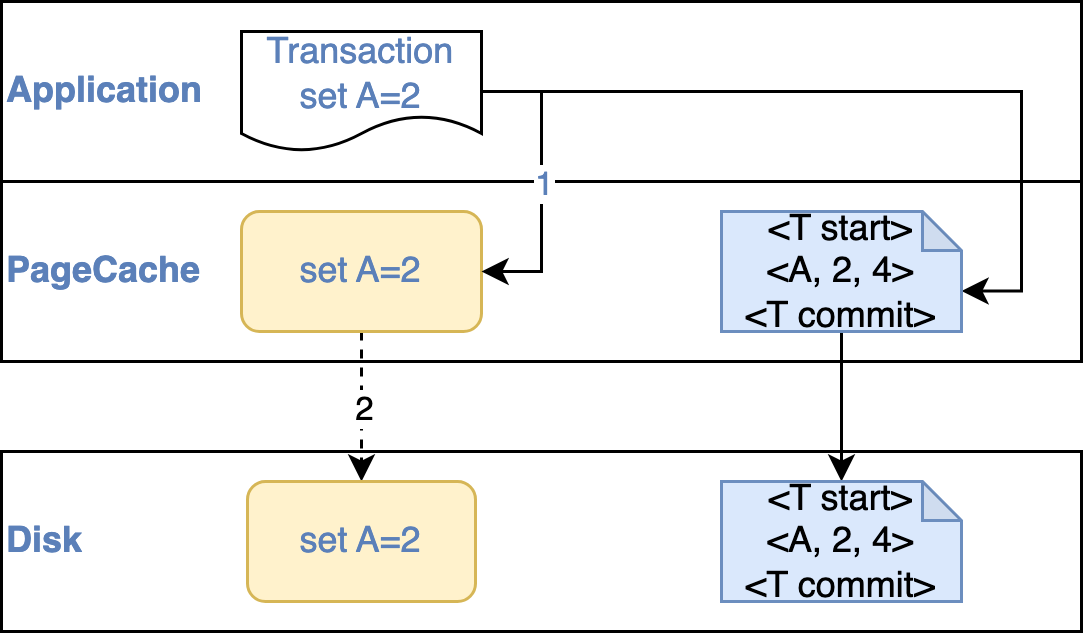
知道了问题,解决思路就比较简单,
- 首先我们设计一个log(日志),记录更新前数据是什么,更新后是什么,以便在失败后回滚(Rollback)
- 其次我们需要把这个log落地(例如执行fsync()系统调用)
比如,Transaction T中,B向A转账50,其transaction过程为:
<T start>
<T, A, 1000, 1050> - step2
<T, B, 1000, 950>
<T commit>
若log写到step2时系统fail了,
<T start>
<T, A, 1000, 1050>
Rollback的过程(Undo),
<T start>
<T, A, 1000, 1050>
<T, A, 1000> - 恢复A
<T abort> - transaction abort
Undo过程处理未完成的transaction,生成undo log,接下来执行Redo:将该transaction从start到abort重新执行一遍。
以上有这样一套log机制了。目前我们有数据和log两种文件,这两种文件的落地规则需要一定的约束,不然log未落地,但数据落地,系统fail恢复后会有脏数据等问题。
WAL(Write-ahead log)是这样一套规则,它约束了log与数据的落地过程,
- 数据文件落地前,其相应的log文件必须要先落盘(因为page cache的缘故)
- 一个transaction成功的标志,必须是其<T commit>或<T abort>log成功落盘
- <T commit>落盘时,T相关的其它log记录都必须已经落盘了
在WAL的前提下,我们来看下数据文件落盘的策略,
Steal policy
Transaction T commit前,若允许数据文件开始落盘(注意要遵守上面的WAL规则,这些数据更新的log已经落盘了),则称为steal policy,比起commit后才开始写数据文件,这有助于分散减小I/O压力。
No-force policy
如果Transaction T commit后,不要求数据文件立马落盘,则称为No-force policy,No-force policy允许数据文件在Transaction提交后慢慢写入,亦有助于分散I/O压力。
理想的,以及MySQL等默认的选择都是Steal+No-force policy。
Buffer Pool管理
Buffer Pool是数据库性能的关键,它是内存中的数据页缓存,用于减少磁盘I/O。
Buffer Pool结构
Buffer Pool由多个page组成,每个page通常为16KB(MySQL InnoDB默认值)。Page在内存中的组织包括:
- Free List:空闲page列表
- LRU List:使用LRU算法管理的page列表
- Flush List:脏页(dirty page)列表,需要刷盘的page
LRU变种:Midpoint Insertion Strategy
传统LRU存在的问题:
- 预读失效:预读的page可能不会被访问,却占据了Buffer Pool
- Buffer Pool污染:全表扫描会将大量page加载到Buffer Pool,淘汰掉热数据
MySQL InnoDB的解决方案:
将LRU list分为两部分:
- Young区(热数据区):约占5/8
- Old区(冷数据区):约占3/8
新读入的page首先放入Old区的头部(midpoint位置),只有在Old区停留时间超过阈值(默认1秒)且再次被访问,才移到Young区头部。
LRU List: [Young区 (5/8)] <- midpoint -> [Old区 (3/8)]
↑ ↑
热数据区 新数据首次插入这里
参数配置:
innodb_old_blocks_pct:Old区占比,默认37(即3/8)innodb_old_blocks_time:page在Old区的存活时间阈值,默认1000ms
脏页刷新策略
脏页是指在内存中被修改但还未写入磁盘的page。刷盘策略包括:
1. 自适应刷新(Adaptive Flushing)
- 根据redo log生成速度动态调整刷新速率
- 防止redo log空间不足导致的checkpoint阻塞
2. 刷新时机:
- Buffer Pool空间不足时
- Redo log空间不足时
