MyBlog
【Paper】Lakehouse
last modified: 2022-04-11 15:36
论文写的比较啰嗦,总结起来介绍了当前的数仓架构及数据湖两层架构存在的问题,及定义了Lakehouse及其如何解决这些问题。介绍了Databricks的一些实践(Delta lake),但是缺乏细节描述
Background
v1.0 Data Warehouse
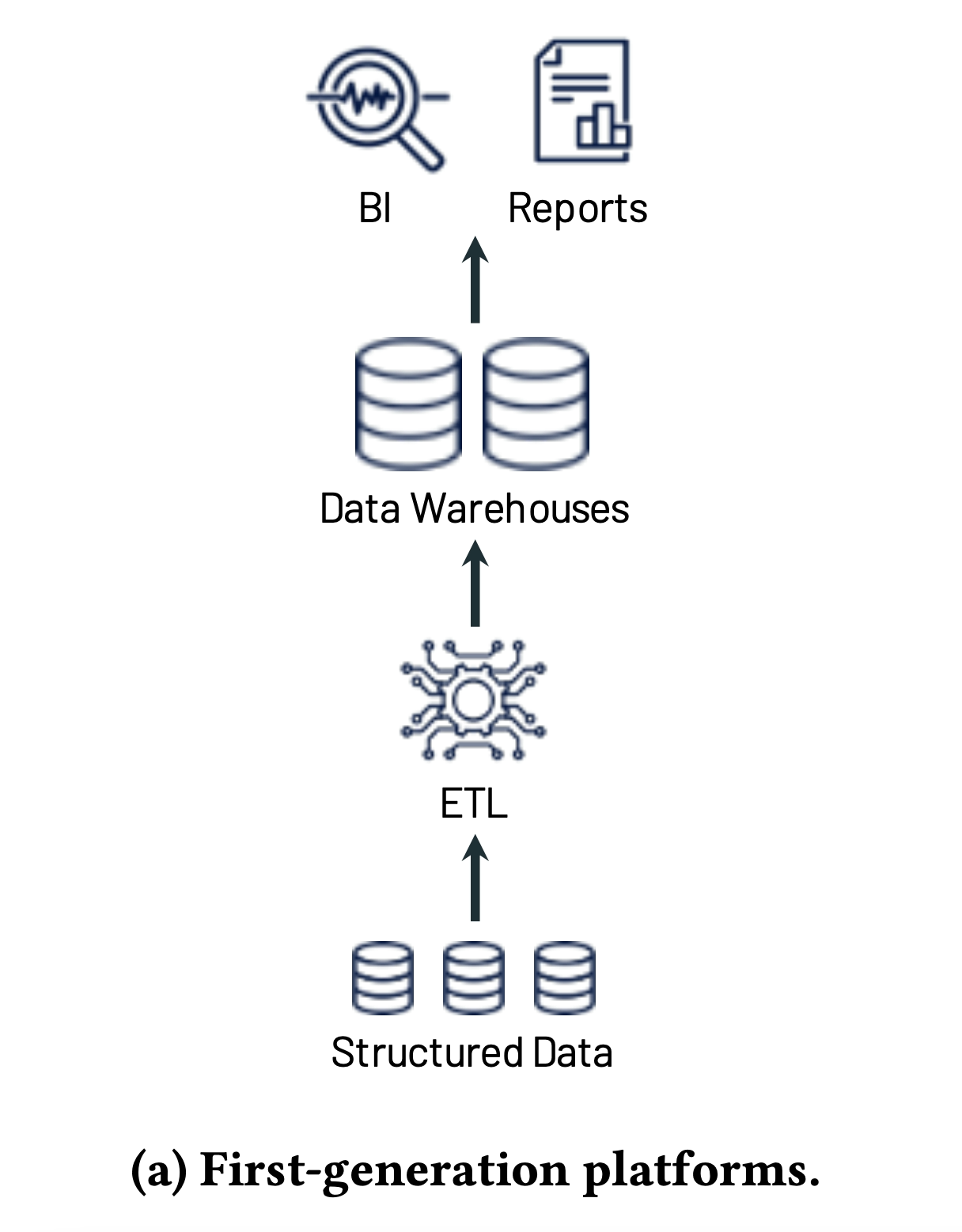
Challenges
- Schema-on-write(More and more datasets were completely unstructured, e.g., video, audio, and text documents)
- Coupled compute and storage into an on-premises appliance(costly as datasets grew)
v2.0 Data Lake
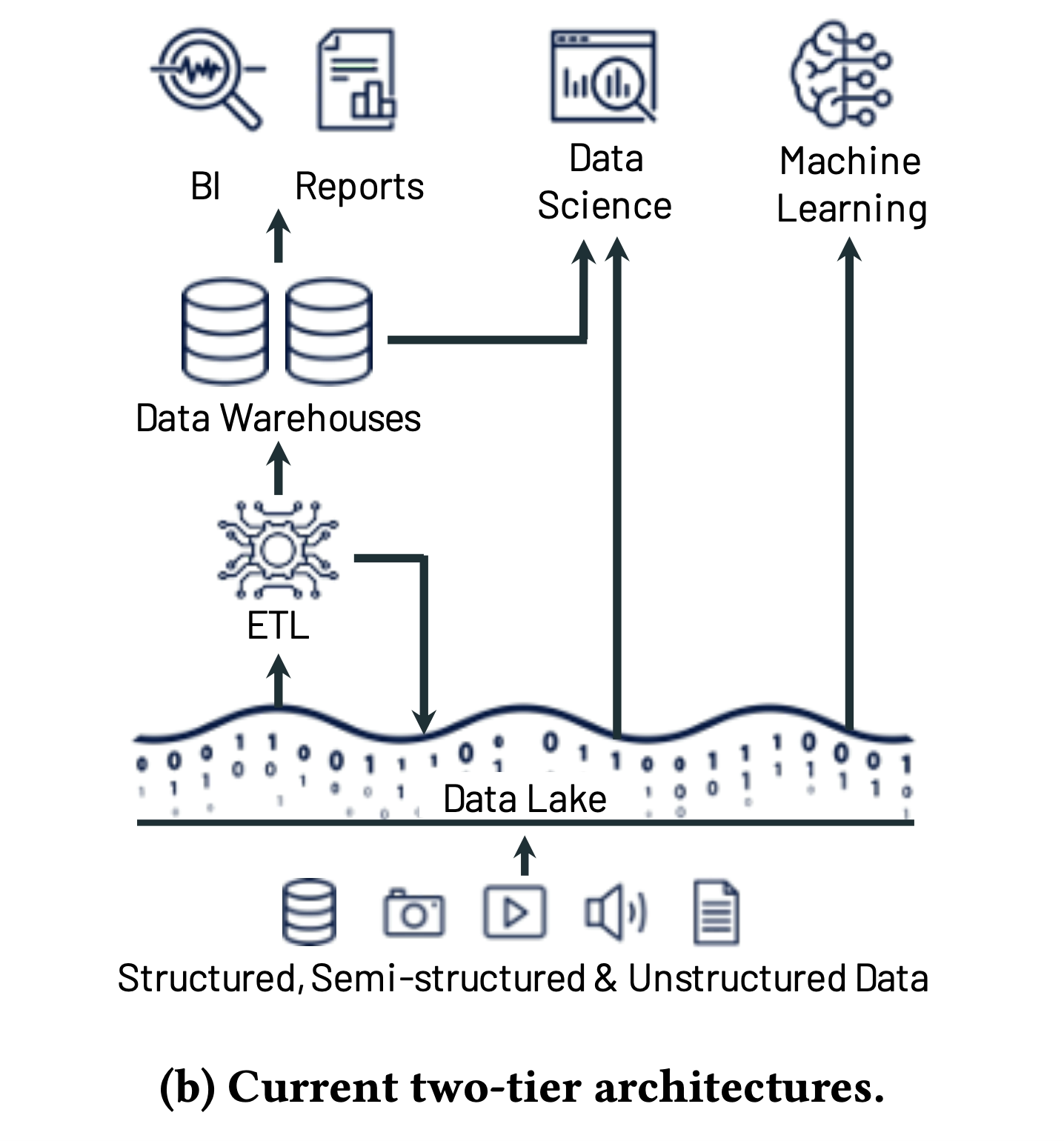
Solutions(Takeover Data Warehouse Challenges)
- Schema-on-read, all raw data into Data Lake(Open file formats, such as Apache Parquet, ORC; Low cost storage with file API: such as S3), punted the problem of data quality and governance downstream
- Two-tier architecture. Lake data later be ETLed to downstream data warehouse(such as Redshift). Separate storage(such as S3) and compute(such as Redshift)
Challenges
- One more ETL, creating complexity, delays and new failure modes
- For ML(Machine Learning), Data Warehouse and Lake both not ideal
Some more details:
- Reliability
- Keeping the data lake and warehouse consistent is difficult and costly.
- Data staleness
- The data in the warehouse is stale compared to that of data lake(for example: out of date)
- Limited support for advanced analytics
- Answer predictive questions
- ML(Often need to process large datasets using complex non-SQL code.)
