MyBlog
A Quick Refresh of Key Backend Topics
last modified: 2023-01-23 19:46
架构设计
系统运维
namespace
作用:隔离。由3个API(clone创建,unshare离开,setns加入)和一组/proc文件构成。
$ ls -l /proc/$$/ns # $$ is replaced by shell's PID
total 0
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 net -> net:[4026531956]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 pid -> pid:[4026531836]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 user -> user:[4026531837]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 uts -> uts:[4026531838]
每个namespace有一个唯一ID,拥有相同ID的进程同属一个namespace。
cgroups
作用:限制。通过VFS暴露给用户态。
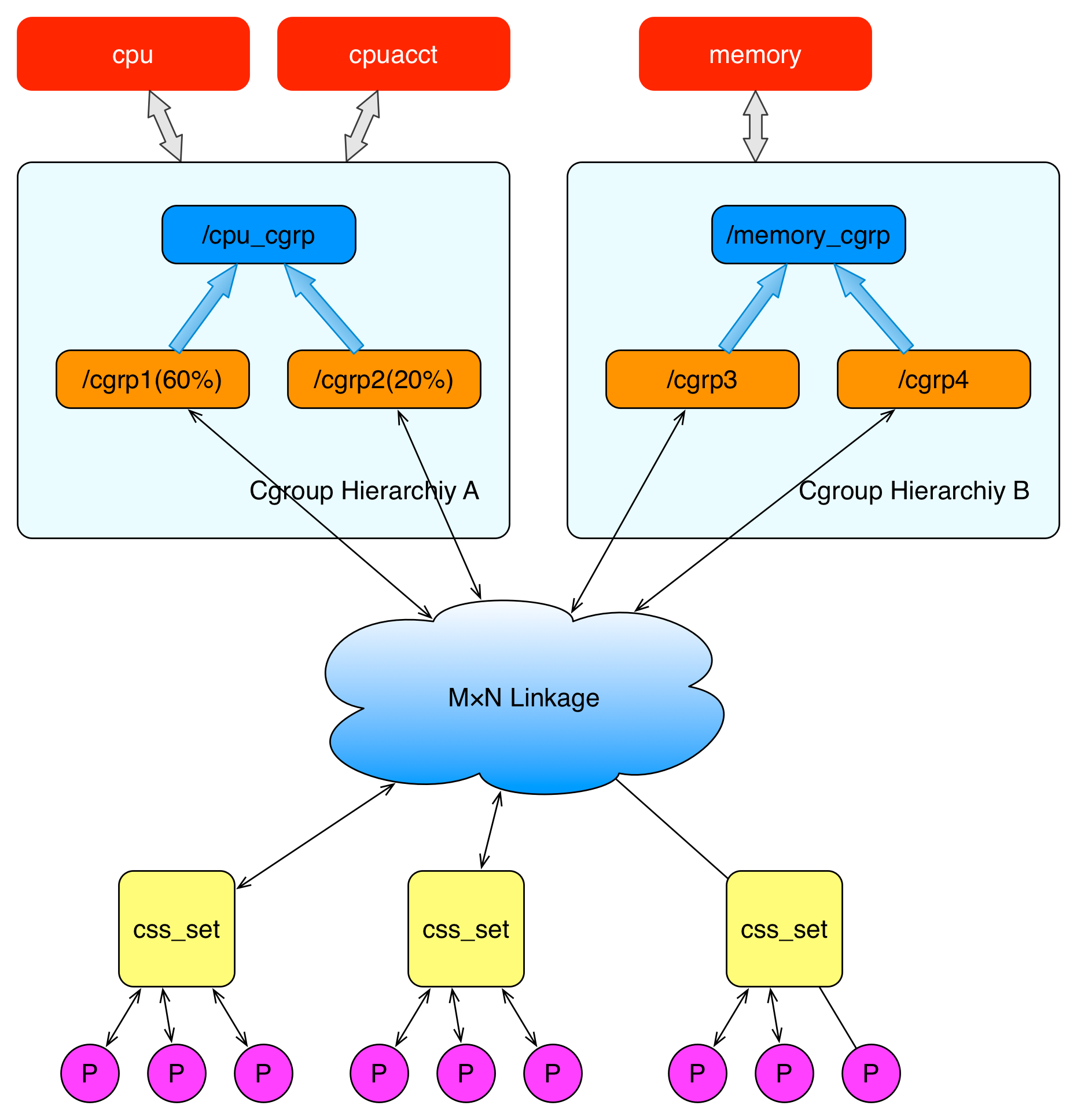
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。
一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
实践,
$ cgcreate abc:abc -g cpu:halfapi # 在 cpu 子系统下面创建了一个 halfapi 的子节点
$ echo 50000 > /cgroup/cpu/halfapi/cpu.cfs_quota_us # cpu.cfs_quota_us中的默认值是100000,写入50000表示只能使用50%的 cpu 运行时间
$ cgexec -g "cpu:/halfapi" ./halfapi.out >/dev/null 2>&1 # 最后在这个cgroups中启动这个能吃满cpu的for循环程序
UnionFS
UnionFS可以把文件系统上的多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。
UnionFS技术在Docker容器技术中的运用,首先体现在镜像(image)和容器(container)上。每一个Docker镜像都是一个只读的文件夹,当在容器中运行镜像时,Docker会自动挂载镜像中的、只读的文件目录,以及宿主机上一个临时的、可写的文件目录。容器中所有文件修改,都会写入这个临时目录里去。容器终结后,这个临时目录也会被相应删除。
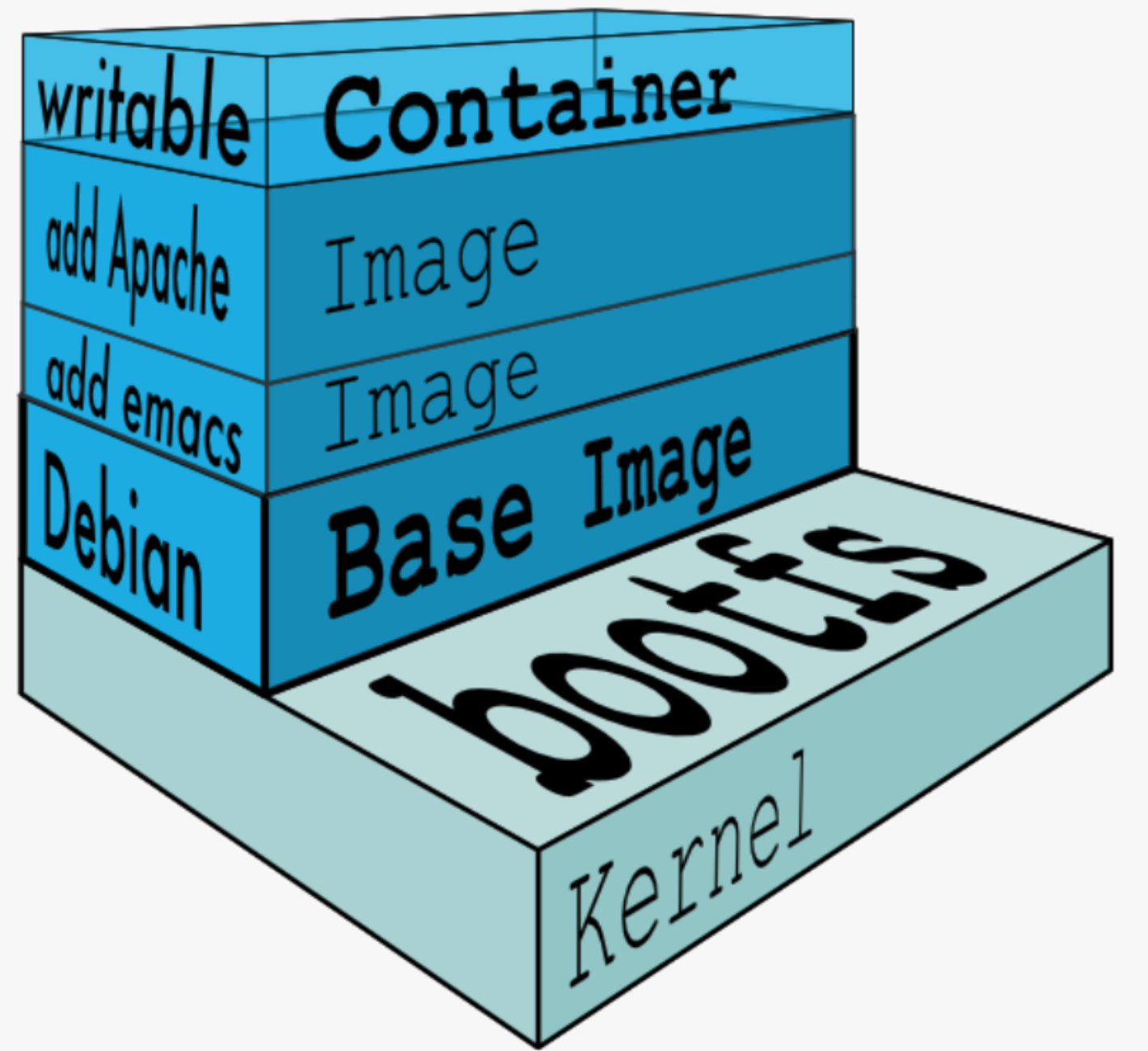
容器运行时,在挂载的临时目录中如果写入数据,还可以选择把这部分数据从临时目录中保存下来,这样就生成了一个新的镜像。Docker在保存新镜像时,会把它们两部分——原镜像和增量——都保存在新镜像中。其中新的增量部分,就被称为层(layer)。
上图,在debian上安装emacs,保存形成一个新的镜像。
架构
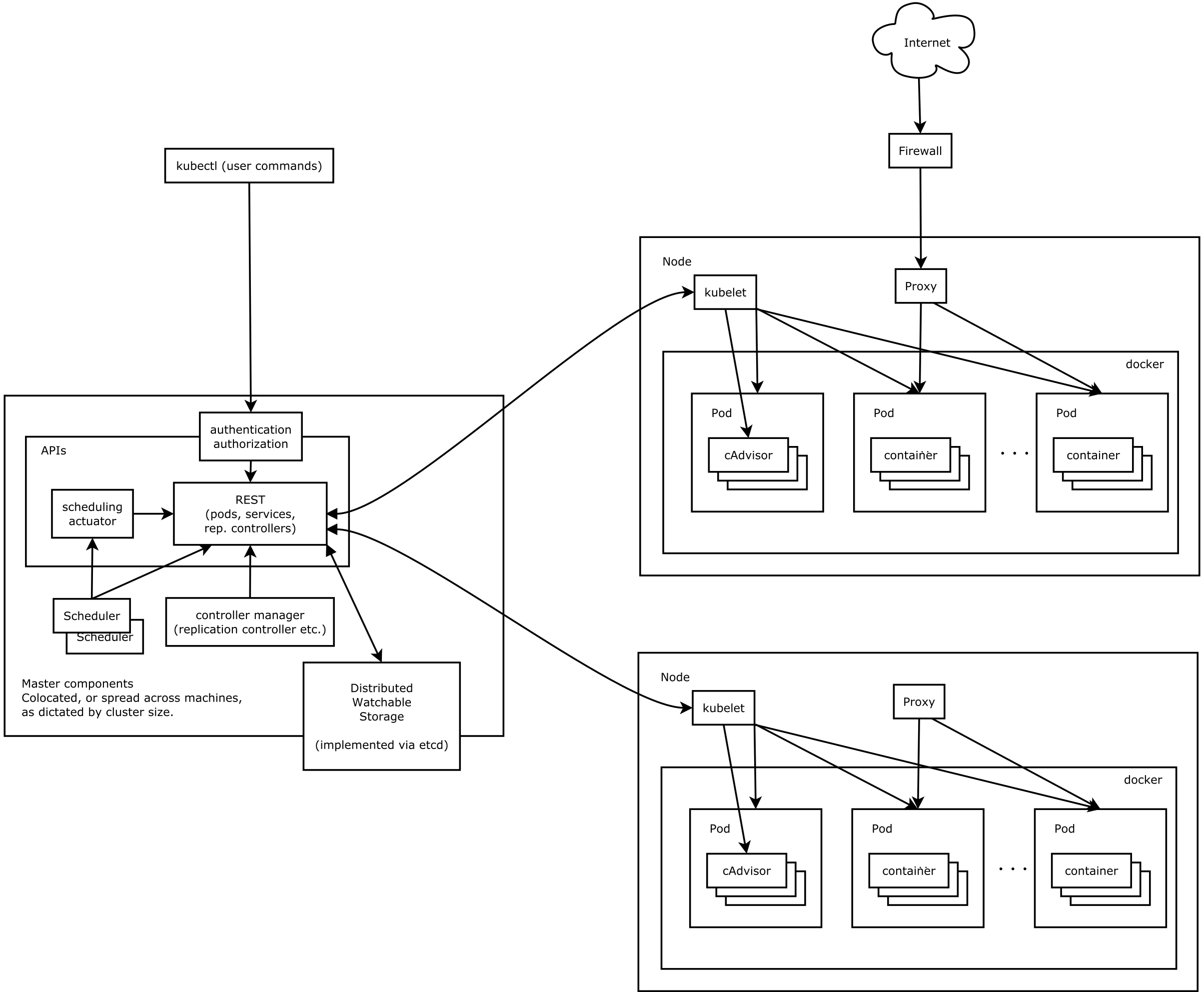
核心模块
| Module | Desc |
|---|---|
| etcd | 保存了整个集群的状态 |
| kube-apiserver | 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制 |
| kube-controller-manager | 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等 |
| kube-scheduler | 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上 |
| kubelet | 负责维持容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理 |
| Container runtime | 负责镜像管理以及 Pod 和容器的真正运行(CRI),默认的容器运行时为 Docker |
| kube-proxy | 负责为 Service 提供 cluster 内部的服务发现和负载均衡 |
Ad-ons
| Module | Desc |
|---|---|
| kube-dns | 负责为整个集群提供 DNS 服务 |
| Ingress Controller | 为服务提供外网入口 |
| Heapster | 提供资源监控 |
| Dashboard | 提供 GUI |
| Federation | 提供跨可用区的集群 |
| Fluentd-elasticsearch | 提供集群日志采集、存储与查询 |