- 定期刷新(Page Cleaner线程)
- 关闭数据库时
3. 刷新算法:
- LRU刷新:从LRU list尾部刷新脏页
- Flush刷新:从Flush list刷新最老的脏页
相关参数:
innodb_max_dirty_pages_pct:脏页比例阈值,默认75%innodb_io_capacity:磁盘IO能力,影响刷盘速度
Buffer Pool预热
数据库重启后,Buffer Pool为空,会出现”冷启动”问题,性能较差。
预热策略:
- 自动预热:MySQL 5.6+支持,关闭时保存hot page列表,重启时自动加载
- 手动预热:执行关键查询语句,主动加载热数据
相关参数:
innodb_buffer_pool_dump_at_shutdown=1:关闭时保存innodb_buffer_pool_load_at_startup=1:启动时加载
Buffer Pool大小设置
经验法则:
- OLTP系统:物理内存的50%-75%
- 分析系统:物理内存的80%
- 考虑预留给OS和其他进程的内存
监控指标:
- Buffer Pool命中率 = (Innodb_buffer_pool_read_requests - Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests
- 目标:>99%
Transaction之I - Concurrency control
Transaction如果One by one的串行执行没有什么问题,但如果两个Transaction并发执行,它们又修改了相同的数据,则会产生冲突。
解决Transaction并发执行冲突问题,有两种方案,
- 锁(悲观并发控制)
- 快照(Snapshot isolation,乐观并发控制)
2PL(Two-Phase Locking)
Transaction中常用2PL,锁是一种悲观解决方案。2PL分为两个阶段:
- Growing Phase(扩展阶段):事务可以获取锁,但不能释放锁
- Shrinking Phase(收缩阶段):事务可以释放锁,但不能获取新锁
2PL能保证Serializability(可串行化),但可能导致死锁问题(后续章节详述)。
Snapshot Isolation(快照隔离)
快照是一种乐观的解决方案,基于MVCC(Multi-Version Concurrency Control,多版本并发控制)实现。每个事务读取数据时,看到的是事务开始时刻的一致性快照。写入时通过版本链管理多个版本。
Transaction提交时,如果多个Transaction更新了同一份数据,则产生冲突,一般采用First-committer-wins的冲突解决方案。
快照比较适合于写入冲突不太严重的场景,读操作不会阻塞写操作,写操作也不会阻塞读操作,因此并发性能较好。
Snapshot Isolation的异常
快照隔离存在Write Skew问题:
两个值A=1000,B=2000,
两个Transaction T1/T2,并发读A和B,T1执行: A=B,T2执行:B=A,T1/T2两个Transaction分别提交之。
则结果是A=2000,B=1000,两个值互换了,两个Transaction都成功,因为写了不同的值,因此没有冲突。
但我们期待的结果是,要么A=B=1000,要么A=B=2000,取决于T1/T2提交的先后次序。
这种异常说明Snapshot Isolation并不能保证Serializability。要解决这个问题,需要使用Serializable Snapshot Isolation(SSI),通过检测读写依赖来避免这种异常。
MVCC(Multi-Version Concurrency Control)详解
MVCC是实现Snapshot Isolation的核心技术,它允许读写并发执行而不互相阻塞。MVCC的核心思想是为每次数据更新保留一个版本,不同的事务可以看到不同版本的数据。
版本链的组织
以MySQL InnoDB为例,每行记录包含以下隐藏列:
- DB_TRX_ID:最近修改该记录的事务ID
- DB_ROLL_PTR:指向undo log中该记录的前一个版本
- DB_ROW_ID:行ID(如果没有主键和唯一非空索引时使用)
通过DB_ROLL_PTR,同一行的多个版本形成一条版本链(undo log链):
最新版本 -> 版本2 -> 版本1 -> 最老版本
UPDATE操作会:
- 在undo log中记录旧版本数据
- 在原地更新记录,设置DB_TRX_ID为当前事务ID
- 设置DB_ROLL_PTR指向undo log中的旧版本
ReadView(读视图)
事务读取数据时,会生成一个ReadView,包含:
- m_ids:当前活跃(未提交)的事务ID列表
- min_trx_id:m_ids中的最小值
- max_trx_id:系统即将分配的下一个事务ID
- creator_trx_id:创建该ReadView的事务ID
可见性判断规则
对于版本链上的每个版本,通过以下规则判断是否可见:
if (DB_TRX_ID < min_trx_id) {
// 该版本在所有活跃事务开始前就提交了,可见
return VISIBLE;
} else if (DB_TRX_ID >= max_trx_id) {
// 该版本是在当前事务开始后才创建的,不可见
return NOT_VISIBLE;
} else if (DB_TRX_ID in m_ids) {
// 该版本是由未提交的事务创建的,不可见
return NOT_VISIBLE;
} else {
// 该版本是由已提交的事务创建的,可见
return VISIBLE;
}
不同隔离级别的实现
不同的事务隔离级别通过不同的ReadView生成时机来实现:
Read Committed(RC)
- 每次SELECT都生成新的ReadView
- 可以读到其他事务已提交的修改
- 会出现不可重复读
Repeatable Read(RR)
- 事务第一次SELECT时生成ReadView,之后复用
- 始终读取事务开始时的数据快照
- 解决了不可重复读,但可能出现幻读
Serializable
- 通过锁或SSI实现
- 完全避免并发异常
MVCC的优势
- 读写不阻塞:读操作读历史版本,不阻塞写操作
- 无锁读:普通SELECT不需要加锁,提高并发性
- 一致性读:事务看到的是一致性快照
MVCC的代价
- 空间开销:需要维护多个版本的数据
- 版本清理:需要定期清理(purge)旧版本
- 不能完全避免幻读:RR级别下INSERT新行仍可能被看到
死锁检测与处理
使用锁进行并发控制时,可能出现死锁问题。
死锁的产生
经典的死锁场景:
事务T1:持有锁A,等待锁B
事务T2:持有锁B,等待锁A
Wait-For Graph(等待图)
数据库通过wait-for graph检测死锁:
- 节点:事务
- 有向边:T1 -> T2 表示T1等待T2持有的锁
死锁检测算法:
- 定期或在请求锁时构建wait-for graph
- 检测图中是否存在环
- 如果存在环,则说明发生了死锁
环检测可以使用DFS算法,时间复杂度O(V+E)。
死锁处理策略
1. 超时机制
- 设置锁等待超时时间(如innodb_lock_wait_timeout=50秒)
- 超时后回滚事务并报错
- 简单但可能误杀正常的长事务
2. 选择牺牲者(Victim Selection)
- 检测到死锁后,选择一个事务回滚
- 选择标准:
- 事务执行时间最短的
- 修改数据最少的
- 锁等待链最短的
3. Wait-Die / Wound-Wait
- 根据事务时间戳预防死锁
- Wait-Die:老事务等待年轻事务,年轻事务等待老事务时abort
- Wound-Wait:老事务抢占年轻事务,年轻事务等待老事务
死锁预防
应用层最佳实践:
- 按相同顺序访问资源
- 尽量缩小事务范围
- 合理设置隔离级别(不总是用Serializable)
- 使用索引避免锁升级
分布式Transaction
相比单机,分布式多了Partition和Replication。我们在分布式中,追求的仍然是AID->C。
在分布式环境中,对于AD来说,如果一个transaction的更新请求都路由到同一个节点,则依靠单机能力,已经可以实现分布式环境的AD保障。其中单机完成local transaction(global transaction的sub transaction),分布式即完成global transaction。
但如果transaction的操作涉及多个节点,则需要一种额外机制,这个机制是2PC。
2PC
2PC涉及2个角色,coordinator(协调者)节点和participant(参与者)节点。
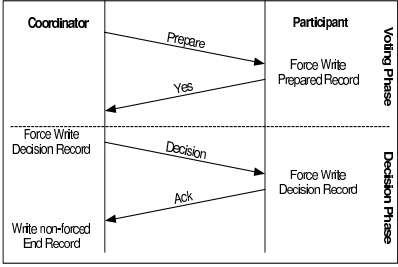
2PC最大的问题是,它是一个blocking协议,当协调节点fail且恢复不了,某些Participant将处于resolve状态:参与节点已经成功发送agreement消息(Vote Yes),它将一直阻塞在这里,直到收到协调者的commit或abort消息。
2PC的难点不在协议本身,两个阶段比较好理解。它的难点在于Coordinator或Participant fail情况的处理,分别讨论,
Coordinator节点fail
- Coordinator在写prepare T log后,写commit T/abort T log前fail
Participant在收到prepare T消息并写ready T/No T log后,就一直 blocking等待Coordinator回复。Coordinator恢复后执行recovery并咨询所有Participant ready T or abort T,根据回应执行commit T/abort T流程
- Coordinator在写commit T/abort T log后,T end前fail
Participant在收到commit T/abort T消息并写commit T/abort T log后,sub transaction就算完成了。Coordinator恢复后执行 recovery并询问所有Participant是否已经commit T/abort T,如果都执行了就可以end T并回复client
Participant节点fail
- Participant收到prepare T信息,但在回应Coordinator 前fail
因为2PC第二阶段里Coordinator必须要所有节点都回应ready T才能 commit,那现在Coordinator就收不到fail节点的任何回应,自然应该 abort T。
fail节点恢复后,如果fail前只写了sub transaction log records 但没有写No T或者 Ready T log,意味着该节点没有正常参与2PC,直接执行单节点recovery即可,这些已写的log record都会被 undo。
如果fail前写了ready T/No T log,意味着该节点正常参与了2PC(尽管实际上没有回应prepare T),那么就需要主动询问Coordinator关于T的结果,结合abort T的结果再执行recovery并ACK Coordinator,因为在2PC里只有Coordinator有权决定T是commit还是 abort,如果本地直接recovery undo T就会违反2PC
- Participant在回应prepare T信息后,收到Coordinator的commit T/abort T信息前fail
Coordinator正常根据所有节点的prepare T回应判断执行commit T/abort T流程即可。
fail节点恢复后,因为fail前肯定写了ready T/No T log,跟上一种情况一样,需要主动咨询Coordinator 关于T的结果,结合T的结果再执行recovery并ACK Coordinator
- Participant收到Coordinator的commit T/abort T信息,但在写本地commit T/abort T log前fail
Coordinator不需要额外动作。fail节点恢复后,同样需要主动咨询 Coordinator关于T的结果,结合T的结果再执行recovery并ACK Coordinator
- Participant写本地commit T/abort T log后fail
Coordinator不需要额外动作。fail节点恢复后,正常执行recovery并 ACK Coordinator
2PC+单机transaction,实现了分布式transaction的AD功能,其中2PC+单机log保障A,单机log保障D。
2PC coordinator的单点问题
2PC blocking问题,根源来自Coordinator的单点故障,只有Coordinator了解本次transaction的状态及全局结果。后面讨论Replication时,看如何解决该问题。
锁、Snapshot与I
分布式下锁机制与单机一致,区别是分布式下需要一个中心化的lock manager来解决deadlock的问题,它需要一个全局视角来构建dependency graph.
分布式Snapshot的问题在于,相同transaction T在不同Node,可能读取的是不同版本快照。
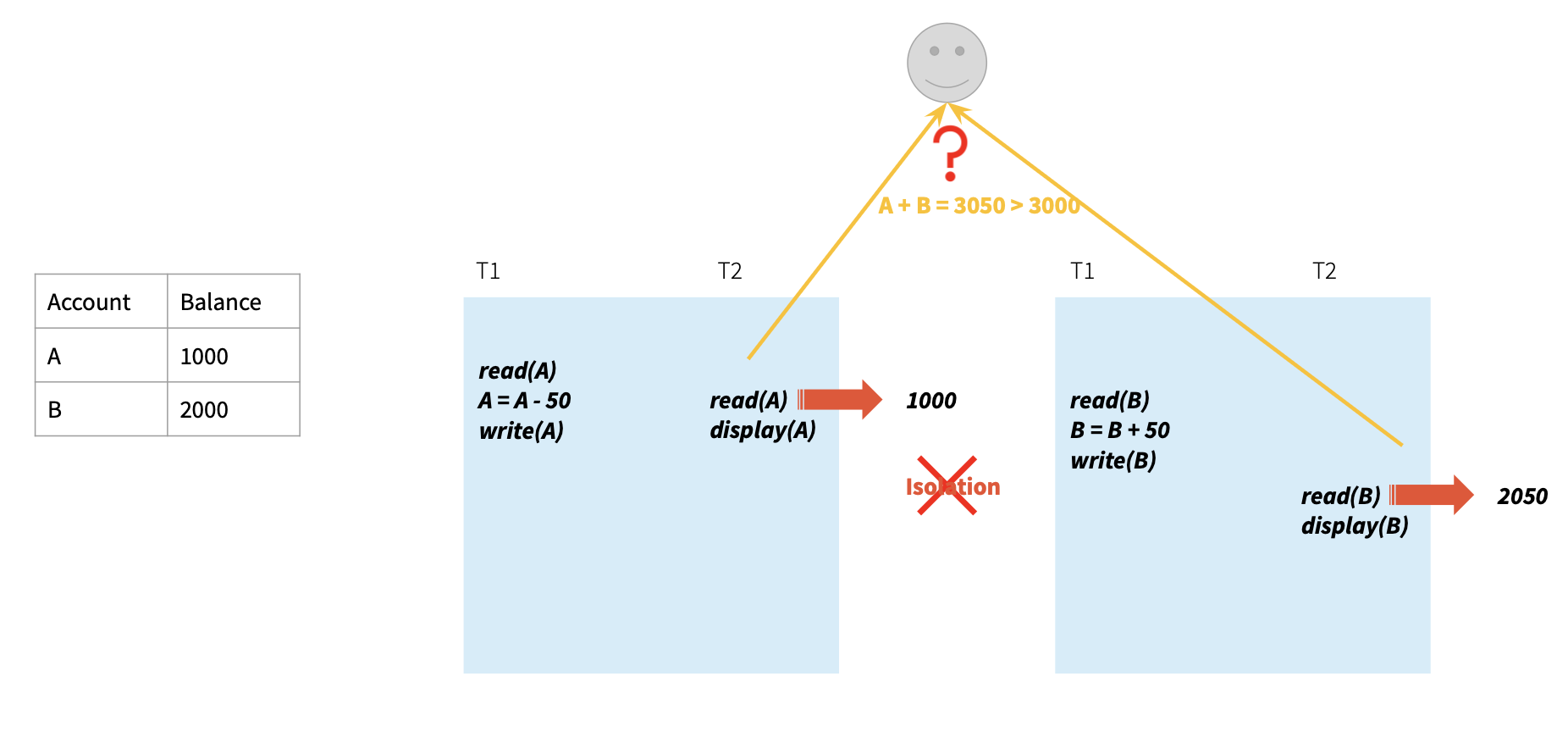
如T2在Node1读取的是T1更新前的数据版本,而在Node2读取的是T1更新后的数据版本。这导致T2看来,某一时间SUM(A, B)=3050,与实际的3000不符。
因此也需要一个中心化的角色,来控制transaction访问的数据版本(只有commit的版本才会被其它transaction看见),以及更新冲突时以哪个版本为准。
Replication
上面讲的是引入partition的情况下,导致的transaction处理算法变化。
实际上,分布式系统为了高可用,还引入了replication。理想的状态,某个partition的写成功,代表的应该是其所有replica都写成功。而所有replica都写成功,这是atomic commit protocol,比如2PC提供的能力。
但replication的目的是高可用,如果因为某一个replica fail就写失败了,是违背高可用原则的,需要对2PC进行一些改造,使他不需要所有Participant都Vote才能完成。
Quorum
这就是Quorum机制,它仍基于2PC的原理,并有两条原则:
- W + R > N(W是写replica个数,R是读replica个数,N是节点数量)
- W > N/2
比如W = 2,则只需2PC的写两个replica即可。
Primary replication
Quorum的问题在于,我们需要读多份数据,才能比较出最新我们需要的数据。
而另外也有一种Primary replication的方式,数据的读写都在同一个节点,而这个节点负责将数据同步给其它replica(W > N/2,即同步更新半数以上节点)。
当Primary节点fail时,需要从replica中选举出新的Primary节点,这个过程叫leader选举。Raft是Primary replication+leader选举这套算法的工程实现。
Raft
首先raft是基于log的协议,partition中的数据可看作是log,log记录都是append追加的,每个log记录都有一个index。多个replica中有一个是 leader,其他的都是follower。raft将时间线划分成了term,term编号是递增的,每一届term中都有唯一的leader。
每个log记录标识了写入该记录的term.
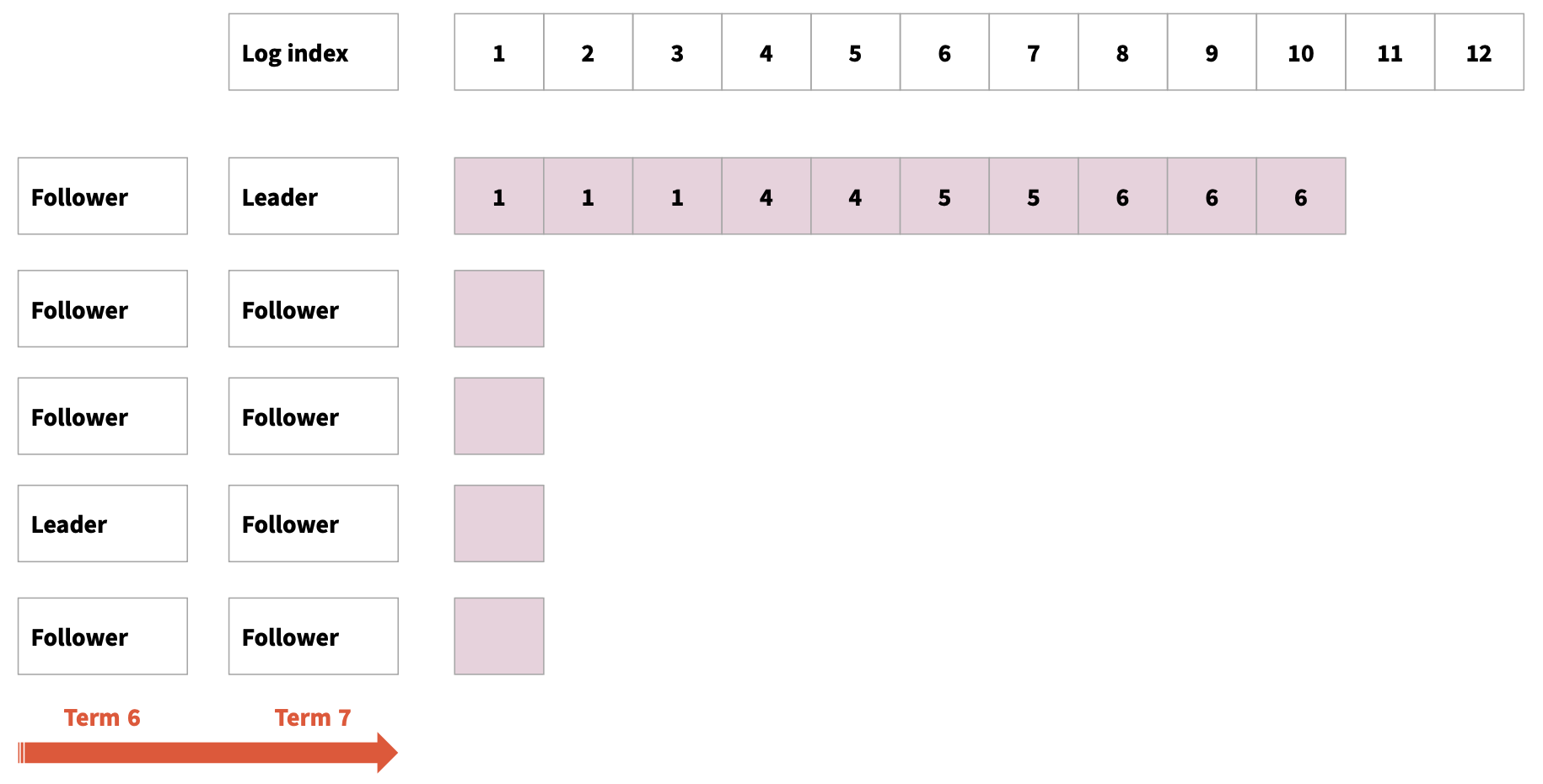
假设某个时刻replica中的log记录分布是这样的,此时leader fail,follower在一段时间内没有收到leader的心跳,则判断leader已经fail,启动leader election流程。
该follower给其他所有replica发送RequestVote请求(current term id+1,index)。其他replica收到 RequestVote请求后,判断如果发现自己的log比候选人的log更加新,则Vote no,否则Vote yes,log比较的规则是:
- term更大的log更加新
- term一样log更多(index 更大)的更加新
这样的话这个replica就获取了包括它自己在内大多数replica的投票,被选举为新leader.

Log Replication(日志复制)
Leader被选举出来后,开始处理客户端请求。日志复制过程如下:
1. Leader接收请求
- Client发送命令到Leader
- Leader将命令作为新的log entry追加到自己的log
- Log entry包含:term、index、command
2. Leader复制日志(AppendEntries RPC)
- Leader并行向所有Follower发送AppendEntries RPC
- AppendEntries包含:
term:Leader的termprevLogIndex:新entry前一条log的indexprevLogTerm:新entry前一条log的termentries[]:要复制的log entriesleaderCommit:Leader的commit index
3. Follower响应
- Follower检查prevLogIndex和prevLogTerm是否匹配
- 匹配则追加新entries并返回success
- 不匹配则返回failure(触发Leader回退重试)
4. Leader提交日志
- 当log entry被复制到大多数节点后,Leader将其标记为committed
- Committed的log entry才会被应用到状态机
- Leader通过下一次AppendEntries RPC告知Follower更新commit index
5. Follower应用日志
- Follower收到leaderCommit更新后,将<=leaderCommit的所有log应用到状态机
Commit Index与Applied Index
Commit Index:
- 已知已被大多数节点复制的最高log index
- Leader和Follower都维护
- 只增不减
Applied Index:
- 已应用到状态机的最高log index
- applied index <= commit index
- 通过周期性检查,将commit但未apply的log应用到状态机
Safety Guarantee(安全性保证)
Leader Completeness Property:
如果一个log entry在某个term被commit,那么这个log entry一定会出现在所有更高term的Leader的log中。
这个性质通过leader选举时的限制保证:
- 只有拥有”最新”log的Candidate才能赢得选举
- “最新”定义:term更大,或term相同但index更大
Log Matching Property:
- 如果两个log entry有相同的index和term,则它们存储相同的command
- 如果两个log entry有相同的index和term,则它们之前的所有log entry都相同
这个性质通过AppendEntries的一致性检查保证。
日志不一致的处理
Follower的log可能比Leader多或少,Raft通过以下机制处理:
1. Leader强制覆盖
- Leader的log是”source of truth”
- Follower的log必须与Leader保持一致
2. 回退重试
- Leader为每个Follower维护
nextIndex - AppendEntries失败时,Leader递减nextIndex并重试
- 直到找到匹配点,然后从该点开始复制
3. 快速回退优化
- Follower返回冲突的term和该term的第一条log index
- Leader跳过整个冲突term,加速日志同步
Raft的优势
- Strong Consistency:提供线性一致性保证
- 理解性好:分解为leader election、log replication、safety三个子问题
- 实用性强:在etcd、Consul等系统中广泛应用
Raft vs 2PC
| 特性 | Raft | 2PC |
|---|---|---|
| 一致性 | 强一致 | 强一致 |
| 可用性 | 高(只需大多数节点) | 低(需要所有节点或coordinator恢复) |
| 适用场景 | 元数据存储、配置管理 | 分布式事务 |
| Blocking | 非阻塞 | 阻塞 |
| Leader | 自动选举 | 固定coordinator |
技术选型与最佳实践
索引技术对比与选择
| 索引类型 | 读性能 | 写性能 | 范围查询 | 空间占用 | 适用场景 |
|---|---|---|---|---|---|
| B+树 | O(log n) | O(log n) | ✅ 优秀 | 中等 | OLTP、通用场景 |
| Hash索引 | O(1) | O(1) | ❌ 不支持 | 较小 | KV存储、等值查询 |
| LSM-Tree | O(log n) | O(1)* | ✅ 良好 | 较大 | 写密集型、时序数据 |