- Reading data via JDBC is inefficient (One more ETL step!) and lose benefit from data warehouse such as ACID transaction, data versioning and indexing
- Total cost of ownership
- data lake -> warehouse, double the storage cost
v3.0 Lakehouse

Ideal features
- Low-cost and directly-accessible storage(Data Lake, separate compute and storage)
- Provides traditional analytical DBMS management and performance features(Data Warehouse)
- ACID transactions
- Data Versioning
- Auditing
- Indexing
- Caching
- Query optimization(state-of-the-art performance)
The Lakehouse Architecture
Overall architecture
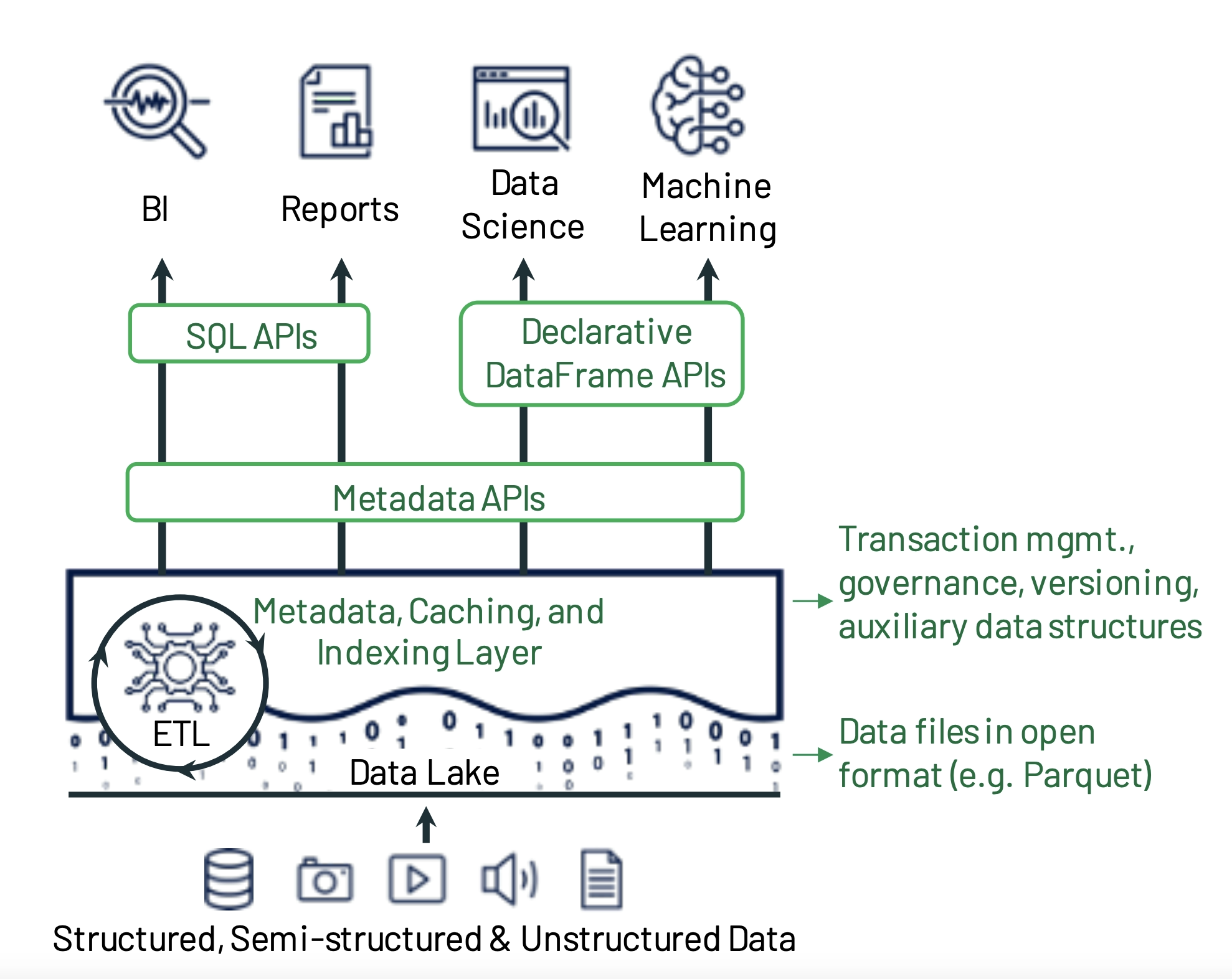
Key Designs
A low-cost object store(e.g., Amazon S3)
A transactional metadata layer on top of the object store
- implement management features here(e.g., ACID, versioning, governance(access control, audit logging))
SQL performance(state-of-the-art)
- Separate hot and cold data placement(for example: hot data in SSDs)
- Building access methods: indexing, co-optimizing the data format and compute engine
- Declarative DataFrame APIs(for ML libraries, such as TensorFlow and Spark MLlib)
- Caching
- Auxiliary data
- Column min-max statistics for each data file
- Bloom filter
- Data layout
- New file format(just imagine) Support placing columns in different orders within each data file, choosing compression strategies differently for various groups of records, or other strategies.