istio 架构
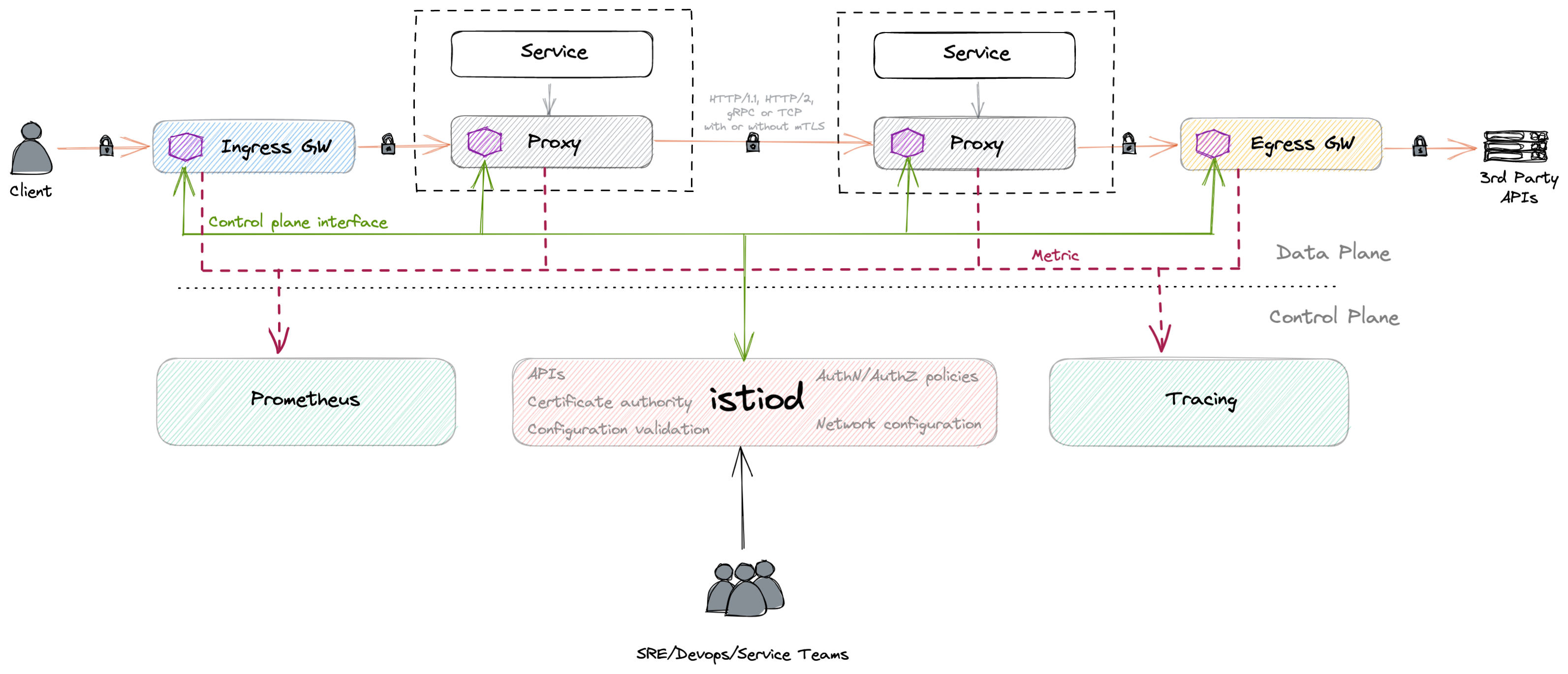
Service mesh 做的,也是软件工程中一直都在追求的事情:业务逻辑与控制逻辑的分离。在 Infra 层面实现,对开发以及技术的升级都很友好。
以 istio 为例,架构分为控制面和数据面,控制面提供用户的交互接口,诸如配置管理等工作。数据面最重要的组件是 Proxy,istio 选用的是 Envoy.
透明代理(transparent proxy)
Proxy 实现的最主要功能是“流量透明劫持”,即 Transparent Proxy.
Linux 内核实现了对 transparent proxy 的支持。
关键技术为,
一、routing table
当 packet 到达 linux 时,它或被 routed 走,或被 drop 掉,或 dst address 匹配到 local address,被 linux 网络协议栈接收,送到相应的进程处理。
那现在的问题是,如果 dst address 不是本机地址,则 packet 会被 routed 或 drop。linux 通过 routing table 解决了这个问题。
iptables -t mangle -I PREROUTING -p udp --dport 5301 -j MARK --set-mark 1
ip rule add fwmark 1 lookup 100
ip route add local 0.0.0.0/0 dev lo table 100
以上配置表示,
将所有发往 5031 端口的 UDP packets 打标记为 1.
第二条指令,将这些打完标记的 packets 通过 routing table 100 路由.
最后一行表示,routig table 100 路由的所有 IPV4 packets 都是本地的,即任何发往 5301 端口的 packet,不管 dst address 如何,都能被 linux 接收处理,从而避免被 routed 或 drop.
二、在 userspace 拦截 packets
通过第一步的配置,以下代码可以接收所有发往 5301 端口的 packets,不论 dst address 如何,
Socket s(AF_INET, SOCK_DGRAM, 0);
ComboAddress local("0.0.0.0", 5301);
ComboAddress remote(local);
SBind(s, local);
for(;;) {
string packet=SRecvfrom(s, 1500, remote);
cout<<"Received a packet from "<<remote.toStringWithPort()<<endl;
}
IP_TRANSPARENT 是一个 socket 选项,它允许,创建 listen fd 时,绑定一个 non-local 的 address
Socket s(AF_INET, SOCK_DGRAM, 0);
SSetsockopt(s, IPPROTO_IP, IP_TRANSPARENT, 1);
ComboAddress local("1.2.3.4", 5300);
ComboAddress remote("198.41.0.4", 53);
SBind(s, local);
SSendto(s, "hi!", remote);
四、iptables TPROXY target
以上,我们把流量转发到了一个绑定在特定端口的 socket 上,并且通过绑定 0.0.0.0 来看到了所有 traffic.
除此之外,iptables 提供了一个叫 TPROXY 的 target,它给我们提供了更加灵活的方式,把拦截的 traffic 发送到一个 local IP address,并且标记这些 traffic.
语法是,
iptables -t mangle -A PREROUTING -p tcp --dport 25 -j TPROXY \
--tproxy-mark 0x1/0x1 --on-port 10025 --on-ip 127.0.0.1
它的含义是,接收所有 dst port 为 25 的 TCP traffic,发送给监听在 127.0.0.1:10025 的进程,并且将 traffic 标记为 1.
通过上面的配置,我们就可以编写程序,绑定 127.0.0.1:10025 来接收发送给 25 端口的 packets 了。(仍然要设置 IP_TRANSPARENT)
五、如何拿到 source IP address
对于 TCP sockets,可以通过 getsockname() 拿到源IP和Port,示例,
Socket s(AF_INET, SOCK_STREAM, 0);
SSetsockopt(s, IPPROTO_IP, IP_TRANSPARENT, 1);
ComboAddress local("127.0.0.1", 10025);
SBind(s, local);
SListen(s, 128);
ComboAddress remote(local), orig(local);
int client = SAccept(s, remote);
cout<<"Got connection from "<<remote.toStringWithPort()<<endl;
SGetsockname(client, orig);
cout<<"Original destination: "<<orig.toStringWithPort()<<endl;
netfilter recap
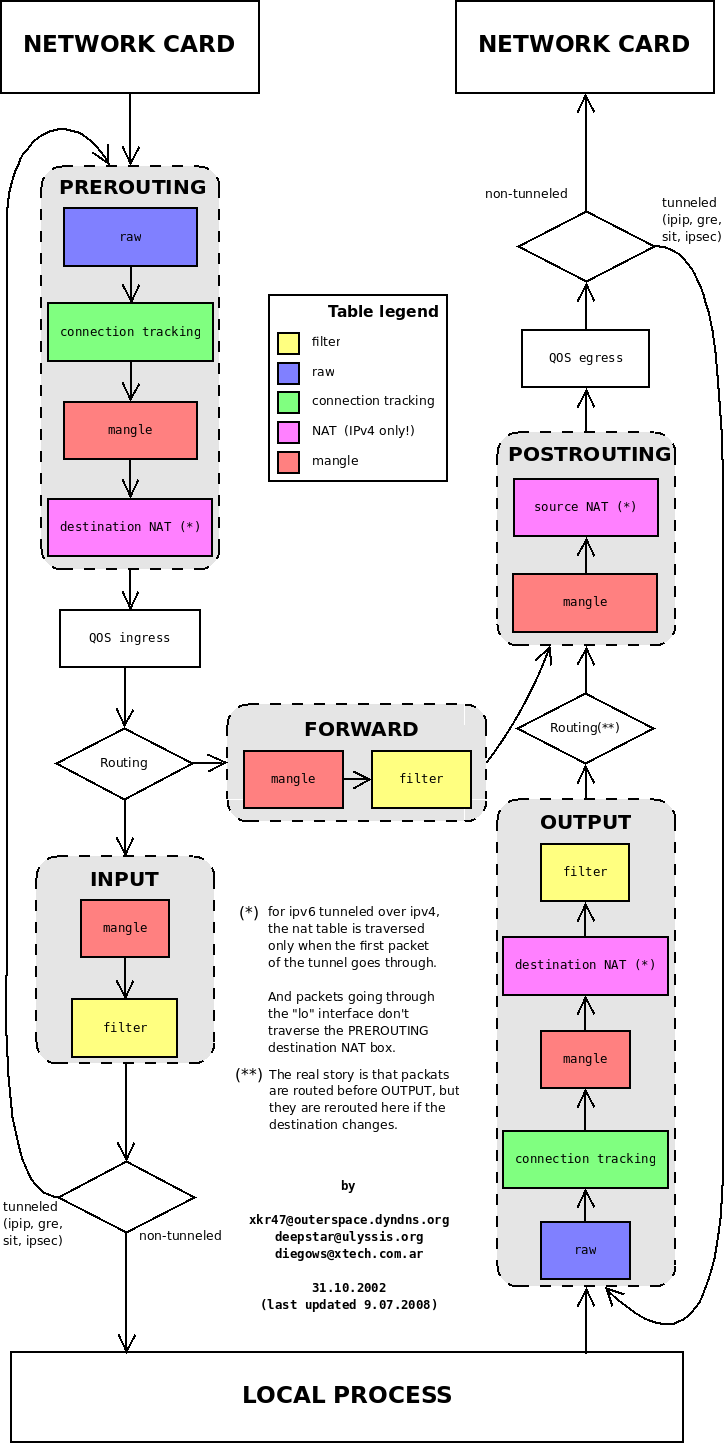
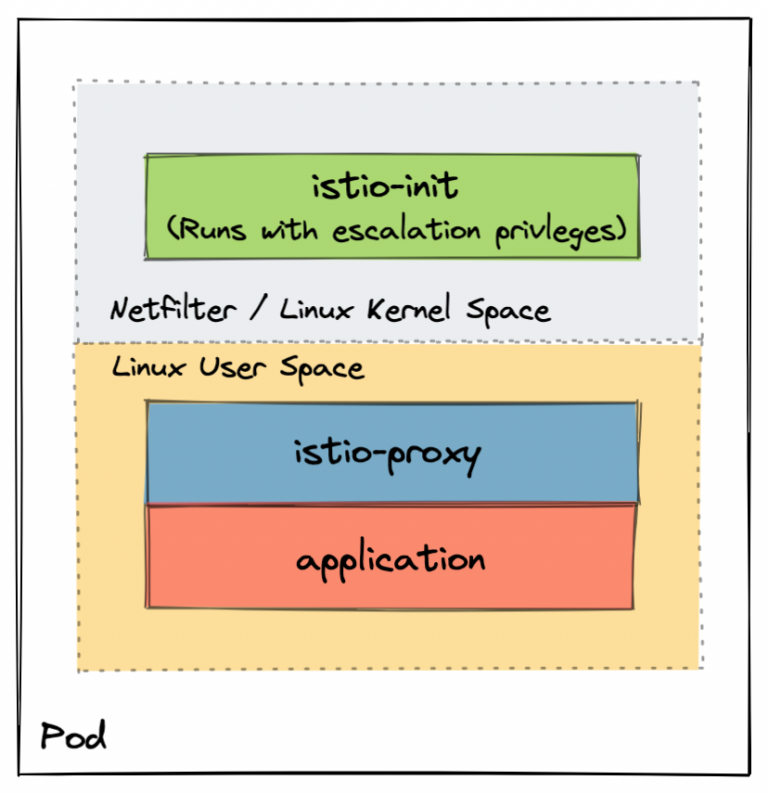
kubernetes & service mesh
istio-proxy(sidecar,实际是 envoy) 与应用程序运行在同一个 pod,
流量劫持一例:由 local pod 调用 remote pod 的过程,
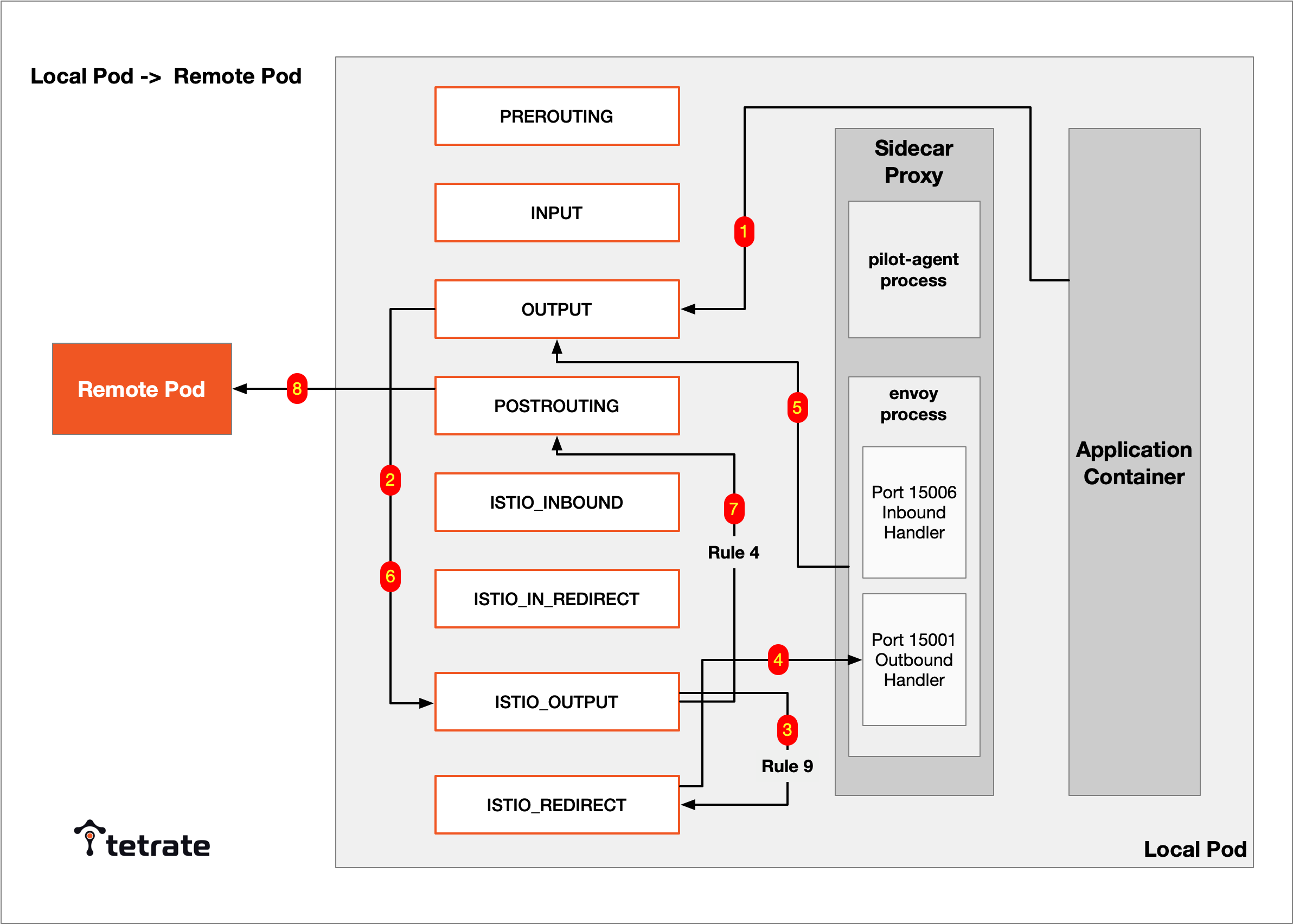
对 application 来说,它不知道 iptables 和 sidecar proxy 的存在,也因此被称为透明代理。
基础设施(Library and Service)
gRPC
所有的RPC实现,都是在解决这3个问题:
如何表示数据
不同语言,不同操作系统,不同硬件指令集,不同数据宽度、字节序。解决方案是各种序列化和反序列化协议。
如何传递数据
不仅传递参数和返回结果,还要处理如异常、超时、安全、认证授权、事务等信息交换的需求。专门有一个名词Wire Protocol来表示这种在两个Endpoint之间交换数据的行为。
如何表示方法
IDL(Interface Description Language)
gRPC基于HTTP/2和Protobuf序列化协议。
Protobuf
编码
- Varints,变长整型编码
通常情况,整形占的内存是一样大的,但是如果数据本身比较小的情况,高位都是浪费的。变长整形的设计是,每个字节的最高1位表示后续是否还跟有字节,有的话为1,无的话为0表示这是整数的最后一个字节了。其余7位存储数字。我们假设 int 类型占 4 个字节, 以标准的整型存储, 数字666的二进制表示应为,
00000000 00000000 00000010 10011010
而采用 Varints 编码, 其二进制形式为,
10011010 00000101
高 8 位的最高有效位为 1,代表其后还跟有有效字节,低 8 位的最高有效位为 0,代表其已是最后一个字节,由于 Protobuf 采用小端字节序存储数据,因此我们移除两个字节的最高有效位得到0011010 0000101,并交换字节序便得到101 0011010,转换为十进制,即是数字666.
- Zigzag
Varints用掉了最高位,对负数不适应,负数最高位是1,标志符号。
Zigzag 编码便是为了解决这个问题,Zigzag 编码的大致思想是首先对负数做一次变换,将其映射为一个正数,变换以后便可以使用 Varints 编码进行压缩,这里关键的一点在于变换的算法,首先算法必须是可逆的,即可以根据变换后的值计算出原始值,否则就无法解码,同时要求变换算法要尽可能简单,以避免影响 Protobuf 编码、解码的速度,我们假设 n 是一个 32 位类型的数字,则 Zigzag 编码的计算方式为,
(n << 1) ^ (n >> 31)
数据组织
Protobuf不是一个自描述的结构,它使用字段编号代替字段名,如果通信双方没有proto文件,是无法进行解码的。
进一步,Protobuf将消息类型(wire-type)做了划分,
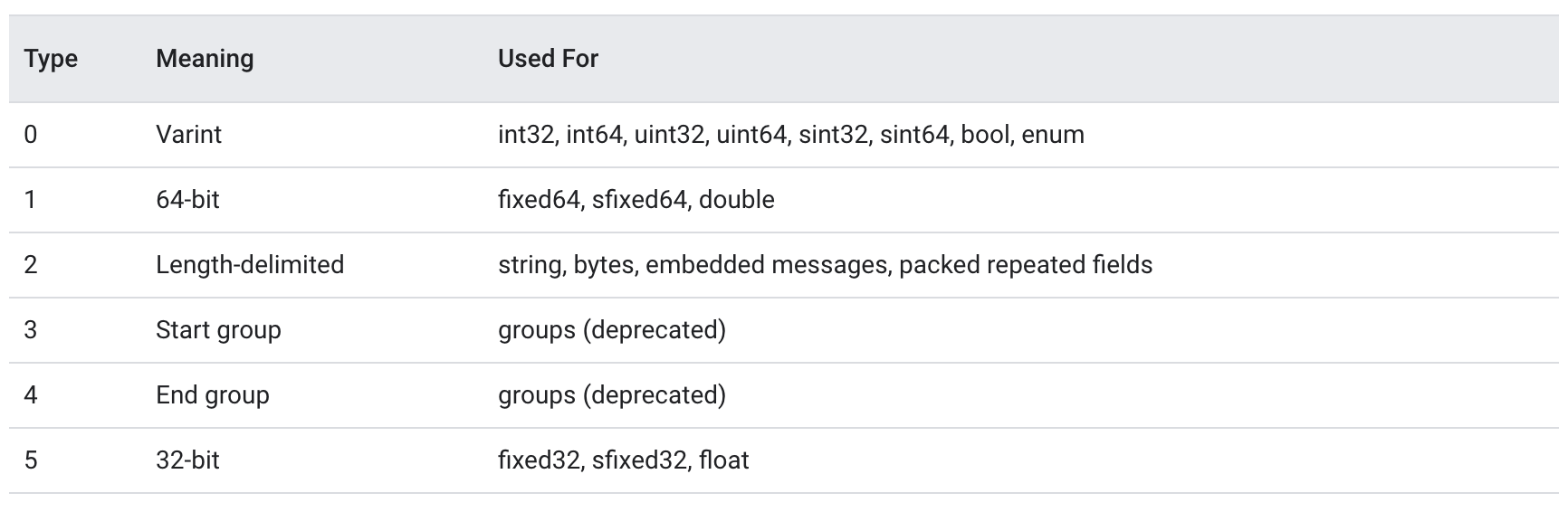
Protobuf除了存储字段的值之外, 还存储了字段的编号以及wire-type,具体的存储方式为(Protobuf采用小端字节序),
field_num << 3 | wire type
以下proto为例,看序列化后的完整二进制数据,
syntax = "proto3";
package pbTest;
message Request {
int32 age = 1;
}
假设 age 为 5,由于 age 在 proto 文件中定义的是 int32 类型, 因此序列化之后它的 wire type 为 0,其字段编号为 1,因此按照上面的计算方式,即 1 << 3 | 0, 所以其类型和字段编号的信息只占 1 个字节,即 00001000,后面跟上字段值 5 的 Varints 编码,所以整个结构体序列化之后为:

有了字段编号和 wire type,其后所跟的数据的长度便是确定的,因此 Protobuf 是一种非常紧密的数据组织格式,其不需要特别地加入额外的分隔符来分割一个消息字段,规避冗余的数据传输,提升通信的效率。
容错
超时与重试
场景:服务的暂时失败或超时
方案:
- 指数退避重试(Exponential Backoff retry)
- 接口幂等设计(针对timeout场景)
微服务架构下,
避免重试导致的请求级联放大问题
比如级联请求:A->B->C->D,D失败,若A/B/C都进行3次重试,则对D的总请求量3^3 = 27次,可能造成D的雪崩。
解决这个问题,可以全局约定,可重试的错误码和不可重试的错误码。对于overload类型的错误,不应该进行重试。
级联请求的超时时间设置
仍是A->B->C->D请求链路,若用户请求A的超时时间为10s,若A->B用了6s,B->C用了5秒,则已经超时了,C不需要再请求D了。
解决这个问题,是把timeout传递下去,将timeout- process time作为下一调的超时时间。
熔断降级
场景:服务持续失败
方案:降级处理,通常的方案是熔断,使用Circuit Breaker模式。以Hystrix为例。
Hystrix工作流程,
- circuit breaker有close, open, half-open 3个状态,正常处理close状态
- 使用10个1s-bucket的滚动窗口,统计过去一段时间请求的errors, latency, timeouts, rejections等指标
- 若指标超过配置阈值,circuit breaker由close转到open状态,reject请求
- 一段时间后,circuit breaker放行一个请求,这时处于half-open状态,该请求成功转到close状态,失败再转到open状态
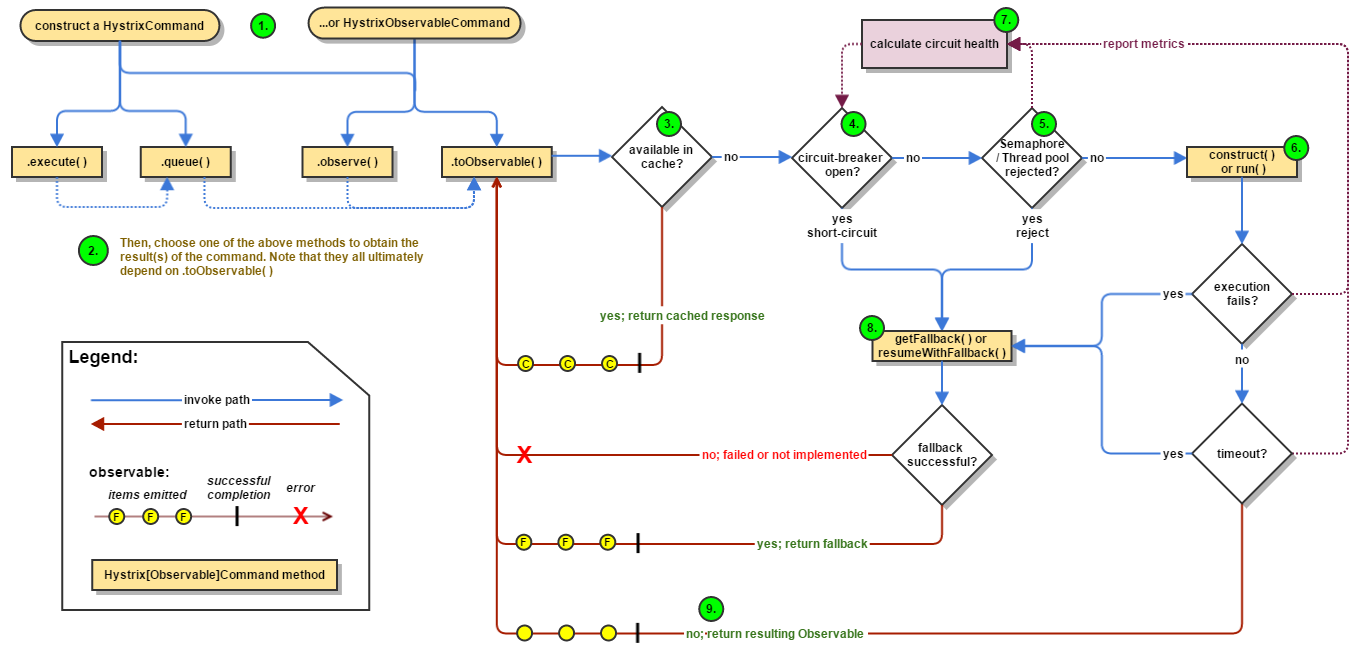
隔离设计
Hystrix还实现了bulkhead(舱壁)模式进行线程隔离。它为不同的下游请求设置不同的thread pool,当一个下游服务block时,只会hang住当前thread poll,不影响对其它服务的请求,

限流
令牌桶算法(token bucket)
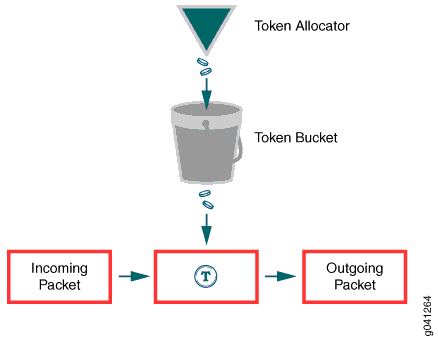
工作原理,
- bucket中的tokens是以固定时间间隔放进的
- bucket有最大容量
- 如果有一个ready的这packet(请求),会先从bucket中拿出一个token,然后再发送packet(执行请求)
- 如果bucket中没有token了,packet不能发送(失败或等待)
漏桶算法(leaky bucket)
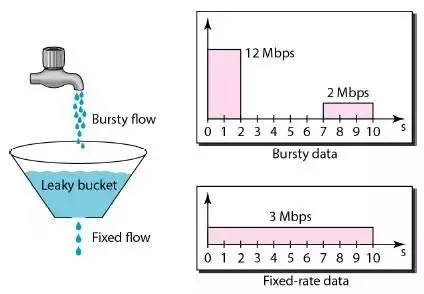
工作原理,
- packet(请求)放入bucket中
- bucket以恒定速度leak packets
- 通过leaky bucket,burst的流量会被转成uniform的流量
- 具体实现上,bucket是一个以一定速度出队的FIFO队列
令牌桶与漏桶比较
总的来说,token bucket要优于leaky bucket,
- token bucket中,如果bucket满了,token被丢掉,而在leaky bucket中是packets被丢掉
- token bucket允许burst流量,而leaky bucket只能支持固定qps
自适应限流(based on tcp congestion control)
参考TCP的Vegas,BBR等拥塞控制算法,
CDN
负载均衡
4层:LVS/DPVS
LVS: Linux Virtual Server
DPVS: DPDK-LVS
DPVS支持FNAT, DR, Tunnel, NAT, SNAT等转发模式,每种模式可以配置成one-arm或two-arm(client和real server两个逻辑端口)拓扑,可以配置成是否使用OSFP/ECMP,keepalived.
几种常用的模式,
Full-NAT (two-arm)

处理流程,
- Client访问VIP,发送给DPVS;
- DPVS将CIP(Client IP)修改为LIP(DPVS Local IP),源端口修改为某一端口,目的IP VIP修改为RIP(Real Server IP)
- RS收到数据包后,因为数据报文的目的IP为自己的IP,接收处理
- 处理后,查找ARP、路由表,原路返回给DPVS
- DPVS 将目的IP端口与源IP修改后返回client
优点,
RS不需要为DPVS做任何配置。
缺点,
CIP拿不到,可以通过TCP的TOA(IP层修改TCP层数据的示例,在Simpled面前,一切原则可破坏)
前面加个Keepalive(主从)或OSFP/ECMP(多主)可以实现DPVS的高可用。
DR (one-arm)

处理流程,
- Client访问VIP,发送给DPVS
- DPVS将DST MAC修改为某一个RS的MAC地址
- RS收到数据包后,因为数据帧的MAC地址是自己的地址,并且又在同一个局域网,接收处理
- 处理后,查找ARP、路由表,找到client的MAC地址后直接发给client。源IP地址还是VIP
优点,
RS将回包直接返client,减小DPVS流量压力。
缺点,
所有RS必须在同一个子网,搞不了大集群。
TUN (one-arm)

TUN模式把client请求包封装在一个IP tunnel里面,然后发送给RS节点,RS收到之后解开IP tunnel,处理响应,然后直接把包直接发送到client,不经过DPVS。
处理流程,
- Client请求VIP,发送到DPVS
- DPVS接收到client包,进行IP Tunnel封装。即在原有的包头加上IP Tunnel的包头。然后发送出去
- RS节点服务器根据IP Tunnel包头信息收到请求包,然后解开IP Tunnel包头信息,得到客户的请求包并进行处理
- 处理完毕之后,RS服务器将这个响应数据包发送给client。源IP地址还是VIP地址
缺点,
需要在RS上做配置,配置VIP和arp_ignore。
## for each Real Server ##
rs$ ifconfig tunl0 10.140.31.48 netmask 255.255.255.255 broadcast 10.140.31.48 up
rs$ sysctl -w net.ipv4.conf.tunl0.arp_ignore=1 # ignore ARP on tunl0
rs$ sysctl -w net.ipv4.conf.tunl0.rp_filter=2 # use loose source validation
优点,
- RS不需要在同一个子网(相较于DR模式)
- DPVS性能高(相对于Full-NAT模式)
公司目前是Full-NAT + Keepalive.
7层:Nginx/HAProxy
4层是通过IP和Port做的负载均衡,性能高但功能比较单一。而在7层可以使用应用层的信息,比如URL进行负载均衡,同时能实现更丰富的能力,比如WAF,Header重写,关键字过滤,请求重试,不同类型请求的路由等等。
Nginx的亮点是其插件化的设计,使用者可以用lua脚本等实现各种功能的插件。(比如google auth,可以做到这里,对后面的应用透明)
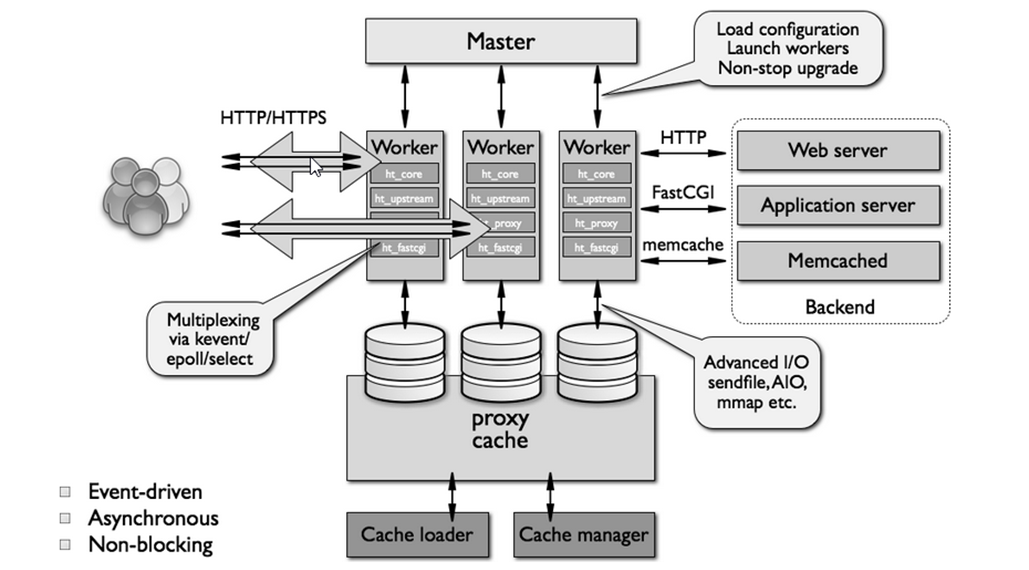
Nginx 采用的是多Reactor多进程的模型,Master将listen fd通过fork copy到Worker进程,Worker accept listen fd,创建conn fd并放到自己的事件循环。
这种模式下,当一个新的连接请求到达,所以进程的accept都会被唤醒,但只有一个成功返回conn fd,其它返回错误,这种现象叫惊群。通过epoll_ctl设置EPOLLEXCLUSIVE (since Linux 4.5)关键字,可以解决惊群问题。
另外也可能使用一个全局锁,获取全局锁的Worker才把listen fd放到自己的事件循环,当Worker的conn fd超过阈值则主动释放锁给其它Worker。
网关
网络I/O模型
Reactor模型
由Reactor和Handler两个模块构成。Reactor负责监听和分发事件,Handler执行I/O操作,并处理事件。
单Reactor单线程 - Redis

单线程模型,主要瓶颈在于handler,其中包括I/O和业务process两个过程。单reactor单线程的模型优点是简单,但不能承受process很重的业务,比如CPU密集,或者有blocking的调用,都不太适合,因为用不到多核的优势,性能堪忧。
Redis就没有这个问题,它的主要工作是内存访问,即非CPU密集,亦非blocking操作。
= v6.0版本后,redis支持了多线程模型,它解决的主要是I/O瓶颈的问题。
单Reactor多线程 - Go netpoller

多线程可以充分利用多核的优势,上图实际上read/write也可以放到worker线程中去做。
多Reactor多线程 - Nginx

多reactor模型是将listen fd copy到多个子线程中,由多个子线程共同accept新连接,它处理TCP短连接的能力更强。图中sub theads和worker threads是分开画的,实际他们可以是同一个线程,Nginx就是使用的这种模式。Nginx是多进程模型,worker进程既负责accept建立新连接,也负责处理conn fd上的事件。
BFF(Backends for Frontends)
网关不必为所有的前端提供无差别的服务,而是应该针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持。
缓存
缓存一致性
通常采用Cache aside的设计模式,
- 读成功后,顺便写缓存
- 写成功后,删除缓存
目前所有的缓存使用方式,都只能缓解但不能完全解决DB与缓存数据一致性的问题。
穿透/击穿/雪崩
缓存穿透:查询数据库中不存在的KEY
解决方案:
- 缓存不存在的KEY
- 加一层Bloom filter(多了一个数据库与Bloom filter的一致性问题)
缓存击穿:热点KEY删除(比如Cache aside,更新DB后删除缓存),大量请求直接打到DB
解决方案,
- 热点KEY更新,但不删除
- 请求DB时对KEY加互斥锁,拿到锁的服务或线程负责读数据库更新缓存KEY,减小对DB的并发
缓存雪崩:大量KEY同时过期或缓存故障时,请求全部打到DB,将DB打挂
解决方案,
- 在原有过期时间基础上,加一个随机delta,防止KEY同时过期
- 加限流,使部分用户不可用,缓慢放量进行缓存预热
四、事务
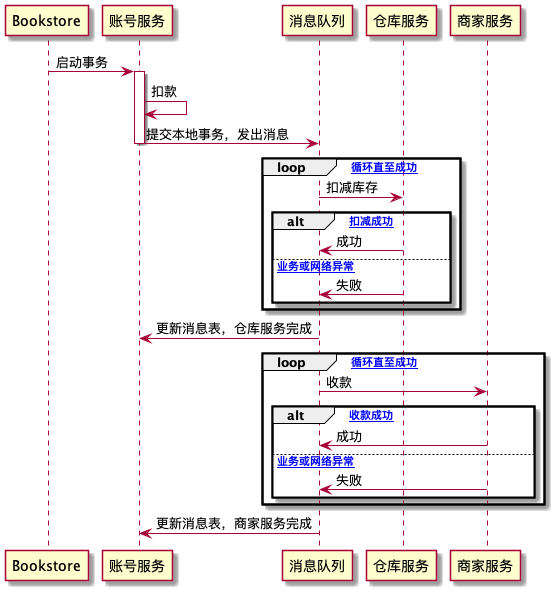
可靠事件队列
2008, Dan Pritchett, “Base: An Acid Alternative”
使用可靠事件队列的一次购物行为事务过程:账号服务扣款,商家服务收款,仓库服务扣库存
TCC(Try, Confirm/Cancel)
2007, Pat Helland, “Life beyond Distributed Transactions: an Apostate’s Opinion”
可靠事件队列的问题在于隔离性,它会导致超卖的问题。而对于刚性事务,只要隔离级别足够,比如Repeatable Read,则该问题可完全避免,只要加锁失败即可。
而TCC方案天生适合对隔离性有要求的业务。以下是购物使用TCC的事务过程

TCC类似2PC,但它不是在基础设施层面实现,而是在业务代码层面实现,对业务有比较大的侵入性。
五、安全
授权
安全的三个基础问题:“你是谁?”(认证)、“你能干什么?”(授权)以及“你如何证明?”(凭证)
RBAC
所有的访问控制模型,实质上都是在解决同一个问题:“谁(User)拥有什么权限(Authority)去操作(Operation)哪些资源(Resource)”。
RBAC(Role Based Access Control)模型,

RBAC 将权限从用户身上剥离,改为绑定到“角色”(Role)上,Permission在 RBAC 系统中的含义是“允许何种操作作用于哪些资源之上”。
Role完成User与Resource多对多关系的解耦,同样Permission完成Role与Resource多对多关系的解耦。
建立访问控制模型的基本目的是为了管理垂直权限和水平权限。垂直权限即功能权限,它比较简单,与实际的RBAC模式有高度对应关系。
但水平权限即数据权限管理起来则要困难许多,很难抽象与通用的,仅在角色层面控制并不能满足全部业务的需要,很多时候只能具体到用户,甚至要具体管理到发生数据的某一行、某一列之上,因此数据权限基本只能由信息系统自主来来完成,并不存在能放之四海皆准的通用数据权限框架。
Kubernetes 完全遵循了 RBAC 来进行服务访问控制。
OAuth2
最常用的授权码模式,

参考:OAuth2
凭证
认证授权通过后,用户会拿到一个Credentials(比如token),这个token放在哪里,有两种不同的方式,放在服务端亦或放在客户端。
Cookie-Session
Cookie-Session 方案,状态信息都存储于服务器,只要依靠客户端的同源策略和 HTTPS 的传输层安全,保证 Cookie 中的键值不被窃取而出现被冒认身份的情况,就能完全规避掉上下文信息在传输过程中被泄漏和篡改的风险。
在单机环境中是比较适合的,但分布式环境会有问题,
- 让所有节点都保障全量session信息,会有数据一致性问题,同时数据同步成本高
- 根据用户ID做哈希,用户每次路由到相同的节点,不复制session可用性得不到保障
JWT(JSON Web Tokens)
JWT是客户端存储认证授权信息的方案,JWT 只解决防篡改的问题,并不解决防泄漏的问题,因此token默认是不加密的。

JWT由Header, Payload, Signature三部分组成,header指定签名算法,payload存放认证授权相关信息,比如用户是谁,拥有哪些权限,token过期时间等。
签名算法,HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret),其中secret是服务端私有的密钥,它是防篡改的关键。
JWT要求每次请求都带上这些信息(比如可以放在HTTP Authorization/Bearer头里)
数字证书
HTTPS的安全性基于TLS,TLS使用非对称加密算法(如RSA)交换对称加密算法(如AES)的密钥(RSA基于大数分解,AES的性能高RSA几个数量级),但在通信链路程不安全的情况下,依然不能保证数据不被窃取或篡改,

问题的关键是,如何证明公钥是服务器下发的。通信双方达成信任(信息公钥是服务端发的),只有两种方式,
- 基于共同私密信息的信任,比如地下党对暗号
- 基于权威公证人的信任,比如遇到诈骗,打电话去公安局问问,公安局就是权威公证人
但网络中,不能假设通信双方一开始就认识,拥有共同的私密信息。所以只有2这一种解决方案,其核心是数字证书(Certificate Authority,CA),它是由权威机构签发的,公钥与某个人绑定关系的证明。
由于客户的机器上已经预置了这些权威 CA 中心本身的证书(根证书),使得我们能够在不依靠网络的前提下,使用根证书里面的公钥信息对其所签发的证书中的签名进行确认。
CA中包含认证机构的签名(可能通过客户端豫置的公钥验签,防篡改),以及证书持有人的公钥(既然通过验签没被改,那这个公钥一定是服务器下发的)。
安全注册流程
保证密码安全,越早处理越好,防止传输过程,像Nginx日志等中泄漏,
- 用户输入用户名,密码password
- 客户端将password做hash,具体:
client_hash = BCrypt(MD5(password) + salt),其中salt防止彩虹表攻击,BCrypt防止暴力破解 - 服务端拿到client_hash,使用安全随机数生成一个随机盐值,将这个随机盐和client_hash一起做hash,生成最终密文
- 将密文和这个随机盐值,一起放到数据库存储
六、基础设施
分布式锁
基于etcd/zookeeper实现
依赖etcd的一组机制,
- Lease机制:etcd 可以为存储的 Key-Value 对设置租约,当租约到期,Key-Value 将失效删除;同时也支持续约,通过客户端可以在租约到期之前续约,以避免 Key-Value 对过期失效。Lease 机制可以保证分布式锁的安全性,为锁对应的 Key 配置租约,即使锁的持有者因故障而不能主动释放锁,锁也会因租约到期而自动释放。
- Revision机制:每个 Key 带有一个 Revision 号,每进行一次事务便加一,它是全局唯一的,如初始值为 0,进行一次 put(key, value),Key 的 Revision 变为 1,同样的操作,再进行一次,Revision 变为 2;换成 key1 进行 put(key1, value) 操作,Revision 将变为 3;这种机制有一个作用:通过 Revision 的大小就可以知道写操作的顺序。在实现分布式锁时,多个客户端同时抢锁,根据 Revision 号大小依次获得锁,可以避免惊群效应,实现公平锁。
- Prefix机制:也称目录机制,例如,一个名为 /mylock 的锁,两个争抢它的客户端进行写操作,实际写入的 Key 分别为:key1=“/mylock/UUID1”,key2=“/mylock/UUID2”,其中,UUID 表示全局唯一的 ID,确保两个 Key 的唯一性。很显然,写操作都会成功,但返回的 Revision 不一样,那么,如何判断谁获得了锁呢?通过前缀“/mylock” 查询,返回包含两个 Key-Value 对的 Key-Value 列表,同时也包含它们的 Revision,通过 Revision 大小,客户端可以判断自己是否获得锁,如果抢锁失败,则等待锁释放(对应的 Key 被删除或者租约过期),然后再判断自己是否可以获得锁。
- Watch机制:Watch 机制支持监听某个固定的 Key,也支持监听一个范围(前缀机制),当被监听的 Key 或范围发生变化,客户端将收到通知;在实现分布式锁时,如果抢锁失败,可通过Prefix机制返回的 Key-Value 列表获得 Revision 比自己小且相差最小的 Key(称为 Pre-Key),对 Pre-Key 进行监听,因为只有它释放锁,自己才能获得锁,如果监听到 Pre-Key 的 DELETE 事件,则说明 Pre-Key 已经释放,自己已经持有锁(只watch一个pre-key,避免惊群)。
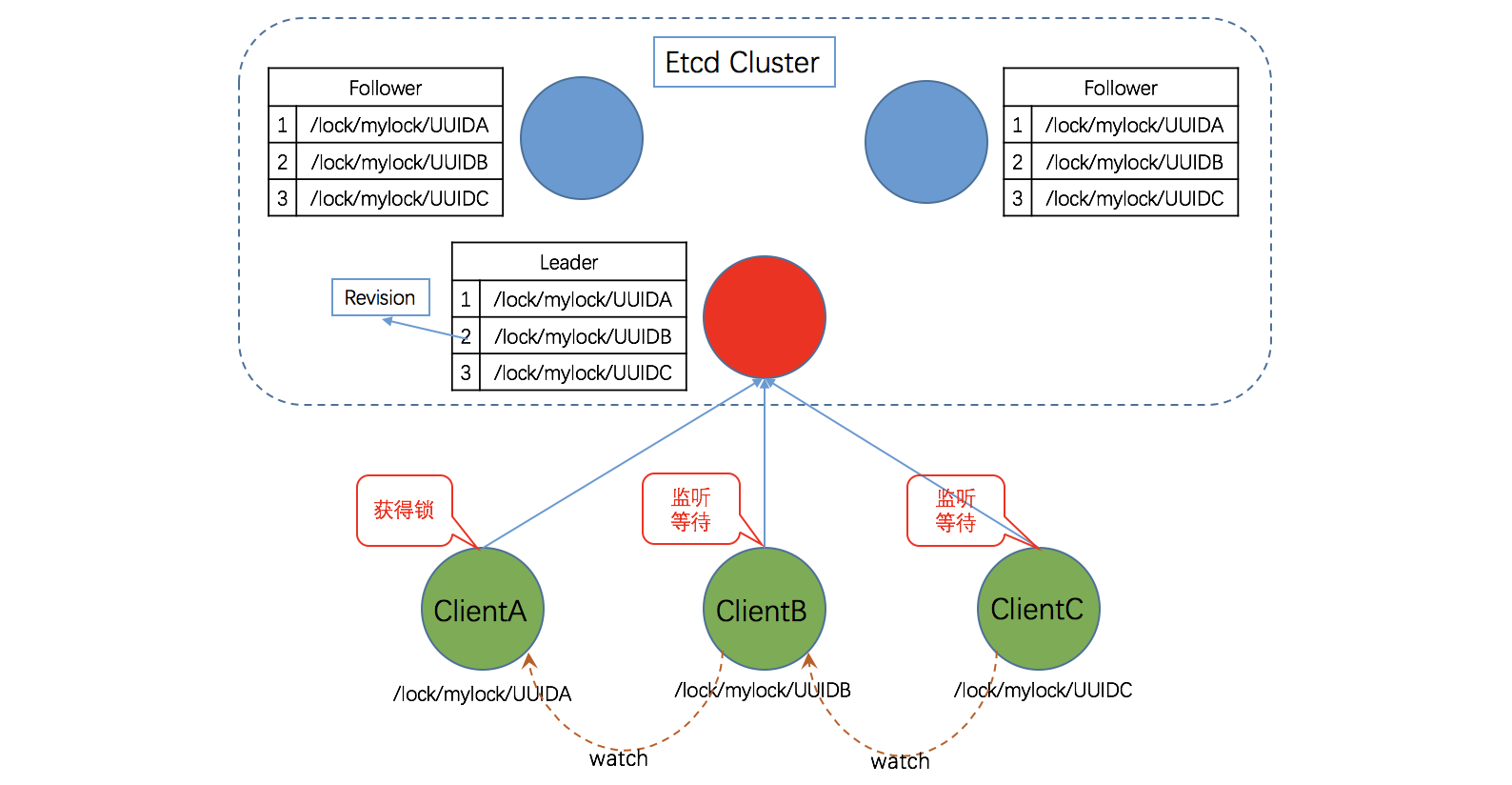
zookeeper的分布式锁实现与etcd基本一致,其核心亦是允许创建临时顺序节点(EPHEMERAL_SEQUENTIAL)和watch机制。
基于redis实现
Redis官方给的方案是redlock,使用多个redis实例保障高可用,对这个方案争议很大,因此只讨论单机上的实现,
SET resource_name my_random_value NX PX 30000
- resource_name:资源名称,可根据不同的业务区分不同的锁
- my_random_value:全局唯一值,用于释放锁的校验,防止错误释放别人的锁
- NX:key不存在时设置成功,key存在则设置不成功
- PX:超时时间,防止死锁
基于MySQL实现
表结构
CREATE TABLE `tb_distributed_lock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`lock_key` varchar(64) NOT NULL COMMENT '锁Key',
`owner` char(36) NOT NULL COMMENT '锁的持有者',
`expire_seconds` int(11) NOT NULL COMMENT '过期时间,单位为秒',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `ukey_lock_key_owner` (`lock_key`,`owner`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分布式锁'
获取锁
insert into tb_distributed_lock(lock_key, owner, expire_seconds)
select :lockKey, :owner, :expireSeconds
from (select 1) as T
where :parallelNum > (
select count(id)
from tb_distributed_lock
where lock_key = :lockKey and expire_seconds >= TIMESTAMPDIFF(SECOND, create_time, NOW())
)
插入时检查lockKey当前有效锁的数量是否小于parallelNum,是则允许插入。 根据插入语句返回影响的行数判断是否成功占有锁。
释放锁
delete from tb_distributed_lock where lock_key = :lockKey and owner = :owner
owner使用UUID生成保证唯一性,确保自己只能释放自己占有的锁。
全局唯一ID
Linux /dev/urandom
直接读/dev/urandom,字节转INT64即可。产生的是真随机数,单机性能一般。
Snowflake

生成一个UNSIGNED INT64。最高位为1,表示正整数,接下来41位表示从某个选定的epoch后经过的时间,使用milliseconds表示。接下来10位用作machine ID,防止不同machine产生的id重复。最后12位用于存储sequence number(per machine per ms)。
存在的问题,
- machine的时针回拨会导致产生重复的id
- 10位machine id,只能表示1024个实例,频繁重启用光怎么办
Baidu UidGenerator提供了一个解决思路,它通过借用未来时间来解决sequence天然存在的并发限制。

- delta seconds(28 bits) 表示从某时间开始的delta ms,28位可以用8.7年(如果生成QPS过高,会借用未来时间,过低则delta推进速度小于物理时钟的推进速度,导致使用过去的时间,总之不再能用来反应真实的业务发生时间)
- worker id (22 bits),支持机器重启420w次
这个解决方案能用,但设计不太优雅。它搞了太多假设:假设整个软件生命周期不足8.7年(重启换了machine id可以续命),假设期间重启次数不超过420w次。
延时队列
基于Kafka
设计一组不同延时时间的topic,如1min,5min,30min,实现简单但精度不太行,只能支持有限的延时时间。
基于Redis sorted set
ZADD时使用希望延时执行的时间戳作为作为score,读取时ZRANGE pick一条score最小的,如果没到时间则等待下一循环检测,如果已经到时间了,则ZREM取出来执行(高版本有ZMPOP)。

时间轮算法
Redis sorted set方案,任务插入是 的,读取是
的,读取是 的。
的。
而时间轮算法可以实现的插入和读取,性能更优。
简单时间轮
时间轮中存储任务的是一个环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表。定时任务列表是一个环形的双向链表,链表中的每一项表示的都是定时任务项,其中封装了真正的定时任务。
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。时间轮的时间格个数是固定的,可用 wheelSize 来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs×wheelSize 计算得出。
时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime 是 tickMs 的整数倍。currentTime指向的地方是表示到期的时间格,表示需要处理的时间格所对应的链表中的所有任务。
如下图是一个tickMs为1s,wheelSize等于10的时间轮,每一格里面放的是一个定时任务链表,链表里面存有真正的任务项:

初始情况下表盘指针 currentTime 指向时间格0,若时间轮的 tickMs 为 1ms 且 wheelSize 等于10,那么interval则等于10s。如下图此时有一个定时为2s的任务插进来会存放到时间格为2的任务链表中,用红色标记。随着时间的不断推移,指针 currentTime 不断向前推进,如果过了2s,那么 currentTime 会指向时间格2的位置,会将此时间格的任务链表获取出来处理。
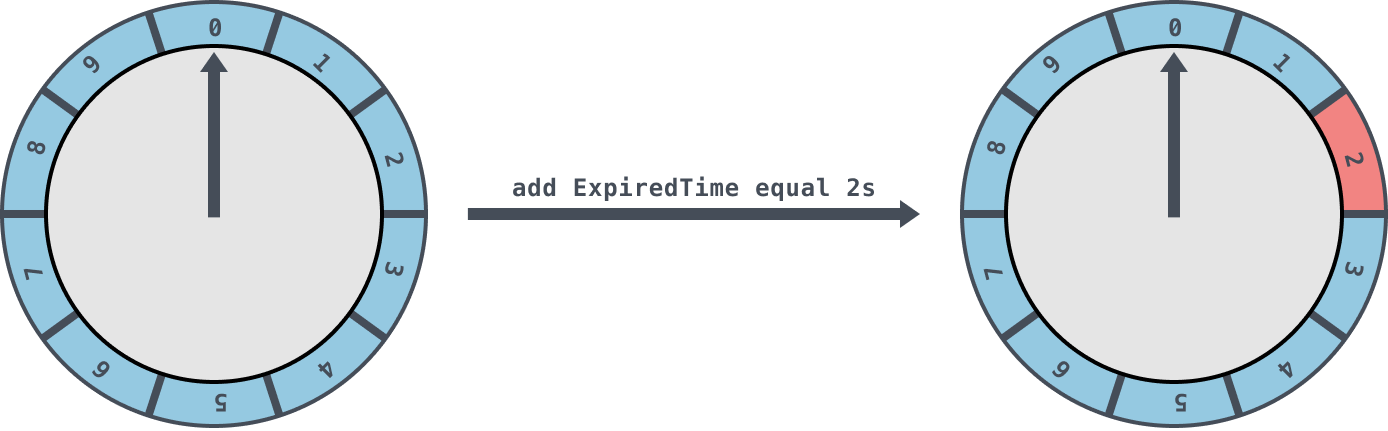
如果当前的指针 currentTime 指向的是2,此时如果插入一个9s的任务进来,那么新来的任务会服用原来的时间格链表,会存放到时间格1中
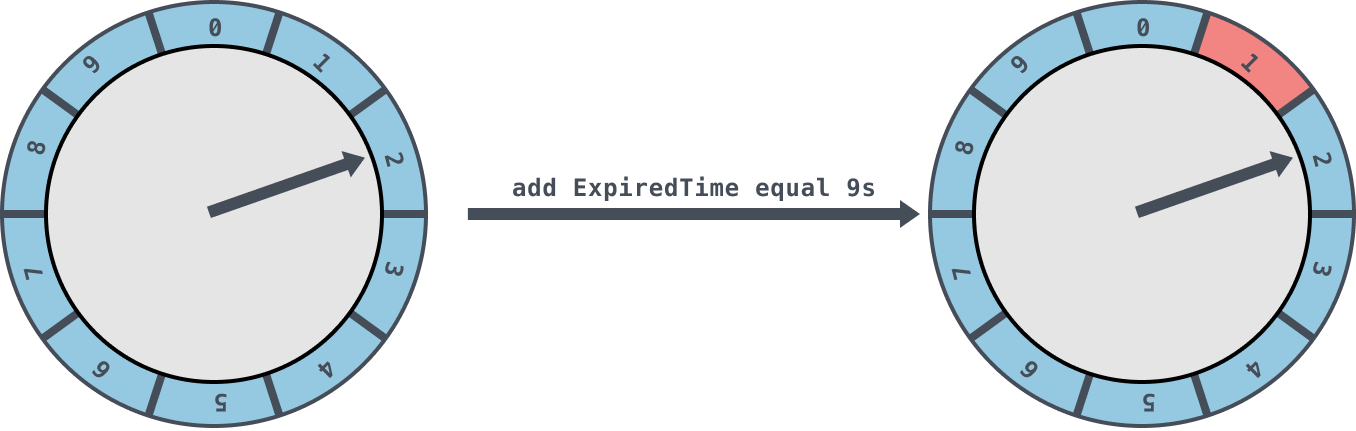
这个简单时间轮只有一层,允许的延时范围在 currentTime 和 currentTime+interval 之间。
层级时间轮
如图是一个两层的时间轮,第二层时间轮也是由10个时间格组成,每个时间格的跨度是10s。第二层的时间轮的 tickMs 为第一层时间轮的 interval,即10s。每一层时间轮的 wheelSize 是固定的,都是10,那么第二层的时间轮的总体时间跨度 interval 为100s。
图中展示了每个时间格对应的过期时间范围, 第二层时间轮的第0个时间格的过期时间范围是 [0,9]。也就是说,第二层时间轮的一个时间格就可以表示第一层时间轮的所有(10个)时间格。
如果向该时间轮中添加一个15s的任务,那么当第一层时间轮容纳不下时,进入第二层时间轮,并插入到过期时间为[10,19]的时间格中。

随着时间的流逝,当原本15s的任务还剩下5s的时候,这里就有一个时间轮降级的操作,此时第一层时间轮的总体时间跨度已足够,此任务被添加到第一层时间轮到期时间为5的时间格中,之后再经历5s后,此任务真正到期,最终执行相应的到期操作。
中间件
Redis & Codis & Redis Cluster
数据类型
| 数据类型 | 数据结构 |
|---|---|
| string | int, SDS(Simple Dynamic String) |
| list | quicklist |
| hash | ziplist(小数据量时), hashtable |
| set | intset(小数据量时), hashtable |
| sorted set | skip list(score rank,有序性), ziplist(小数据量时,代替hashtable), hashtable(通过score取keys) |
| bitmap | 基于redis string |
| GeoHash | 基于redis sorted set |
| HyperLogLog | |
| stream |
网络模型
- < v6.0 单Reactor单线程模型(仅指网络线程,不包含backgroup线程:如负责key过期的线程)
- >= v6.0 单Reactor多线程模型,提升网络I/O并发性能(单线程的瓶颈在网络I/O,不在读写内在本身)
单Reactor单线程模型不太适合计算密集型,它不能利用多核心的优势。也不适合有block的线程,会降低整体吞吐。但Redis都是内存读写操作,因此即非计算密集也非block应用,比较适合单Reactor单线程,因为它实现起来最简单,不需要考虑线程同步的问题。
Redis的瓶颈在1)内存访问速度,2)网络I/O大量占用CPU时间,单Reactor多线程模型是对2)的优化,充分利用多核优势。同时应该避免大KEY,大KEY会导致I/O线程block,使其它KEY访问的latency变高,影响整体性能(同时如果只使用其中的部分数据,还存在I/O浪费)。
refer: 网关
可用性:持久化和副本
持久化,
- AOF(Append Only File)日志
- 快照(COW:Copy On Write)
副本机制,
- Redis的主从副本是异步复制的,发生网络分区时依然可以提供服务,它牺牲了一致性(最终一致)
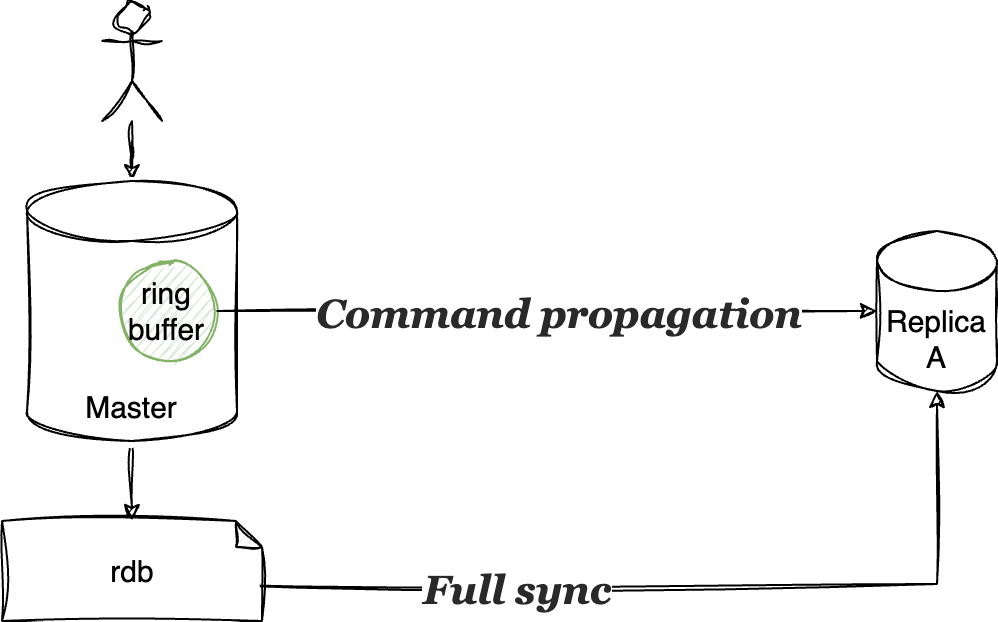
- 主从复制分两种情况,1)slave通过rdb文件全量load,2)增量更新,通过master上的一个ring buffer
如果slave消费很慢,而master上的ring buffer满了怎么办呢?
这时master并不停止服务,而是覆盖写入,慢的slave恢复后,发现自己offset的数据没了,会重新走先rdb全量复制,再增量复制的流程。
Transaction, Pipeline
Redis transaction通过MULTI+EXEC/DISCARD和WATCH实现,其ACID特性,
- A: 满足一定原子性:事务中的command全都会被按入队顺序执行,并且不会被其它事务的command插入。但不支持回滚,也就是不能保证所有命令都成功执行(比如执行时发现参数类型错误的情况)
- I: 满足。使用WATCH机制(事务执行前,WATCH一个或多个键的值变化情况,当事务调用EXEC命令执行时,WATCH机制先检查监控的键是否被其它客户端修改)
- D: 不满足。内存数据库,不保证持久性,即使开启了RDB或AOF功能(no、everysec 和 always都存在数据丢失的可能)
Pipeline与transaction的区别是,pipleline仅提供client batch提交commands的能力,这些commands提交到server端时,并不保证不被其它client的command插入其中,即其执行跟transaction不一样,并不保证原子性。
KEY过期策略
设置过期的KEY被放入一个单独的dict中,进行惰性删除,
- 当客户端访问该KEY时,进行过期检查,如果过期则删除之
- 使用贪心算法,定期扫描删除过期KEY(单独一个线程)
- 从过期dict中随机选出20个KEY
- 删除这20个KEY中已经过期的
- 如果重复KEY的比例超过1/4,则重复步骤1
- 这个循环有一个上限(25ms)
KEY的过期时间应当加一个随机值,避免大量KEY同时过期。slave中的过期线程是关闭的,它通过同步master的删除command进行删除。
内存淘汰机制
refer: LRU & LFU
扩展性:Codis,Redis Cluster
Codis
Codis采用的是中心化架构,引入了一个Codis Proxy组件,一个一致性的存储(通常etcd或zookeeper)。
KEY在codis中被划到1024个slot(hash partition),划分算法是,
hash = crc32(key)
slot_index = hash % 1024 // 1024是codis的默认配置,不建议改动
etcd中保存着slot到redis实例间的映射关系,这份关系同步到codis proxy上,codis proxy通过对key计算hash定位到slot,并通过映射关系将请求转发到真正的redis实例。
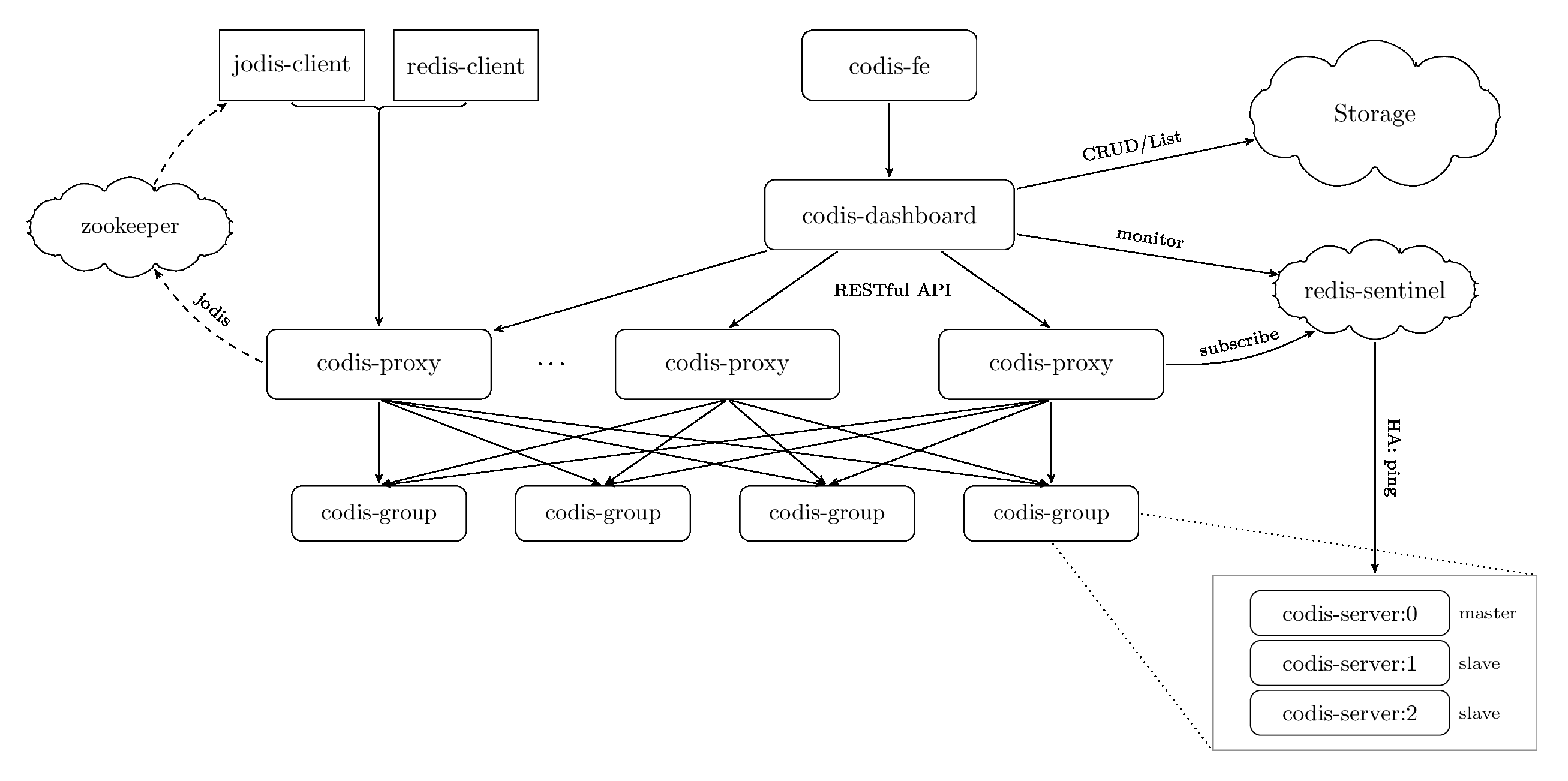
中心化架构的优点是实现简单,但它的缺点亦很明显,
- 增加了codis proxy的中间层,请求响应慢了
- 需要额外运维一套etcd集群
- 可用性仍依赖redis sentinel机制
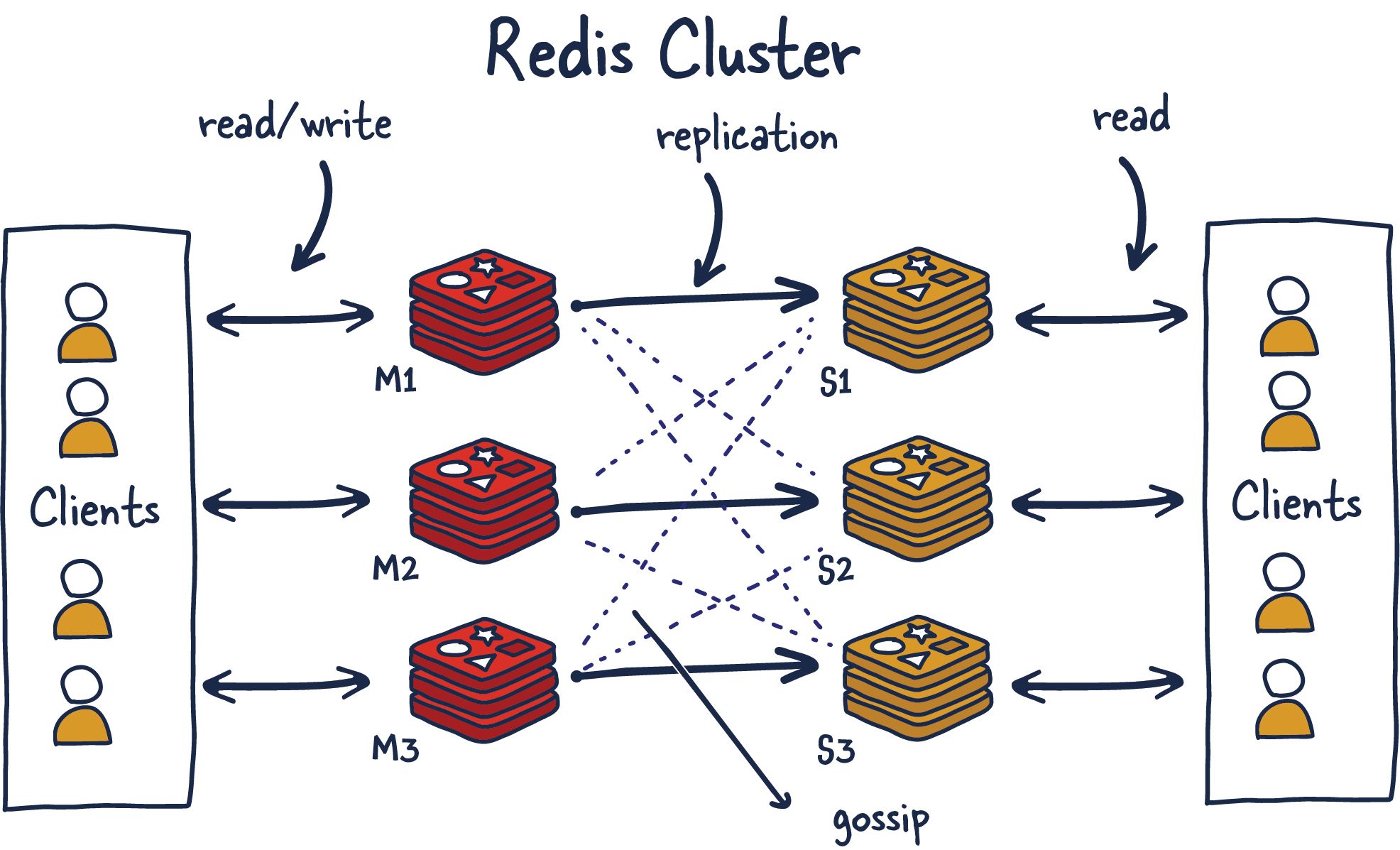
Redis Cluster
Redis Cluster仍然使用hash partition,它有16384个slot,分区算法是crc16(key) % 16384.
但Redis Cluster是P2P架构的,每个redis实例上面都通过gossip维护了slot到redis实例的映射。并且每个redis实例都可以serve客户端的请求。Redis Cluster中,只有副本数据,没有副本(slave)节点,它所有节点都是对等的,即它的高可用不需要依赖sentinel机制。
P2P的特点是,架构看着超级简单,代码实现起来却超级难。
Kafka
文件结构
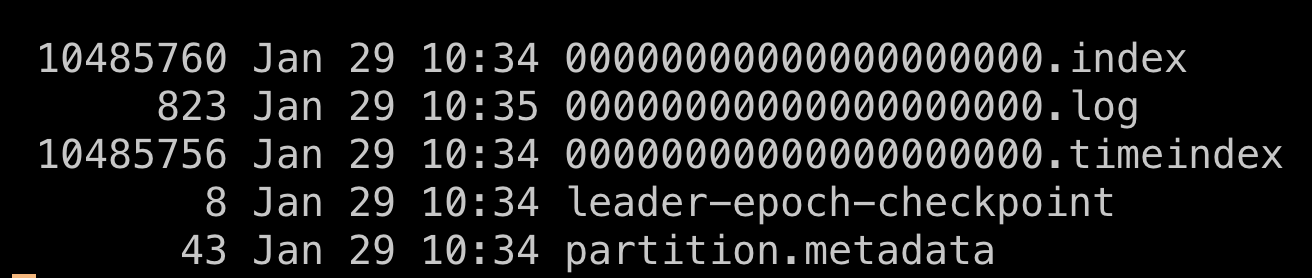
Topic数据分partition(默认round-robin,推荐),每个partition在broker上,由segments构成。

segment文件是append only顺序写入的,同时刻每个partition只有一个segment是active的,由它serve写入,其它都是inactive。单个segment文件的大小受两个参数控制,
- log.segment.bytes 默认1G
- log.segment.ms 默认保存一周
对于每个inactive segments,broker都会打开,因此要注意调整broker机器的文件描述符限制。
segments文件是有索引的,有两级索引,来支持consumer的指定offset消费,
- offset到segment文件位置的索引:kafka通过offset在segment中定位中消费的位置
- timestamp到offset的索引:kafka通过一个timestamp找到offset,进而定位消费位置
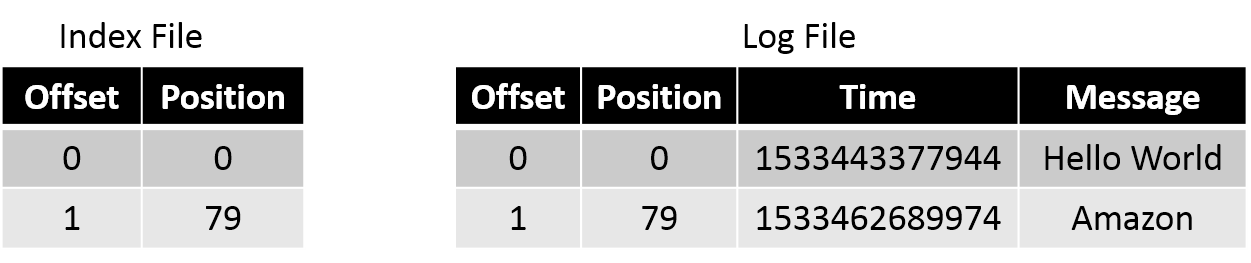
以下,其中.log是数据文件,.index是.log的索引文件(稀疏索引),.timeindex是.index的索引文件,
高可用原理
高可用的唯一办法是副本,kafka副本写入采用的是primary copy模式,即写入只发生在leader,由leader负责数据同步到follower。
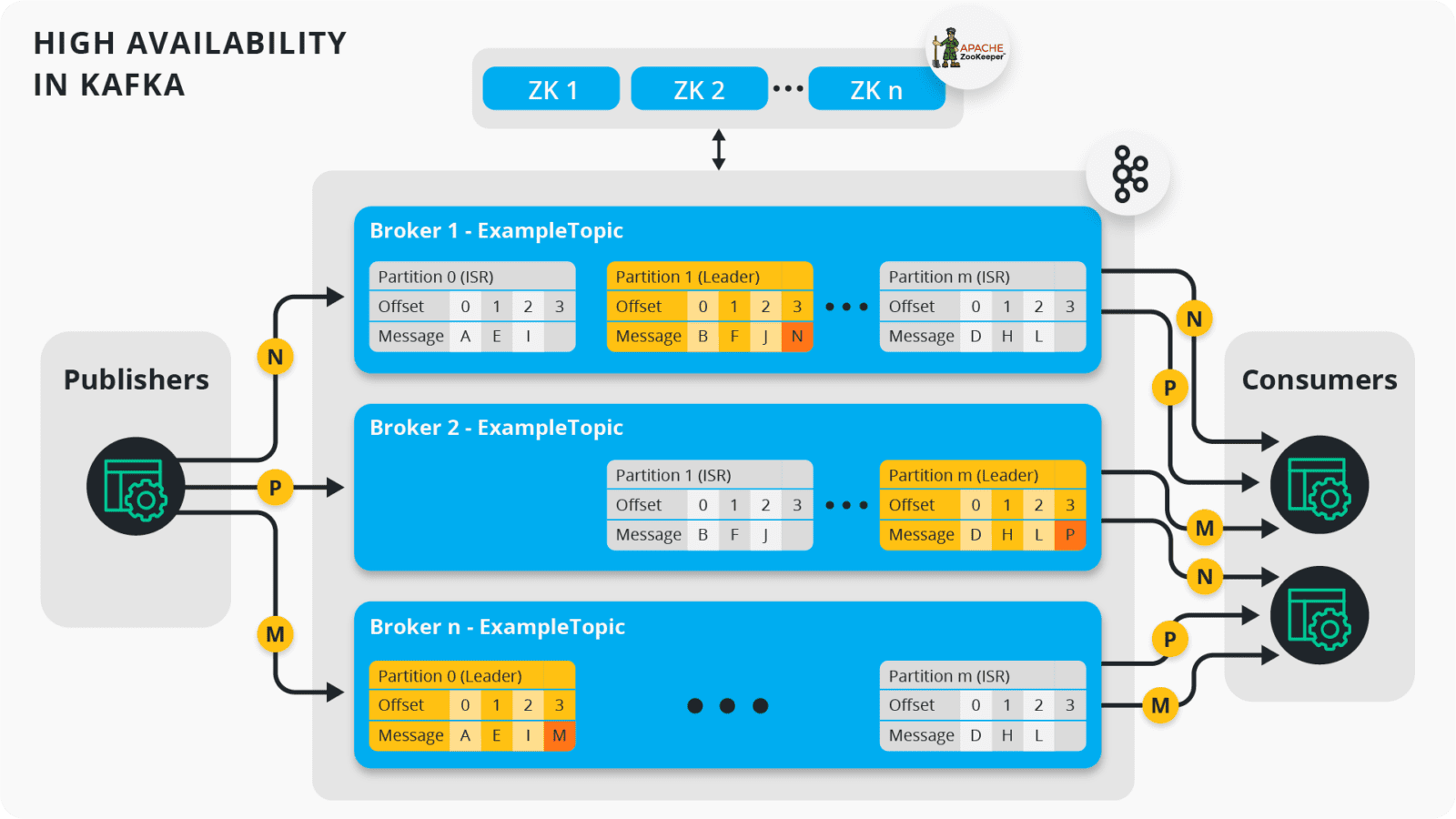
以上即实现了kafka高可用,原理很简单,靠zookeeper的一致性能力。但高可用下仍有问题要解决,即leader切换时的数据一致性问题。(注意这里zk只作选主用,而非像tikv一样,作为日志复制状态机,完成数据本身的一致性写)
kafka的leader选举是通过zookeeper完成的,但并不是所有副本都参与选举,只有在ISR队列中的副本才能参与leader选举。
ISR(In-Sync Replica)指的是数据同步的进度跟的上leader的副本,“进度是否跟的上leader”可以量化,
- replica.lag.time.max.ms: 表示follower副本多久没从leader fetch数据,超过这个阈值算作跟不上
- replica.lag.max.messsages: 表示follower副本落后leader多少lag,超过这个阈值算作跟不上
producer写入有个wait_for_all的选项,指的是等待ISR队列中所有的副本都同步成功才返回client成功,并不是指所有副本。
另外kafka还有个HW(High watermark: is the offset of the last message that was successfully copied to all of the log’s replicas(ISR))机制,对于高于HW offset的数据,consumer是不可见的。
所以,consumer可以通过HW避免读到leader收到,但未同步完成的数据,因此就实现了leader切换后数据一致的问题,因为ISR队列中replica都至少持有consumer可见的最新数据。
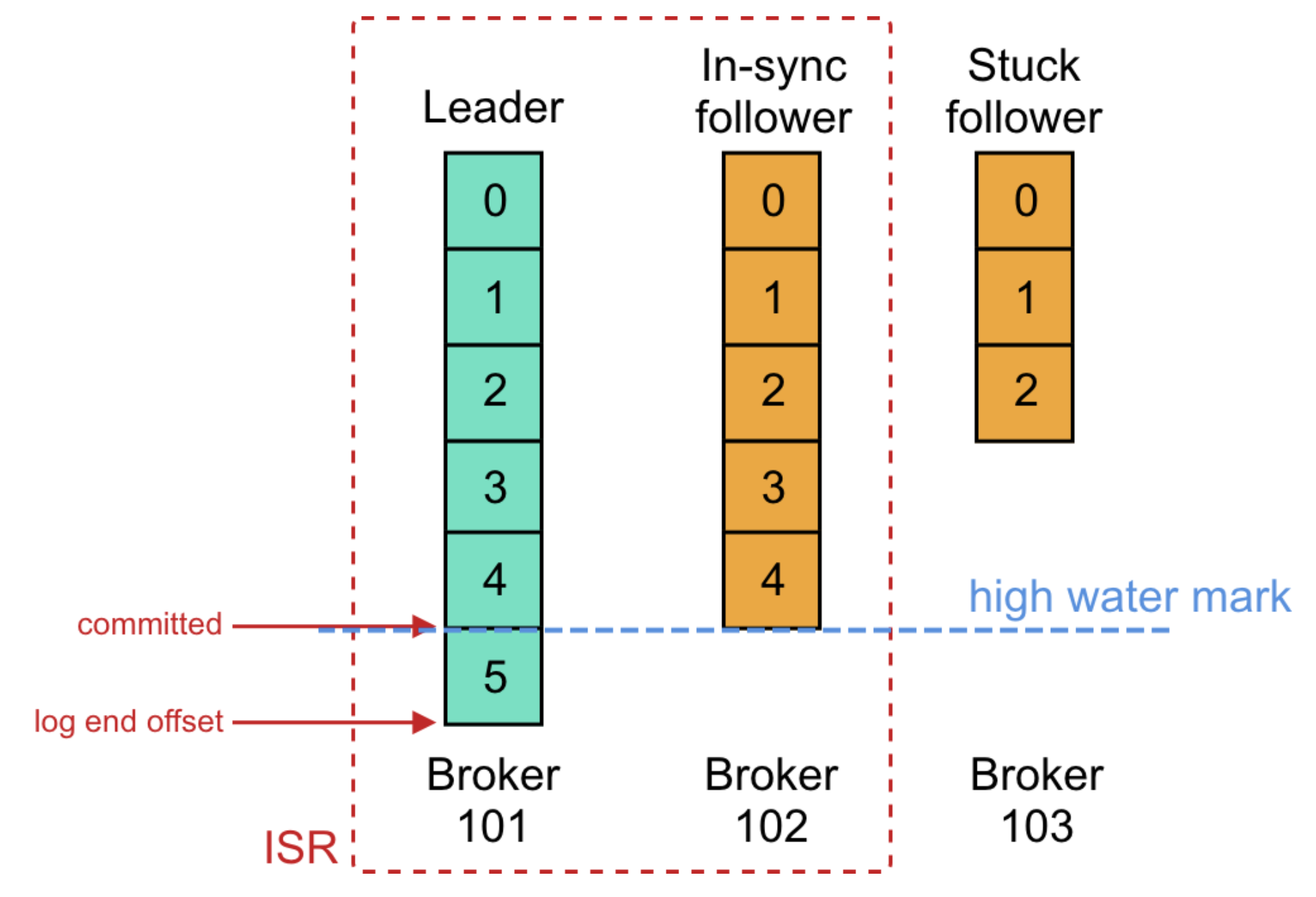
高性能因素
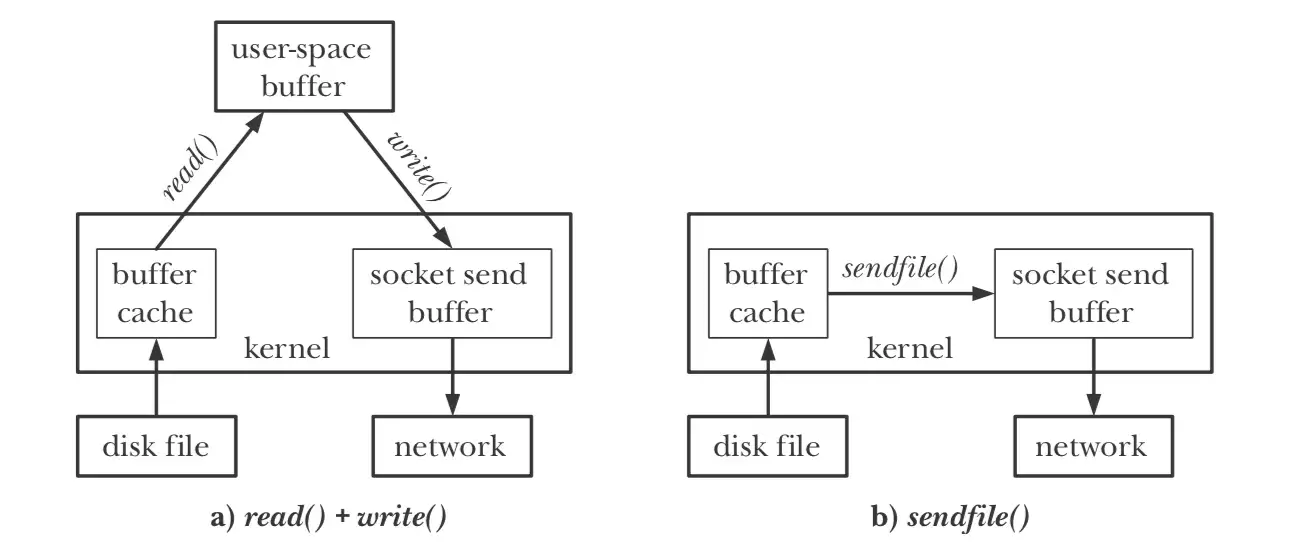
- Sequential I/O
- Zero Copy Principle
- Horizontal Scaling
- Compression & Batching of Data
zero copy技术原理,数据通过sendfile系统调用,直接从page cache发送到网络缓冲区,
EOS(Exactly-Once Semantics)

producer
开启幂等写入:enable.idempotence=true,其机制为,producer启动时zk会分配给它一个唯一id(PID),producer发送消息时,给消息打一个递增的Sequence Number(SN),timeout等情况重试的情况,这个SN都不变。broker在server端就可以根据PID+SN做去重。另外要配合acks=all,保证这个SN同步到了replica上,这样leader fail也没关系。
broker上的去重亦比较简单,它只要保存一个自己成功commit消息(成功写到所有ISR replia了)的最大PID-SN,小于这个值的消息则认为重复,不处理即可。
consumer
consumer消费kafka,写到下游(比如redis)的场景。
两种方案,
要么写入支持2PC,做consume+2PC write的原子操作,这个kafka提供事务支持。
要么下游设计成支持幂等写。目前大部分下游都是不支持2PC的(如redis/mysql/ES),因此要做到EOS,最常使用幂等写的方案。
Rebalance
consumer增删时,都会导致rebalance,还有一种情况,当consumer长期不进行fetch时,broker会认为consumer已经idle了,会主动踢掉这个consumer,也产生rebalance。
rebalance会STW,所有consumer已经消费到,但未commit的消息都被broker认为失效消费,因此会导致rebalance后consumer重复消费这部分数据。这个问题与EOS要解决的问题一致,也可以通过事务或幂等来解决。
ElasticSearch
使用Apache Lucene可以制作单机版全文搜索引擎,而ElasticSearch(ES)是在Lucene之上,包装提供了扩展和容错的能力。因此ES包含两个大块,
- Lucene
- 分布式实现
分布式
系统架构
ES是P2P架构(跟ClickHouse一样,架构没什么好画的),根据功能,ES将Node划分为不同类型:Master,Data,Client(也叫Coordinator)。
Master负责集群状态管理,Data负责数据存储,Client负责Serve查询和写入请求。说ES是P2P的,因为ES中所有进程都一样的,都是即可以作为Master,又可以作为Data和Client。
但具本到集群搭建时,通常会划分角色,以方便运维和故障处理。角色划分是通过ES启动的配置文件实现的,master:true/false, data:true/false两个选项,比如都为false时表示client node。
一个例子:38个node的集群划分,3个master node,7个client node,28个data node。单个shard一般控制在30-40G之间,官方建议最大50G。
集群状态管理
3个master是为了高可用,其中只有一个active master serve请求,其它为standby,active master通过Bully算法选举产生。master主要负责分片的决策,
- 分片应该分配到哪个节点上(维持数据balance)
- 选举primary shard
集群启动后,
会先进行master选举,master确认后,从各node收集并获取最新版本的元数据信息(由Gateway模块负责,比如哪个shard在哪个node),其后进行primary shard的选举(由Allocation模块负责),最终再进行各shard数据的恢复工作。
分区
ES是hash partition,因此查询请求需要广播到所有data node,也就决定ES单个集群不适合搞太大规模。
hash算法是,
shard = hash(routing) % number_of_primary_shards
其中routing默认是doc_id,但也可以通过配置改变,一般不要动它,有业务含义的字段会带来数据倾斜的问题,并且全文搜索场景下,也不太有这种需求。
副本与数据一致性
ES副本数据同步采用primary copy(也叫primary-backup)模式(具体是参考的PacificA算法)。primary节点serve写请求,并负责同步数据到replica节点,ES的replica节点只能serve query请求。
ES是一个最终一致的系统,
表现在,
- 写入内存的数据,只有被refresh成segment后才能serve查询(默认1s refresh)
- ES的主从副本同步不是强一致的
ES的数据同步参考了PacificA算法,PacificA算法将数据一致性,和元数据的一致性分开管理,与ES具体实现的类比,
| ES模块 | PacificA算法 | 功能 |
|---|---|---|
| Master IndexMeta | Configuration Manager | 维护元数据的一致性 |
| IndexMeta中的InSyncAllocationIds | Replica Group | 当前可用的replica列表 |
| SequenceNumber | Serial Number | 每个doc更新加1,跟term一起写给replica,用于区分更新顺序,防止旧版本数据覆盖新数据 |
| Local and Global Checkpoints | Committed Point | 下述 |
| Term | Configuration Version | 每次primary选举后加1,区分新旧primary |
通过term和SequenceNumber,我们可以对比两个replica的数据谁新谁旧,比如当一个primary(term x) fail恢复后,通过term+SequenceNumber,可以判断出哪些operations(属于term x的)在new primary上没有,这部分数据需要删除。
但出现的问题是,要比较两个replica所有数据效率太低了。checkpoint机制用来解决这个问题,checkpoint是一个SequenceNumber,local checkpoint表示从这之前的数据,我都跟primary保持一致了。global checkpoint是选的local checkpoint的最小值,表示全局上看,所有in-sync的replica在checkpoint(SequenceNumber)之前的数据都一样。所以故障恢复时,不需要再比较这之前的数据。
doc写入时,可以通过wait_for_active_shards控制成功写入replica的个数,从而实现对数据一致性的不同要求,
- 1(默认,只要primary shard写入成功即可)
- ALL
- QUORUM
但即使设置成wait_for_active_shards=ALL,ES也不保证强一致的同步,
因为这个同步本身就不是原子的,如果其中一个replica一直超时,则master会通过IndexMeta的更新将它从InSyncAllocationIds队列中踢除,后续该replica就不能serve query了。但IndexMeta到各node是通过Gossip同步的,本身只是一个最终一致的过程,因此期间还是能从replica上读到旧的数据。
可以看出,虽然PacificA算法本身是强一致的,即IndexMeta是强一致的,但因ES是P2P架构,每个节点都维护了一份IndexMeta,这两份数据的同步只是最终一致的,因此整体ES只是个最终一致的系统。
数据持久化
内存中的数据,包括memory buffer和segment,最终被flush后才到磁盘,内存中的数据在ES进程崩溃后会丢失。ES使用log机制保证持久性,叫translog.
首先,数据写入memory buffer,再写入translog(写memory buffer就是写lucene,写lucene会做一些数据检查,反过来会有translog成功但lucene写失败的情况),
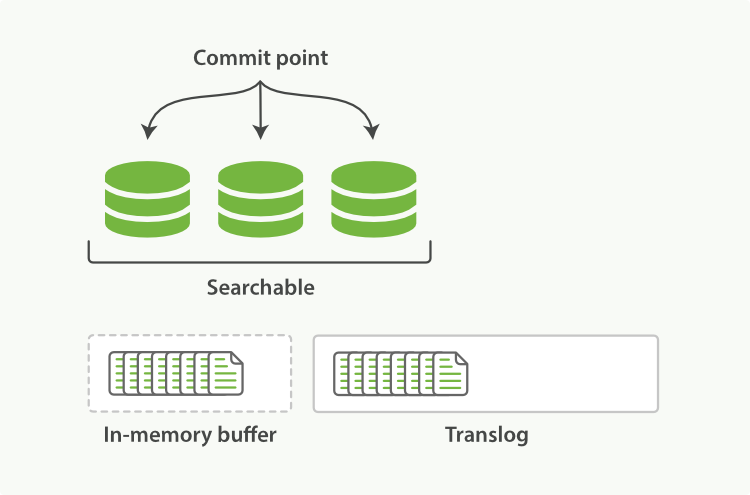
每秒,memory buffer的数据被refresh到segment,
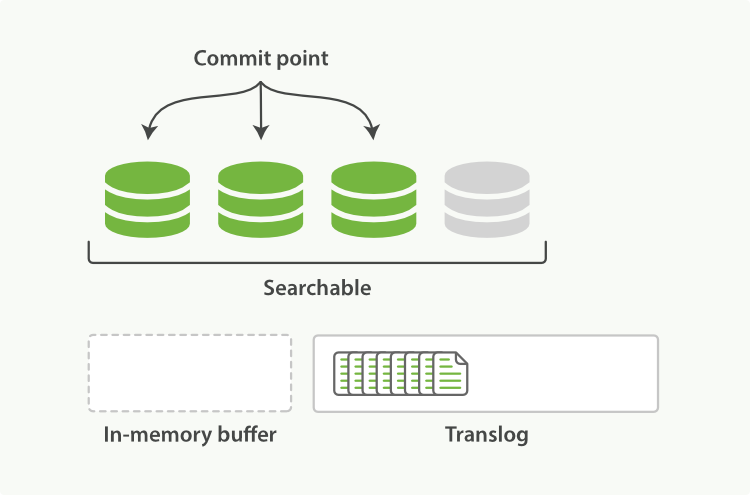
每隔5s,translog被flush到磁盘(这5s期间,如果进程fail,translog会丢失进而数据丢失),
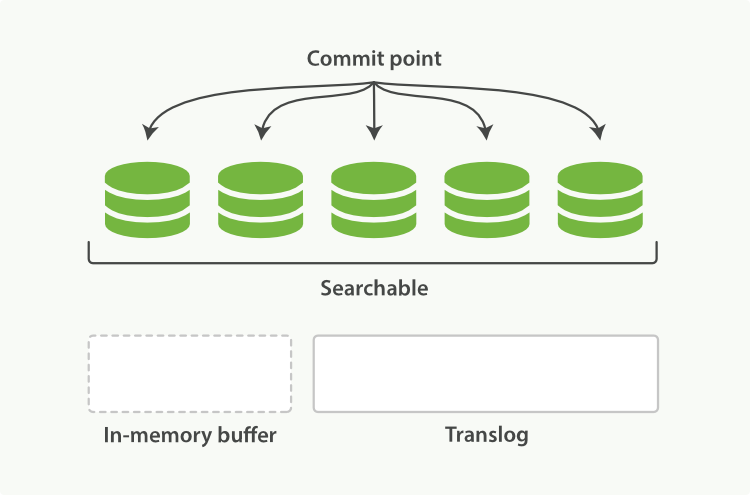
可以通过参数配置translog多安全,在性能和数据准确性间做一些取舍,
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
Lucene
ES中每个shard是一个lucene index,一个lucene index由多个segments构成。
逻辑上,一个segment由很多docs组成,每个doc由fields组成,fields三要素(Name, Type, Value)
Term概念,
Analyzer从doc中提取出token对象后,与其field进行结合后,形成term。token包含其在文本中的开始和结束位置,以及这个词语的类型等属性(比如是否stop word)。
term = doc field + token
Inverted index
Inverted index构建过程,
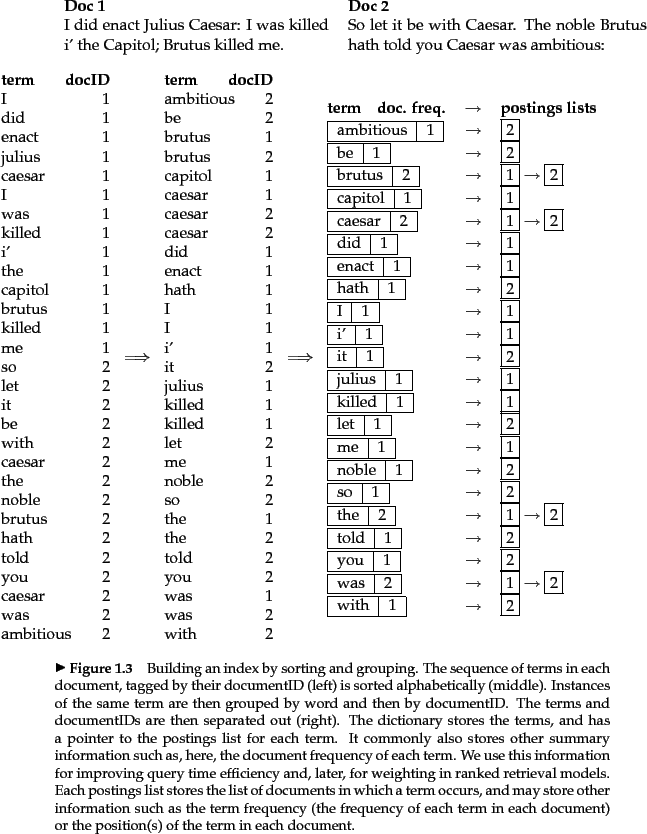
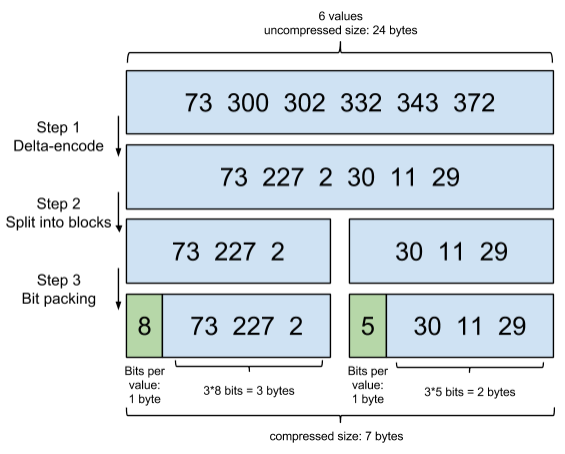
其中,terms列表叫Term Dictionary。整个Inverted Index叫Term Index,其存储的主要是term到postings的映射。
实际存储使用了一些更优的数据结构,包括,
- Term index使用Finite State Transducer(FST)存储,类似前缀树
- Postings list使用Frame Of Reference编码和使用Roaring bitmaps实现快速交并集计算
Frame Of Reference,
TF-IDF
brutus这个term出现在两个doc:doc1和doc2中,那在搜索brutus时doc1和doc2谁先谁后展示呢?TF-IDF通过进行term query与doc的相关性度量来解决这个问题,

TF-IDF =
TF(term在doc中出现的频率,等于term在doc中出现次数/doc中所有term出现的总次数)
x
IDF(inserse doc频率,等于语料库中(ES中某个index)总doc数/出现该term的doc数)
MySQL
索引
只看InnoDB引擎。
主键索引(聚簇索引).vs 非主键索引(二级索引)
示例表:
| ID | Name | Age | K |
|---|---|---|---|
| 100 | tom | 20 | 1 |
| 300 | betty | 30 | 2 |
| 400 | jerry | 40 | 3 |
| 600 | harry | 10 | 4 |
其中ID是primary key,并在K列建立普通索引KEY idx_key(K),
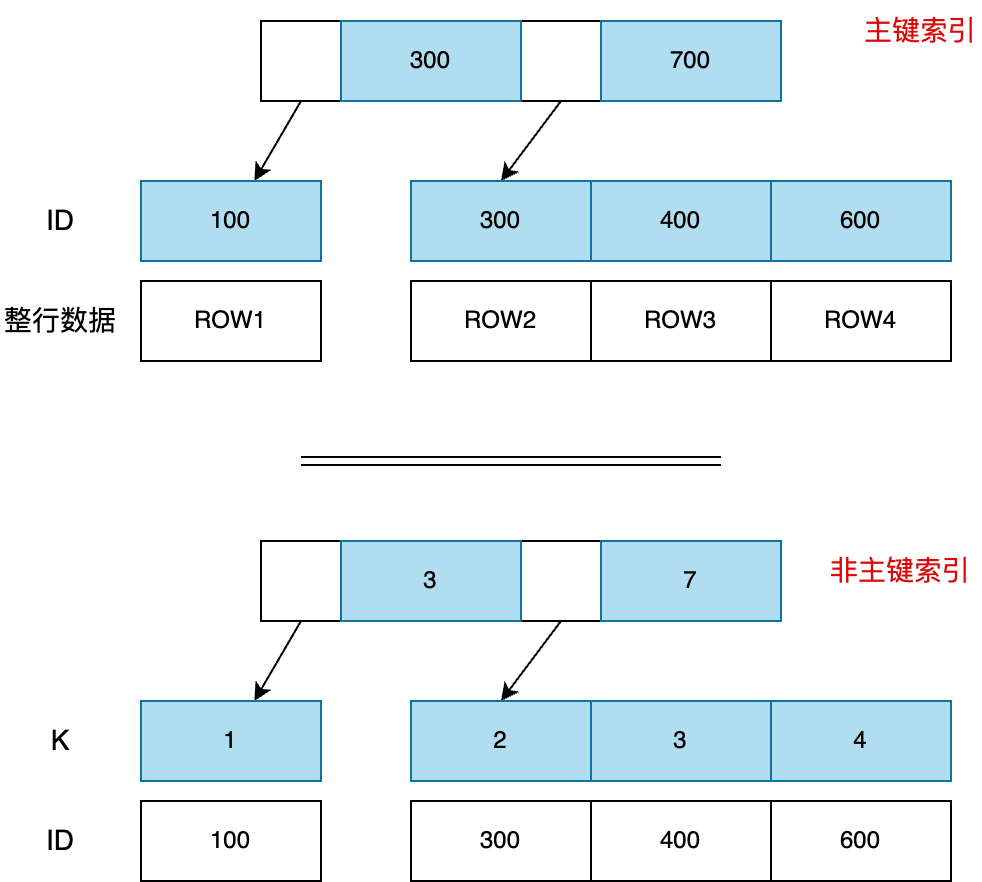
主键索引的叶子节点,存储行数据本身(其实也只是文件指针),非主键索引叶子节点存储主键的id(一般auto increament id),再通过id在主键索引中查询数据,这也是二级索引名称的由来,这个查询过程叫回表。
最左前缀原则(Leftmost Index Prefixes)
最左前缀原则与组合索引的存储结构有关,仍以上表为例建立组合索引:KEY idx_name_age(name,age),则索引结构可能为,
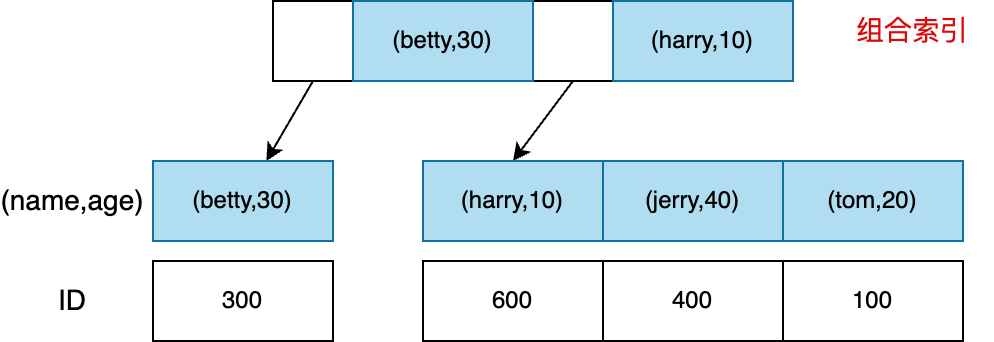
查询where name=‘tom’; 可以用到索引。where age=10;使用不了索引,因为不满足左前缀原则,可能有(jerry, 10),(XX, 10),一定要扫描全表。
where name>‘tom’ and age=100; 可以用到name部分索引,但用不到age部分。因为>运算符后,就需要扫描name>‘tom’的所有叶子节点了,不能再使用age精确定位一个或部分叶子节点。
Leftmost Index Prefixes定义,
In a table that has a composite (multiple column) index, MySQL can use leftmost index prefixes of that index. A leftmost prefix of a composite index consists of one or more of the initial columns of the index.
事务
ACID中,C是事务追求的目标,A由redo/undo log,通过回滚机制保障,D通过redo log实现。事务如果串行执行,则不存在I的问题,I是由并发引入的。
有两种并发控制方式,两阶段锁(2PL)和快照(Snapshot Isolation)
可以通过并发控制,在性能和数据一致性之间做一些取舍,亦产生了事务隔离的概念。
目前有4种(sql标准中定义)事务隔离级别,
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommitted | √ | √ | √ |
| Read Committed | × | √ | √ |
| Repeatable Read | × | × | √ |
| Serializable | × | × | × |
MySQL默认RR(Repeatable Read)级别,但它通过MVCC & Next-Key Lock解决了幻读的问题,因此MySQL实际比SQL标准严格一些,它的RR也不存在幻读问题。
锁
以下谈论的也是InnoDB引擎,MyISAM只支持表锁,比较简单。
锁的目标都是为了正确的控制并发读写,锁的具体实现中追求的是性能。任何锁的出现,都遵循这个理念。
InnoDB有四种类型行锁,
- Record Lock: 锁一行记录
- Gap Lock: 锁一个范围,不包括记录本身
- Next-key Lock: Record Lock+Gap Lock,锁定一个范围,包含记录本身
- Insert Intention: 一种特殊的gap lock,为了提升并发insert性能
锁的兼容关系(是否lock1需要等待lock2,Compatible代表不需要等待,如Gap lock不需要等待任何锁),
| Lock 1 (new) \ Lock 2 | Gap lock | Record lock | Next-key lock | Insert Intention |
|---|---|---|---|---|
| Gap lock | Compatible | Compatible | Compatible | Compatible |
| Record lock | Compatible | Conflict | Conflict | Compatible |
| Next-Key lock | Compatible | Conflict | Conflict | Compatible |
| Insert intention | Conflict | Compatible | Conflict | Compatible |
另外还有一种intention lock,它是一个表级锁,每次获取行锁前设置,这个锁与所有行锁都不冲突,只与表锁(共享/独占表锁,lock tables…read/write)冲突。这样的好处是可以快速判断表里是否有记录被加锁。它与Insert intention不是一个东西。
Insert Intention是事务A想插入一行记录,但这个记录的位置当前存在一个事务B的gap lock(也包含next-key lock)时,而生成的一个插入意向锁。这时事务A会阻塞,处于等待状态,一直到事务B提交。
etcd
etcd由raft算法和存储两部分构成,
Raft共识算法
Raft系统角色
- Leader:接受客户端请求,并向follower同步请求日志,当日志同步到大多数节点上后告诉follower提交日志。
- Follower:接受并持久化leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- Candidate:leader选举过程中的临时角色。
状态转移
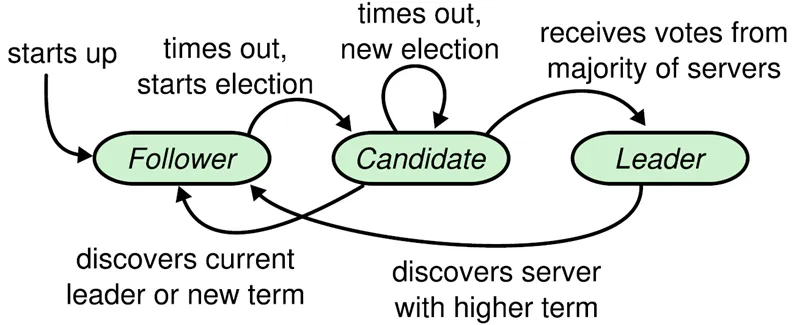
Raft将时间分为一个个的任期(term),每一个term的开始都是leader选举。在成功选举leader之后,leader会在整个term周期内负责处理请求命令。如果leader选举失败,该term就会因为没有leader而结束。
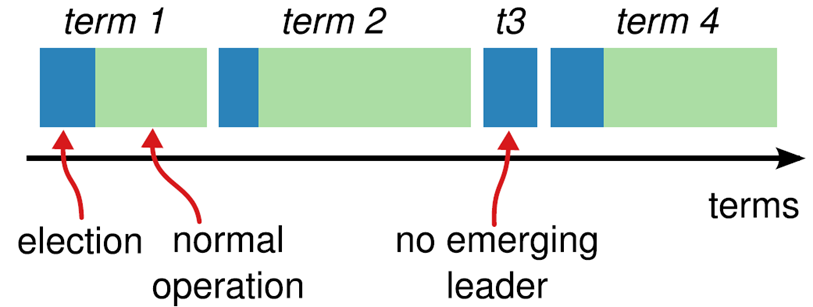
Leader选举
Leader周期性向followers发送心跳包,如果follower在选举超时时间内没有收到leader的heartbeat,就会等待一段随机的时间后发起一次leader选举。follower将其当前term+1后转换为candidate。它首先给自己投票并且给集群中的其他服务器发送RequestVote RPC。接下来有3种可能,
- follower赢得了多数的选票,成功选举为leader
- 收到了leader的消息,表示有其它服务器已经抢先当选了leader
- 没有服务器赢得多数的选票,leader选举失败,等待选举时间超时后发起下一次选举
日志同步
Leader把请求命令作为log entry(一条日志),放到本地日志,并通过AppendEntries RPC复制给followers.
在一term任期内,leader给log entry一个唯一递增编号:log index。如果一个log entry被复制到大多数服务器上,就被认为可以commit了。
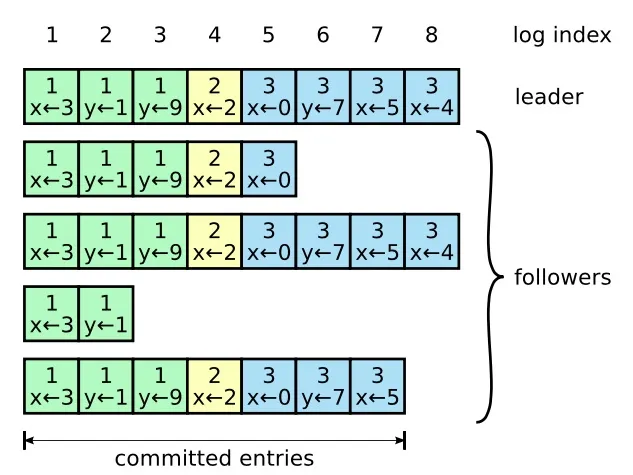
Raft日志同步保证,
- 如果不同节点日志中的两个log entry有着相同的log index和term,则它们所存储的命令是相同的(term+log index作为唯一标志)
- 如果不同节点日志中的两个log entry有着相同的log index和term,则它们之前的所有log entry都是完全一样的
第二条特性源于AppendEntries的一致性检查,发送一个AppendEntries RPC请求时,会把之前一条日志的log index和term都带上,follower在写入时,会检查它是否与本地存储的一致,不一致就拒绝,这样递增推进,保证之前的所有log entry完全一致。
对于旧leader没有commit的本地log,新leader选举出来后,通过term+log index清理旧leader的脏数据(给他发上一term的最大log index即可,最大log index之后的数据都清理掉)。
安全性
Raft增加了2个安全性约束,
- 拥有最新的已提交的log entry的follower才有资格成为leader
- Leader只能推进commit log index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index小于commit log index的日志被间接提交)
约束2要解决的问题,
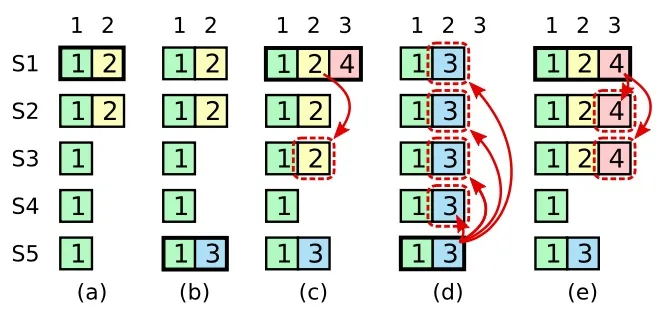
在阶段a,term为2,S1是leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
在阶段b,S1离线,触发一次新的选主,此时S5被选为新的leader,此时系统term为3,且写入了日志(term, index)为(3, 2).
S5尚未将日志推送到followers就离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成leader,此时系统term为4,此时S1会将自己的日志同步到followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2, 2)可以被提交了;
在阶段d,S1又下线了,触发一次选主,而S5有可能被选为新的leader(这是因为S5可以满足作为主的一切条件:1)term = 5 > 4,2)最新的日志为(3, 2),比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到followers,于是S2、S3中已经被提交的日志(2, 2)被截断了。
增加上述限制后,即使日志(2, 2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被提交,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 4)被大多数followers确认,S1方可提交日志(4, 4)这条日志,当然,根据raft定义,(4, 4)之前的所有日志也会被提交。此时即使S1再下线,重新选主时S5不可能成为leader,因为它没有包含大多数节点已经拥有的日志(4, 4)。
日志压缩
Log entries会一直增长,但commit后的日志是可以被删除的,通过snapshot实现,
- 记录日志元数据:最后一条已提交的log entry的log index和term。这两个值在snapshot之后的第一条log entry的AppendEntries RPC的完整性检查的时候会被用上
- 记录系统当前状态(也就是最新k/v)
这样新节点加入,或有落后太多的follower需要同步日志时,可以通过InstalledSnapshot RPC从snapshot恢复,比log level的复制效率更高。
底层存储
通过MVCC模块对外直接提供了两种不同的访问方式,一种是键值存储kvstore,另一种是watchableStore,它们都实现了KV interface.
- kvstore: 底层是BoltDB,就是一个普通的KV存储。
- watchableStore: 对外提供了watch功能
在etcd v3中,watch key的事件是server推送给client端的(基于HTTP/2的gRPC协议,支持大量key的watch)
版本号是etcd逻辑时钟,当client因网络等异常出现连接闪断后,通过版本号,它就可从server端的BoltDB中获取错过的历史事件,而无需全量同步,它是watch机制数据增量同步的核心。
问题的核心是实现可靠的事件推送机制,watch机制的核心流程如下,
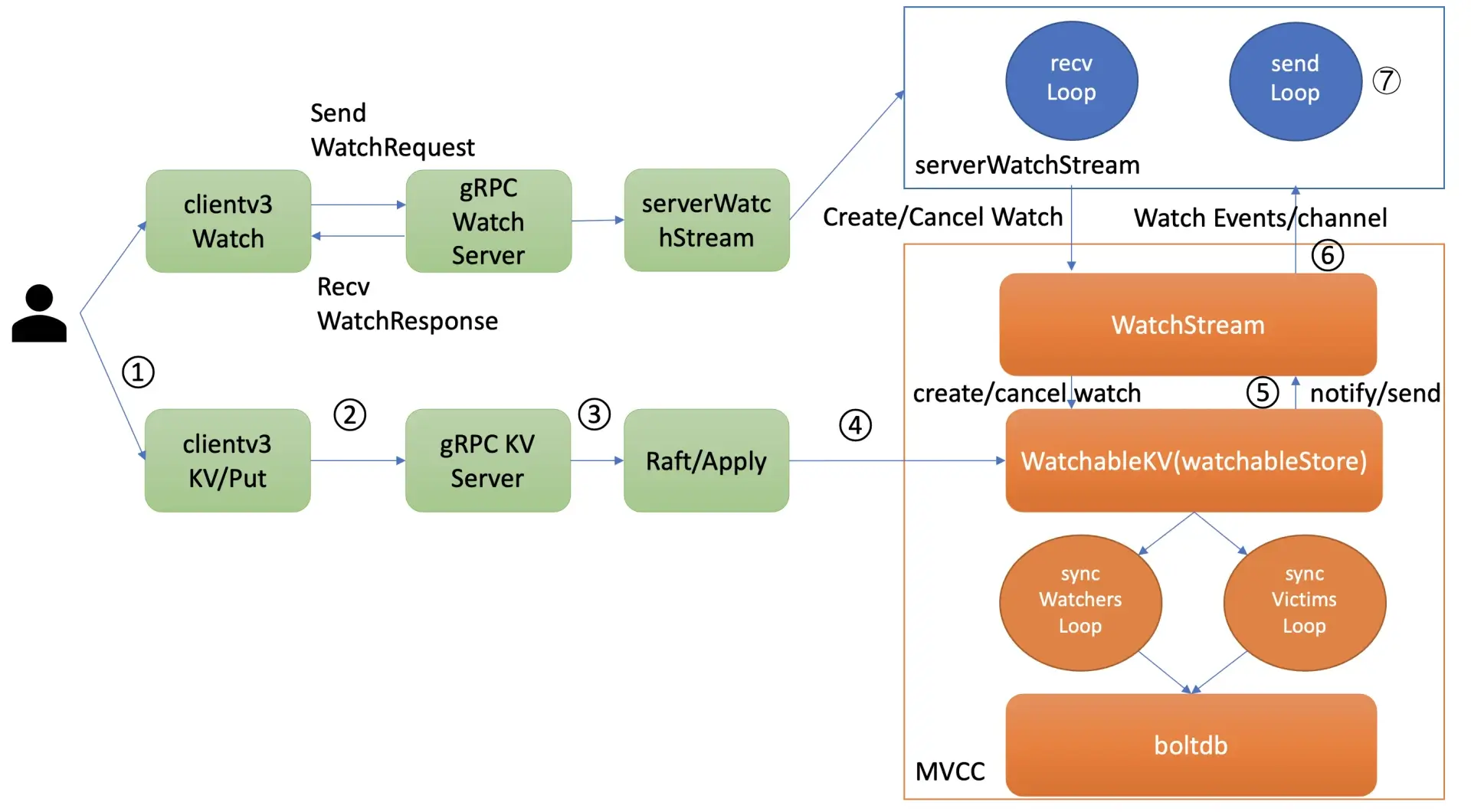
通过 etcdctl 或 API 发起一个 watch key 请求的时候,etcd 的 gRPCWatchServer 收到 watch 请求后,会创建一个 serverWatchStream, 它负责接收 client 的 gRPC Stream 的 create/cancel watcher 请求 (recvLoop goroutine),并将从 MVCC 模块接收的 Watch 事件转发给 client(sendLoop goroutine)。
当 serverWatchStream 收到 create watcher 请求后,serverWatchStream 会调用 MVCC 模块的 WatchStream 子模块分配一个 watcher id,并将 watcher 注册到 MVCC 的 WatchableKV 模块。
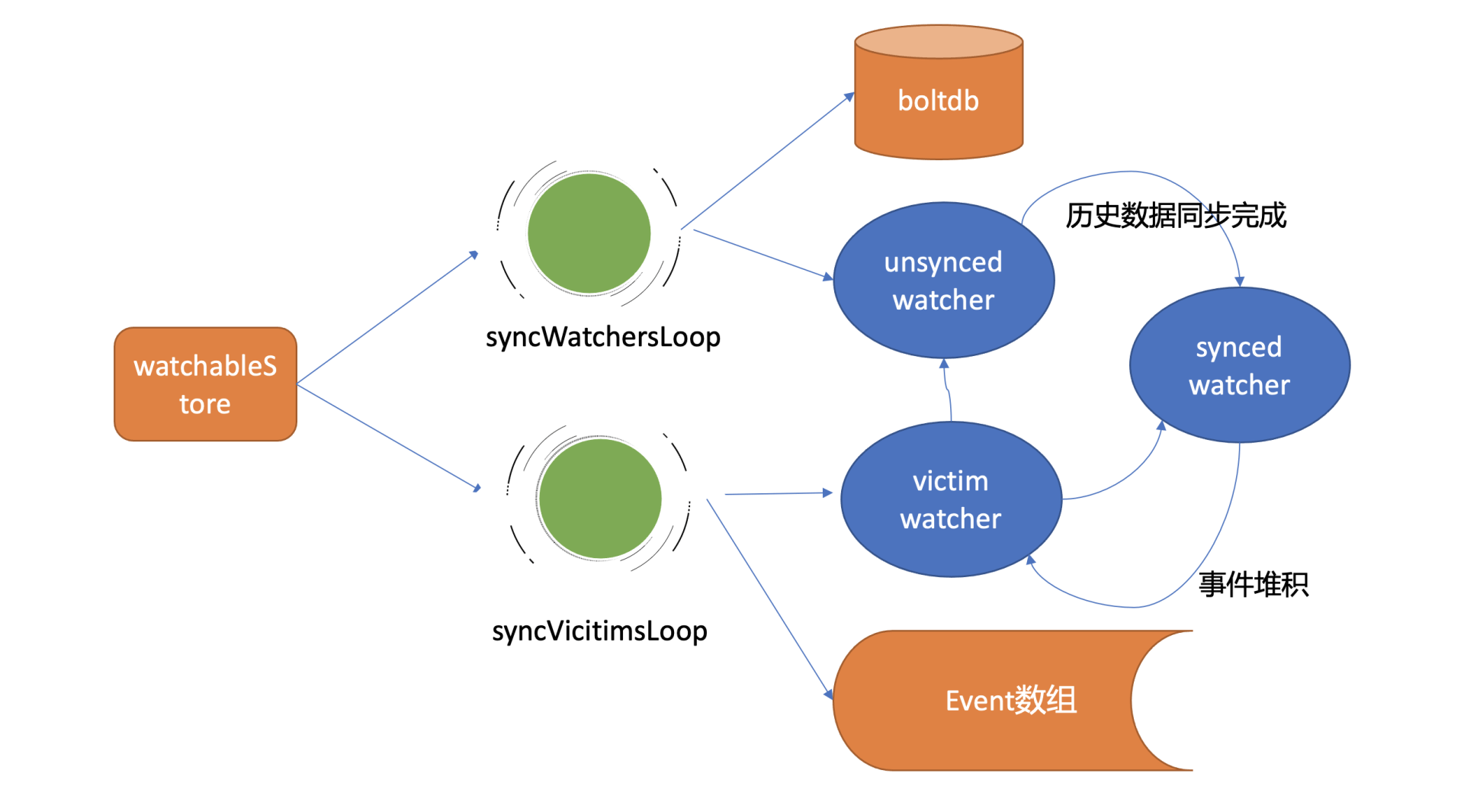
在 etcd 启动的时候,WatchableKV 模块会运行 syncWatchersLoop 和 syncVictimsLoop goroutine,分别负责不同场景下的事件推送,它们也是 Watch 特性可靠性的核心之一。
事件推送拆分成3个子问题,
- 最新事件推送(synced watcher)
- 异常场景重试(victim watcher,如channel buffer满了,不能影响主流程,进行异步重试)
- 历史事件推送机制(unsynced watcher,消费历史版本,若该版本数据已经被compact了,返回ErrCompacted给client)
Watcher状态转换关系,
Go
| GMP model | Desc |
|---|---|
| G | goroutine(coroutine): G stores the execution-related information such as the code entry address, context, running environment (associated P and M), and running stack for concurrent execution. The creation, hibernation, recovery, and stop of G are all managed by the runtime. |
| P | logical processor: created when the program starts, it is a managed data structure, P mainly reduces the complexity of M to G, and adds an indirect control layer data structure. P controls the parallelism of the GO code, it is not an entity. The upper limit is GOMAXPROCS, the default number of CPUs. |
| M | thread OS kernel thread: It is an entity scheduled and executed at the operating system level. M is only responsible for execution, M is constantly being awakened or created. Then execute. The upper limit is 10000. |
Go中,M是运行G的实体,scheduler的功能是将runnable的G分配给M运行。
GMP机制
- Global Queue: 保存等待执行的G
- P’s local queue: 与global queue类似,它也是保存等待执行的G,但是有256个G的存储限制。 新创建建的G,优先放到P的local queue, 当queue满了,local queue中一半的G将被移到global queue。
- List of Ps: 所有的Ps都是在程序启动时创建,并放入一个数组中,最多可以创建
GOMAXPROCS个P。 - M: 如果thread想要执行task,它必须先获得P,并从P的local queue中取任务。当P的local queue为空时,M会尝试从global queue中拿一批G,并放到P的local queue。或者,从其它P的local queue中streal一半的G过来,放到自己P的local queue。M运行G,当G运行完时,M从P获取下一个G执行,并重复这一过程。
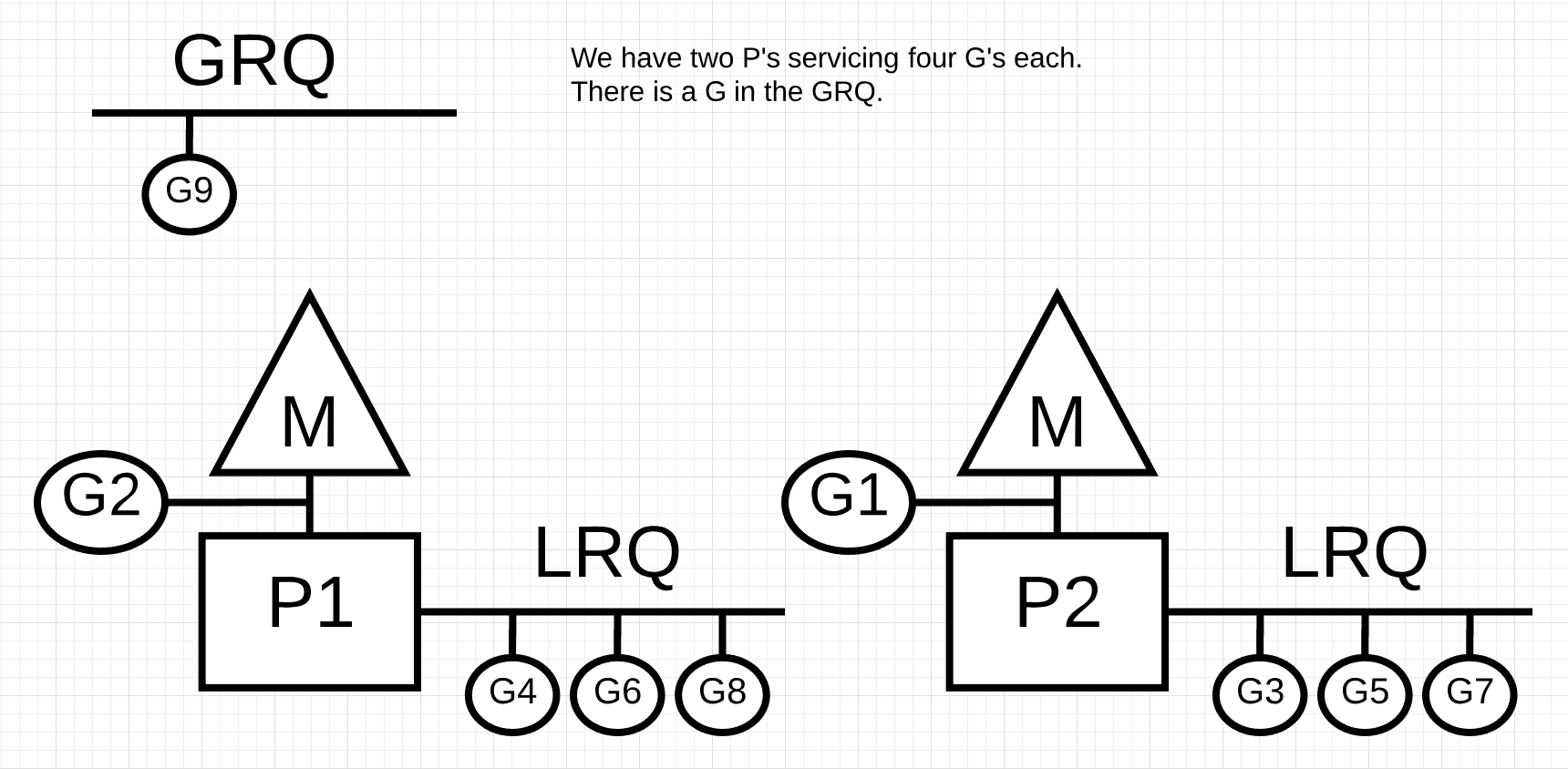
图中,每个P的local queue(LRQ)中有4个G,其中一个是正在M上执行的。在global queue中(GRQ)中有一个G。
M什么时机创建呢?
当没有足够的M来绑定P运行runnable G时。举例:当所有M都在block中,然而还有许多ready的P等待执行,此时找不到空闲的M,将会创建新的M。
Scheduler调度策略
避免threads频繁的被创建和删除,尽量reuse threads。
#1 Stealing机制
当thread没有G来运行,它将尝试从其它thread绑定的P中偷取G来运行
#2 Hand off机制
当thread因为G的syscall而block,安会释放绑定的P,并且将该P转交给其它idle的thread执行
TCMalloc
Go使用的是TCMalloc内存管理算法,TCMalloc的核心思想是在thread-local预分配一些small object的内存,使small object的内存分配(绝大部分的内存分配场景)可以在thread-local完成。
Go内存管理有三级结构,mcache(Thread Cache), mcentral(Central free list)和mheap(Central heap)
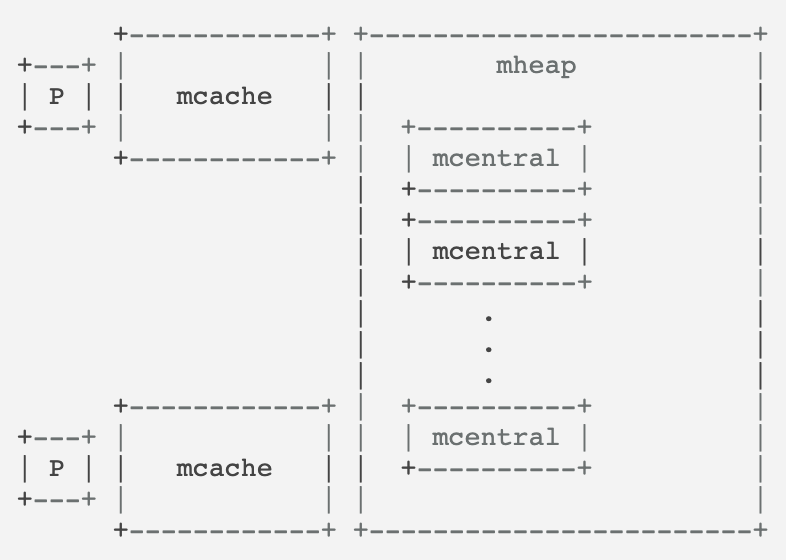
每个P有一个mcache(即thread-local cache,所以mcache上的内存申请不用加锁),mcache为每个size-class(170个,经验性的,从8byte到32KB)维护了一个mspan,这些spans可以分配某size-class大小的内存。
如果某个size-class内存已经用完了,则mcache它向该size-class的mcentral上申请一块内存,放入mcache.
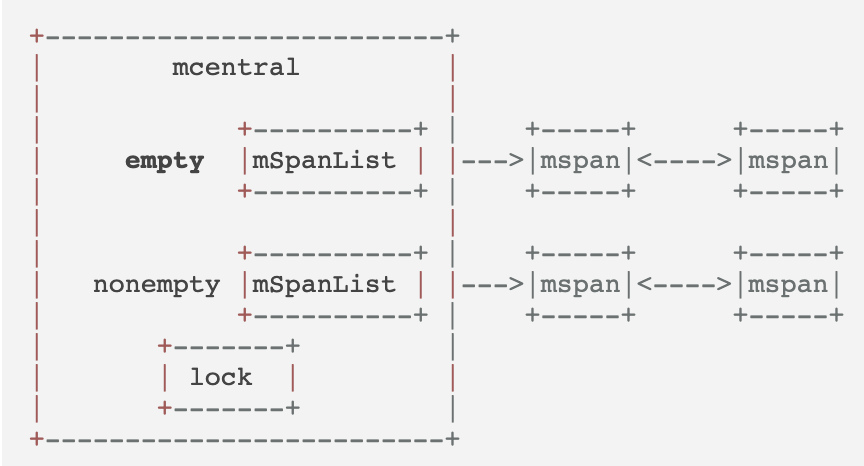
每个size-class有一个mcentral,每个mcentral持有一把锁,因为它可以被多个P共享。
mheap维护着一个free list的数组,数组中第i个元素,指向一个span链表(其中每个span由i个连续的page构成)。
当向heap申请n个pages的内存时,mheap在index >= n个pages的free span list上申请资源,如果mheap上没有free的内存了,则通过mmap向OS申请后加到mheap。
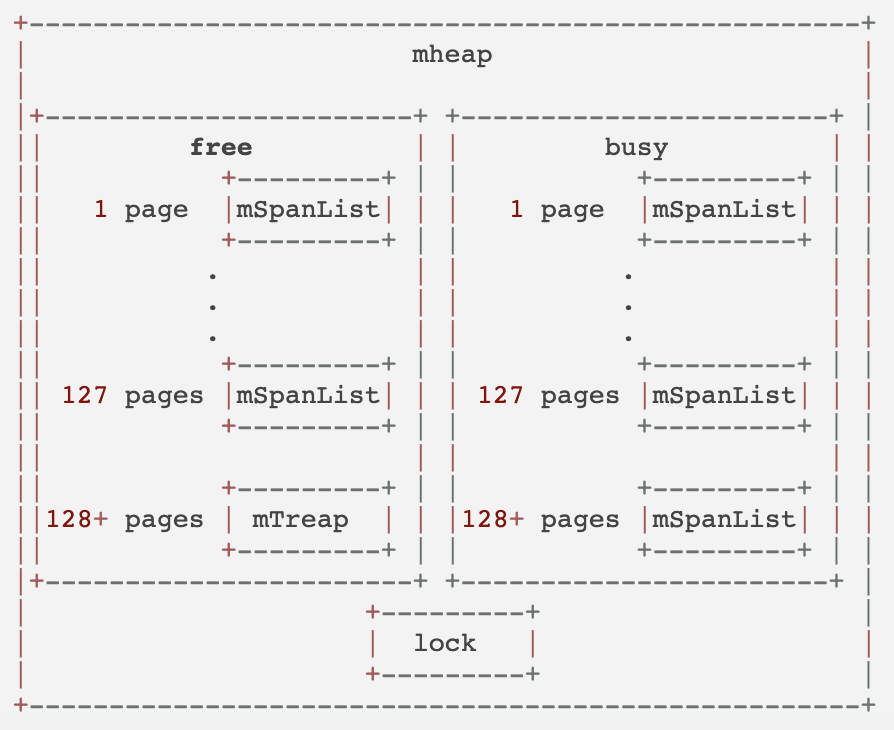
最终的内存申请流程,
- 首先在mcache申请,这一步不加锁
- 当mcache的内存不够用了,mcache向mcentral申请该size-class的内存,放到mcache中,这一步加锁
- 若mcentral的内存不够用了,它向mheap申请,并按size-class切割后放到自己的free list上,这一步加锁
- 当heap的内存不够用了,它向OS申请,并放到自己的span list上
三色并发标记算法
Go的垃圾回收(GC)算法使用的是无分代(对象没有代际之分)、不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。
原因是,
- 分代GC依赖分代假设,即GC将主要的回收目标放在新创建的对象上(存活时间短,更倾向于被回收),而非频繁检查所有对象。而Go的编译器会通过逃逸分析将大部分新生对象存储在栈上。只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。由于栈上分配的对象不需要GC,进而分代假设并没有带来直接优势。
- 对象整理的优势是解决内存碎片问题,但Go运行时的分配算法基于tcmalloc,基本上没有碎片问题。因此对对象进行整理不会带来实质性的性能提升。
- Go的垃圾回收器与用户代码并发执行,使得STW的时间与对象的代际、对象的size没有关系。Go团队更关注于如何更好地让GC与用户代码并发执行(使用适当的CPU来执行垃圾回收),而非减少停顿时间这一单一目标上。
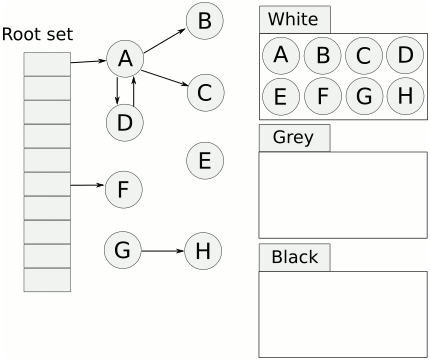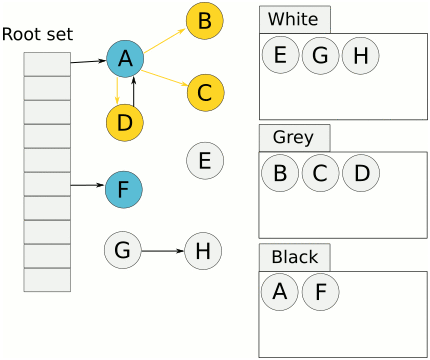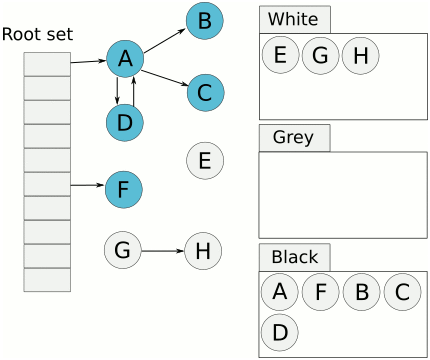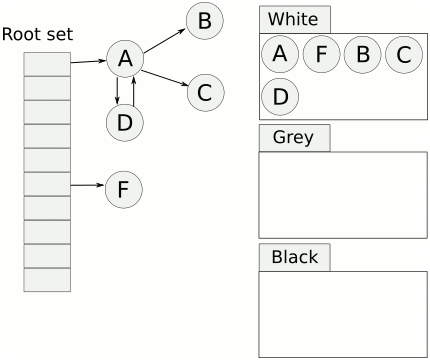
三色标记法(Tricolor Marks and Sweep)将对象分为三类,
- 白色对象:未被回收器访问到的对象
- 灰色对象:已被回收器访问到的对象,但回收器需要对其中的一个或多个指针进行扫描,因为他们可能还指向白色对象
- 黑色对象:已被回收器访问到的对象,其中所有字段都已被扫描,黑色对象中任何一个指针都不可能直接指向白色对象
标记过程如下,
- 起初所有的对象都是白色的
- 从根对象(从栈上扫)出发扫描所有可达对象,标记为灰色,放入待处理队列
- 从待处理队列中取出灰色对象,将其引用的对象标记为灰色并放入待处理队列中,自身标记为黑色
- 重复步骤(3),直到待处理队列为空,此时白色对象即为不可达的“垃圾”,回收白色对象
CSP模型
Go的并发哲学,
Do not communicate by sharing memory; instead, share memory by communicating
Go中的并发原语主要分为两大类,
一个是sync包里面的,主要是WaitGroup,互斥锁和读写锁,cond,once,sync.Pool这一类。
另一个是channel。
Go通过channel和goroutine实现了CSP(Communicating Sequential Processes)模型。另一种常见的是Actor模型,有Erlang,Scala,Java Akka等实现。
Actor模型中,process都有自己的mailbox,process间直接通信(因此process有唯一id),而CSP中process间通过channel通信,process是匿名的,channel的命名的。
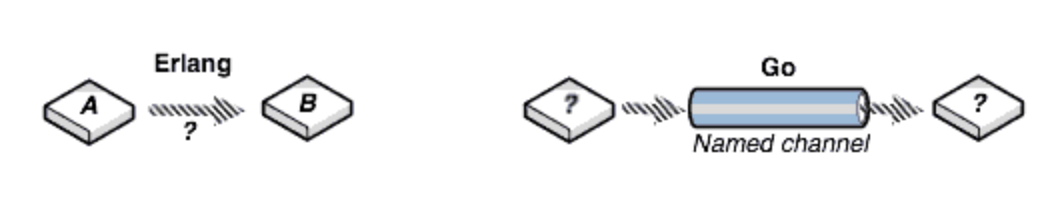
Channel
channel的代码,
// src/runtime/chan.go
type hchan struct {
qcount uint // 队列中数据总数
dataqsiz uint // 环形队列的 size
buf unsafe.Pointer // 指向 dataqsiz 长度的数组
elemsize uint16 // 元素大小
closed uint32
elemtype *_type // 元素类型
sendx uint // 已发送的元素在环形队列中的位置
recvx uint // 已接收的元素在环形队列中的位置
recvq waitq // 接收者的等待goroutine队列
sendq waitq // 发送者的等待goroutine队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
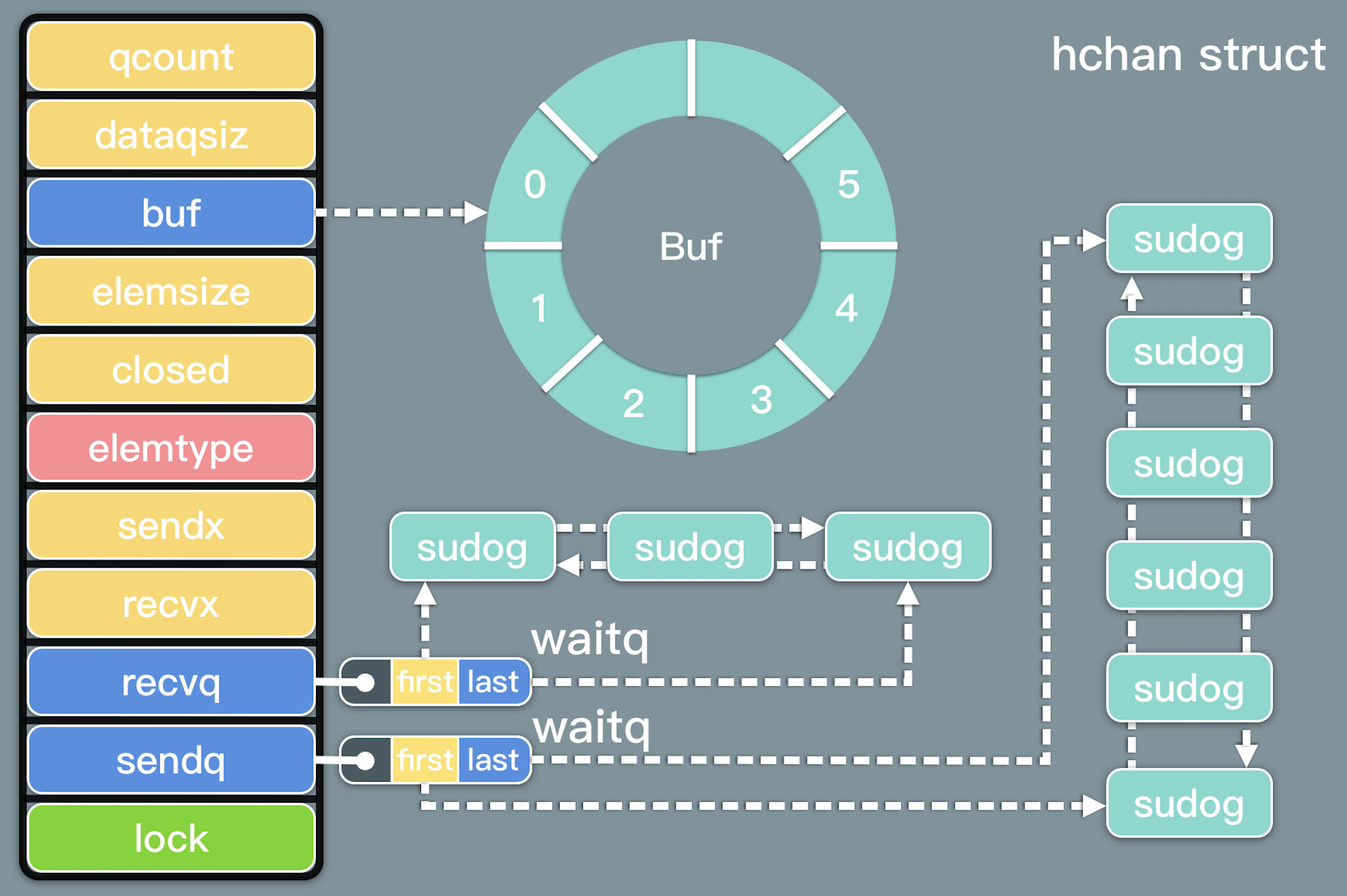
channel由3部分组成,
- 环形队列(qcount, dataqsiz, elemsize, elemtype, buf, sendx, recvx)
- waitq等待队列(recvq 和 sendq 是等待队列,waitq 是一个双向链表)
- lock互斥锁(lock)
waitq结构,
type waitq struct {
first *sudog
last *sudog
}
channel 最核心的数据结构是 sudog。sudog 代表了一个在等待队列中的 g。g 与同步对象关系是多对多的,一个 g 可以出现在许多等待队列上,因此一个 g 可能有很多sudog。并且多个 g 可能正在等待同一个同步对象,因此一个对象可能有许多 sudog。
channel的write, read, close,
write
| Channel Status | Result |
|---|---|
| nil | 阻塞 |
| 打开但buf满 | 阻塞 |
| 打开但buf未满 | 成功写入 |
| 关闭 | panic |
| 只读 | 编译错误 |
read
| Channel Status | Result |
|---|---|
| nil | 阻塞 |
| 打开且buf非空 | 读取到值 |
| 打开但buf为空 | 阻塞 |
| 关闭 | <默认值>, false |
| 只读 | 编译错误 |
close
| Channel Status | Result |
|---|---|
| nil | panic |
| 打开且buf非空 | 关闭 Channel;读取成功,直到 Channel 取尽数据,然后读取生产者的默认值 |
| 打开但buf为空 | 关闭 Channel;读到生产者的默认值 |
| 关闭 | panic |
| 只读 | 编译错误 |
hmap
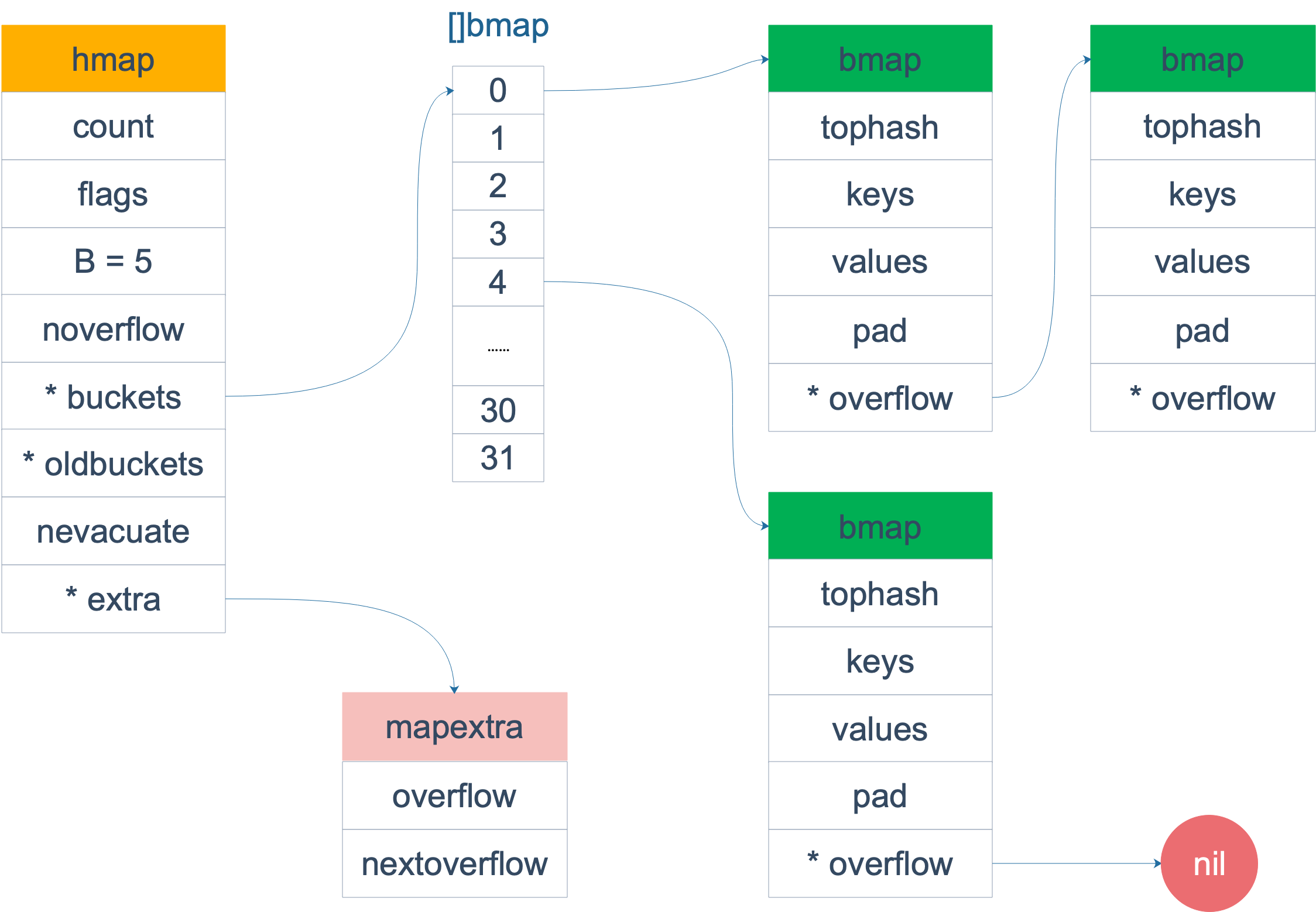
Go语言中map用hashtable实现(hashmap->hmap),它通过拉链解决哈希冲突。但冲突的元素并不直接拉链,而是通过bucket的方式,每个bucket可以放八个键值对(这种方式使用的指针少,省内存)。
hmap结构,
type hmap struct {
count int // 当前hashtable中元素个数
flags uint8
B uint8 // 当前hashtable中buckets个数,用对数表示,len(buckets) = 2^B
noverflow uint16
hash0 uint32 // hash的种子,为hash结果引入随机性
buckets unsafe.Pointer // 指向 buckets 数组,大小为 2^B,如果元素个数为0,就为 nil
oldbuckets unsafe.Pointer // 扩容时保存之前的buckets
nevacuate uintptr // 扩容进度,小于此地址的 buckets 迁移完成
extra *mapextra // optional fields
}
bucket使用bmap表示,
type bmap struct {
topbits [8]uint8 // tophash,用于定位k/v
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr // 指向overflow bucket
}
bucket中元素超过8个时,将使用extra.nextOverflow中bucket存储溢出的数据。overflow buckets会帮助减少hmap扩容的次数,而扩容是个成本比较高的操作,涉及大量keys的搬迁,而在overflow buckets不多的情况下,对性能的影响其实比较小,因此是一个比较好的折中方案。
hmap的整体结构,
bmap的内部结构,其中HOB hash指的就是tophash,