实践建议:
OLTP场景:优先选择B+树索引
- 支持范围查询
- 读写性能均衡
- MySQL、PostgreSQL默认选择
时序数据、日志场景:考虑LSM-Tree
- 写入性能优异(顺序写)
- 适合append-only场景
- ClickHouse、HBase、TiDB采用
KV存储:可考虑Hash索引
- 等值查询性能最优
- 不需要范围查询时选择
- Redis的hash table实现
索引使用注意事项:
- 避免在低选择性列建索引
- 注意复合索引的列顺序(最左前缀原则)
- 定期analyze统计信息
- 监控索引使用率,删除无用索引
分区策略对比与选择
| 策略 | 负载均衡 | 点查性能 | 范围查询 | 扩展性 | 实现复杂度 |
|---|---|---|---|---|---|
| Round-robin | ⭐⭐⭐⭐⭐ | ❌ 需扫描所有分区 | ❌ 需扫描所有分区 | 简单 | 低 |
| Hash | ⭐⭐⭐⭐ | ✅ O(1)定位 | ❌ 需扫描所有分区 | 重分区困难 | 中 |
| Range | ⭐⭐⭐ | ✅ O(1)定位 | ✅ 可局部扫描 | 需动态调整 | 高 |
实践建议:
消息队列:使用Round-robin
- 均衡性最好
- 不需要查询功能
- Kafka默认策略
KV存储、缓存:使用Hash分区
- 点查性能好
- 数据分布均匀
- Redis Cluster采用
关系型数据库:使用Range分区
- 支持范围查询
- 配合业务字段(如时间、地域)
- 需要解决热点问题
分区实践要点:
- 避免使用递增ID作为hash key(会导致热点)
- Range分区要使用Virtual Node
- 预估数据增长,预留扩展空间
- 监控各分区负载,及时rebalance
副本方案对比与选择
| 方案 | 一致性 | 可用性 | 读性能 | 写性能 | 复杂度 |
|---|---|---|---|---|---|
| 2PC | 强一致 | ⭐⭐ 低 | 低 | 低 | 中 |
| Quorum | 最终一致 | ⭐⭐⭐⭐ 高 | 中 | 中 | 低 |
| Primary Copy (Raft) | 强一致 | ⭐⭐⭐⭐ 高 | 高 | 中 | 高 |
实践建议:
元数据存储、配置中心:使用Raft
- 需要强一致性
- 数据量小,写不频繁
- etcd、Consul采用
大数据存储:使用Quorum
- 可接受最终一致
- 需要高可用
- Cassandra、DynamoDB采用
避免使用2PC:
- 生产环境慎用(blocking问题)
- 考虑替代方案:
- 最终一致性(Saga、本地消息表)
- TCC(Try-Confirm-Cancel)
- 业务层面避免分布式事务
事务隔离级别选择
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 | 适用场景 |
|---|---|---|---|---|---|
| Read Uncommitted | ✓ | ✓ | ✓ | 最高 | 几乎不用 |
| Read Committed | ✗ | ✓ | ✓ | 高 | 对一致性要求不高 |
| Repeatable Read | ✗ | ✗ | ✓/✗* | 中 | 大多数场景(默认) |
| Serializable | ✗ | ✗ | ✗ | 低 | 强一致性需求 |
*注:MySQL InnoDB在RR级别通过Next-Key Lock解决了幻读
实践建议:
大多数场景:使用Repeatable Read
- 平衡一致性和性能
- MySQL默认级别
高并发读多写少:使用Read Committed
- 减少锁竞争
- PostgreSQL默认级别
金融、支付场景:使用Serializable或Snapshot Isolation
- 完全避免并发异常
- 通过optimistic或pessimistic控制
隔离级别使用要点:
- 不要盲目使用最高隔离级别
- 根据业务需求选择
- 注意隔离级别与锁的关系
- 监控事务等待和死锁情况
总结
本文系统性地介绍了数据库系统的内部实现,包括:
- 存储层:数据文件和索引文件的组织方式,B+树、Hash、LSM-Tree等索引技术
- 分布式:Partition和Replication的实现,包括Range/Hash分区、Virtual Node、2PC、Quorum、Raft等
- 事务:ACID的实现原理,WAL、MVCC、2PL、死锁处理等并发控制机制
- 性能优化:Buffer Pool管理、索引选择、查询优化等最佳实践
数据库系统是一个复杂的系统,涉及存储、索引、事务、并发控制、分布式等多个方面。理解这些内部原理,有助于我们:
- 进行合理的技术选型
- 编写高性能的SQL
- 排查和解决生产问题
- 设计高可用的分布式系统
在实际应用中,需要根据具体场景选择合适的技术方案,在一致性、可用性、性能之间做好权衡。