Efficient Access for Advanced Analytics
- Offering a declarative version of the DataFrame APIs
Thinking
how to organize data engineering processes and teams with concepts such as “data mesh”, where separate teams own different data products end-to-end gaining popularity over the traditional “central data team” approach. Lakehouse designs lend themselves easily to distributed collaboration structures because all datasets are directly accessible from an object store without having to onboard users on the same compute resources, making it straightforward to share data regardless of which teams produce and consume it.
An amazon lakehouse architecture
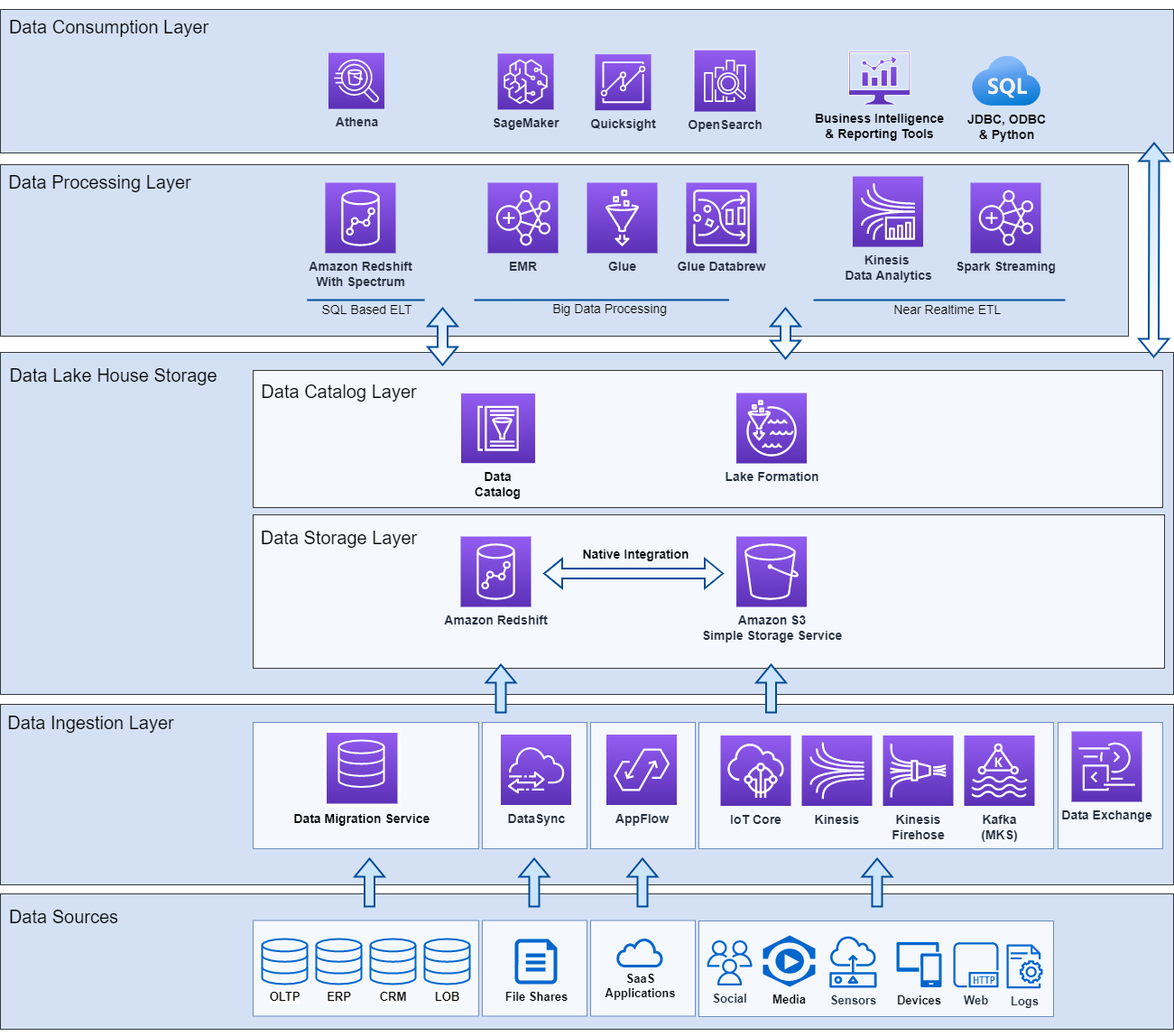
Reference
Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics