MyBlog
【Paper】Krypton: Real-time Serving and Analytical SQL Engine at ByteDance
last modified: 2024-07-20 12:26
一、Krypton出现的背景
在字节越来越多的业务(Ads AB Test,Zhuxiaobang)需要针对海量高时效要求的实时数据,进行高QPS的复杂Ad Hoc查询。
总结需要满足下面3点需求:
- 支持海量实时数据的高时效写入
- 支持复杂Ad Hoc查询
- 支持高QPS在线查询
Krypton作为一款HSAP(Hybrid Serving and Analytical Processing)产品,设计来满足这些需求。
Analytical表示它支持复杂Ad Hoc查询,Serving表示它提供高QPS的在线查询能力。Krypton总体设计遵循以下原则:
- 高扩展性:能处理数百PB的实时数据分析
- 低延迟和高QPS:能够支撑百万QPS和毫秒级延迟的查询
- 数据强一致性:提供数据的一致写和快照读的功能
- 高时效性:亚秒级别查询到最新写入的数据
- 高写入性能:能够满足每秒百万行的数据写入速度
- 支持标准SQL
二、Krypton的系统架构
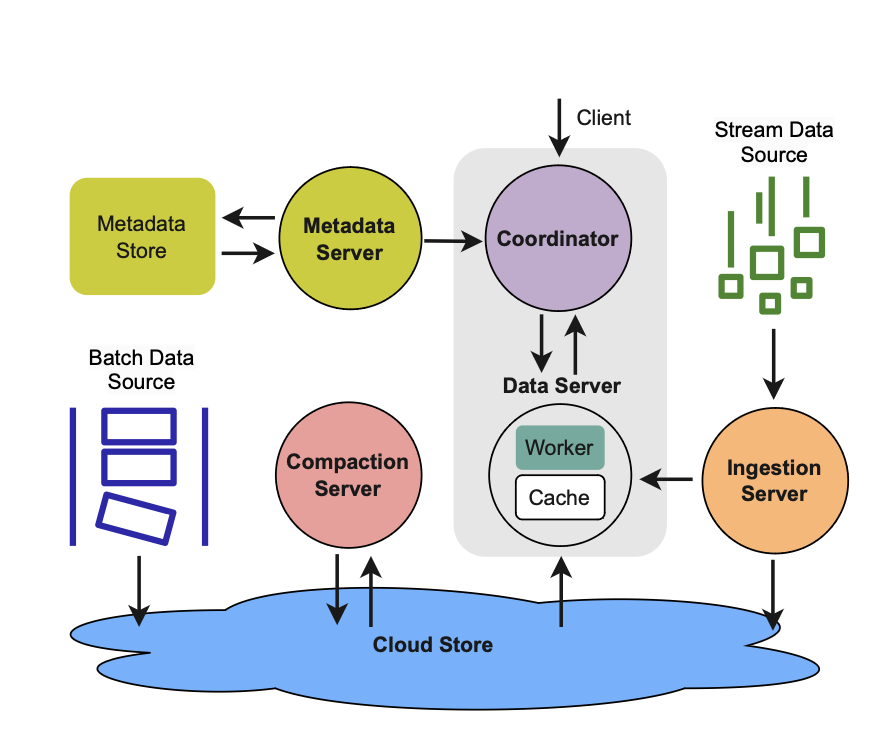
整体上,Krypton使用了存储计算分离的架构,数据存放在Cloud Store上,利用Cloud Store可以实现无限扩展性。计算模块是无状态的,可以根据负载独立动态扩展。
另外Krypton采用了读和写分离的架构。IgSs(Ingestion Servers)负责处理实时写入,并将数据周期性flush到Cloud Store,它同时还Serve来自DSs(Data Servers)读最新数据的请求。CSs(Compaction Servers)周期性的合并Cloud Store中存储的数据文件。
来自Client的读请求先发送到Coordinator节点,Coordinator进行SQL解析、生成执行计划,发送请求到DSs(Data Servers)节点查询数据。DSs符合MPP的架构设计,每个节点只负责特定子集数据查询,并且其数据并不存储在本地,可以很容易进行水平扩展。IgSs和DSs可以根据读写负载的不同,单独进行扩容。
作为对比,Krypton解决了ClickHouse的两个问题。
- 查询QPS
Krypton是存算分离架构,查询节点DSs无状态,可以方便进行扩展,而ClickHouse则因为查询节点与本地数据绑定而无法实现动态扩展。
- 数据写入的灵活性
Krypton提供了单独的IgS节点用于数据写入,解决了实时数据写入灵活性的问题,它类似于Druid提供的MiddleManager节点。而作为对比,ClickHouse虽然也有Kafka table engine,但实际使用中,在成熟度和灵活性上要差的多。
三、与现有解决方案对比
最能满足以上需求的产品是ClickHouse,与Krypton对比如下:
- 高扩展性
因为计算节点与存储绑定,ClickHouse的动态扩展能力不足。但通过预先估算好数据量,设置合理shard,亦能支持数百PB的数据分析。
- 低延迟和高QPS
ClickHouse查询延迟较低,得益于列式存储和索引的支持。但是ClickHouse是MPP架构,查询能力受节点个数限制,提供不了高QPS支持。
- 数据一致性
ClickHouse提供ReplacingMergeTree保证数据一致性,但本身并不提供事务写入保障。
- 高实效性
数据在完成协调节点到存储节点的数据同步后即可查询,这个过程很快完成。可以实现亚秒级的查询。
- 高写入性能
ClickHouse提供类LSM-Tree的数据架构,数据批量顺序写入,可以实现非常高的写入吞吐。
- 支持标准SQL
ClickHouse不是标准SQL,但使用上与标准SQL差别不大。
综上Krypton对比Clickhouse的优点是通过存算分离解决了高QPS查询的问题,并且有专门的节点负责数据Ingestion,灵活性更好。
四、Krypton的技术细节
以Database system通用的技术框架,来分析Krypton实现细节
数据文件结构
- Partition Attributes Across (PAX) 列式存储结构。论文地址。
该算法对比Parquet的优点是, 1)对Nested和Repeated数据,有更好的寻址速度,2)对稀疏列有更好的存储效率,3)存储更多Index,在TPC-H数据集上,通过13%的额外存储带来21%的读效率提升
编码和索引
- Built-in-indexes
- prefix index
- ZoneMap index
- User-defined secondary indexes
- Ordinal Index
- Sparse Indexes: min/max index, bloom filter, and ribbon filter
- Short-key Index
- Equality and range bitmap index
- Skip Index
- Encoding
- Run-Length-Encoding
- Frame-of- Reference
- Built-in-indexes
差异化的是ribbon算法,它对范围查询和精确查找进行了优化。其它都是较为普遍使用的设计。
分区
- Partitions and tablets two-level data partitioning(类似CK Shard + Partition两级数据分区结构)
- Methods:hash, range, and list
副本
Cloud Store(类比HBase使用HDFS存储Hfile)
事务 & 一致性
- WALs成功flush到Cloud Store,该committed_version版本数据才可读
- 允许dirty read IgSs上未committed的数据
- 未介绍写入事务性,理论上存在重复问题
- 在多个层面未提供一致性保障,比如有个后台cache maintenance manager,定期比较Metadata Server和数据版本,清除stale cache
缓存(+++)
- 多级缓存(hierarchical cache)
- DRAM, PMem, and SSD
- Cache everything
- Including data, query results, query plans, and metadata
- 多级缓存(hierarchical cache)
Krypton整体在解决方案上没有应用什么创新技术,与Clickhouse比较最大的优势是实现了存储和计算的分离,从而使读负载可以水平扩展以支持高QPS查询的场景。但这也带来Cloud Store与DSs节点间数据传输带来的天然延迟和带宽问题。Krypton通过DSs上大量、多级缓存来解决这个问题,它非常适合于对较少数据量(热点、局部性)进行高QPS查询的场景。