hmap中key的定位过程,
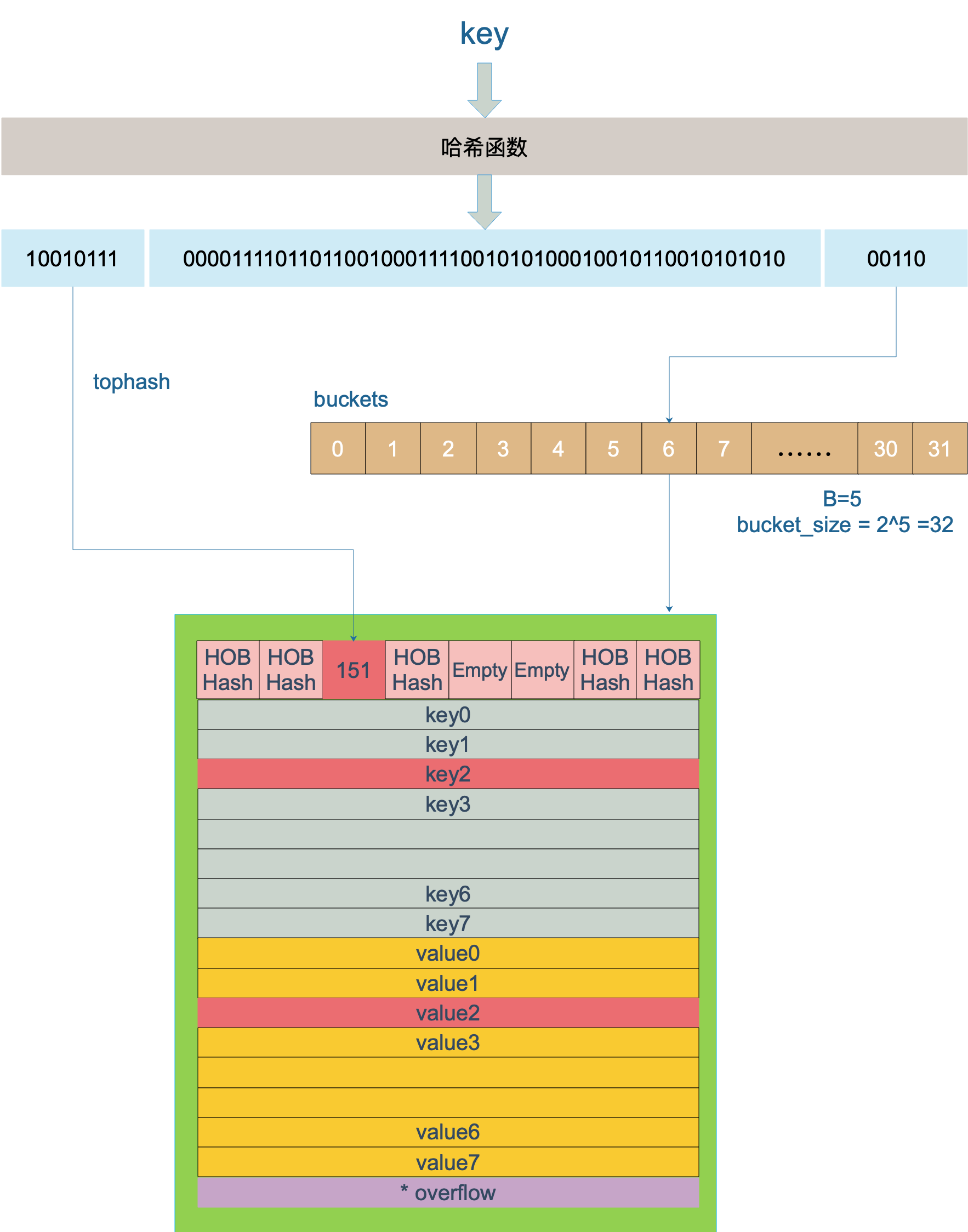
key hash后,低5位用来定位bucket(此处,bucket_size=2^5=32个),高8位作为tophash,用于bmap中定位具体key/value。这里keys和values是分别存储的,以获得更好的空间效率。
动态扩容
当很多keys hash到同一个bucket,buckets形成链表,访问效率降低。hmap使用loadFactor来衡量这种情况,
loadFactor := count / (2^B)
hmap扩容有两个时机,
- loadFactor超过阈值,Go源码中为6.5
- overflow的buckets过多
// src/runtime/hashmap.go/mapassign
// 触发扩容时机
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// loadFactor超过6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}
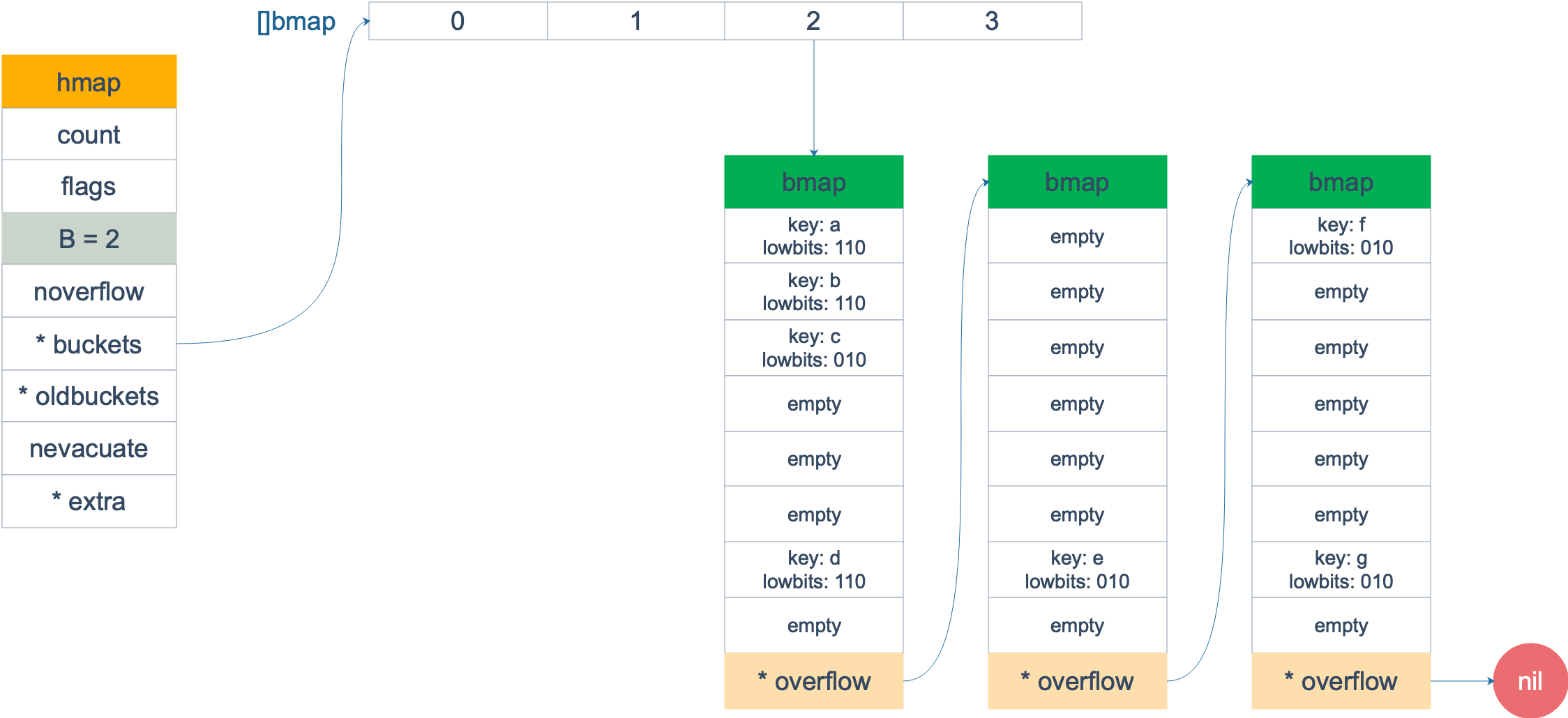
不能单使用loadFactor,因为可能有大量的插入后再删除,这种情况loadFactor不高,bucket内是空闲的,但bucket数多,导致很多遍历。
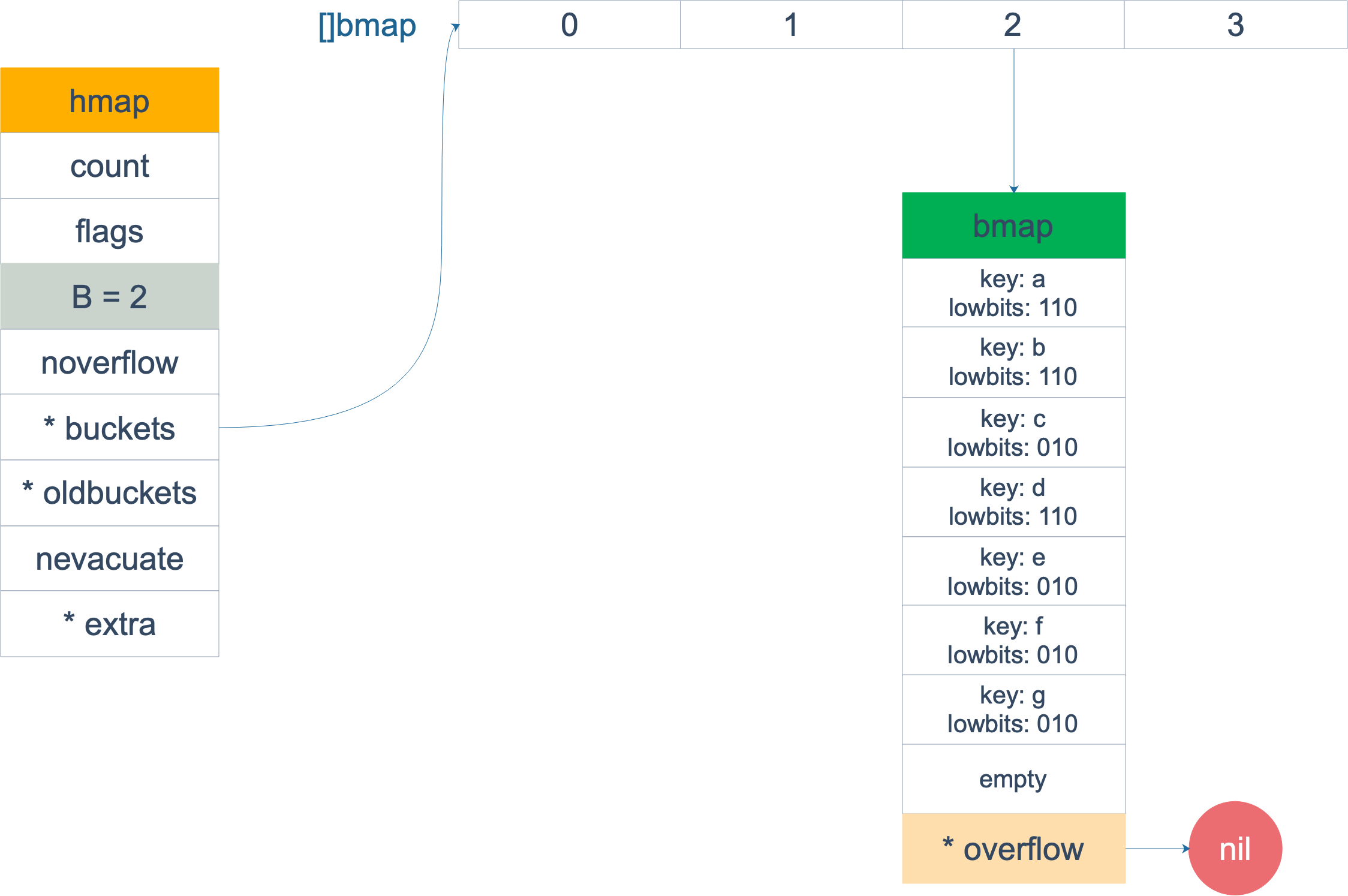
对于overflow buckets过多的情况,处理比较简单,申请一个跟oldbuckets相同大小的buckets,因为buckets大小不变,因此按bucket序号一对一搬就可以了,如原来的0号搬到新的0号bucket。
搬迁前,
搬迁后,bucket紧凑了,buckets数量未变
对于loadFactor超阈值的情况,申请两倍大小的buckets,要将所有key进行rehash,此时用于定位bucket的位,由低5位(B=5)变成了低6位。
由于由低5位变为低6位,因此原先第6位是0的key在新buckets的编号无变化,第6位为1的keys将搬迁到新的buckets,
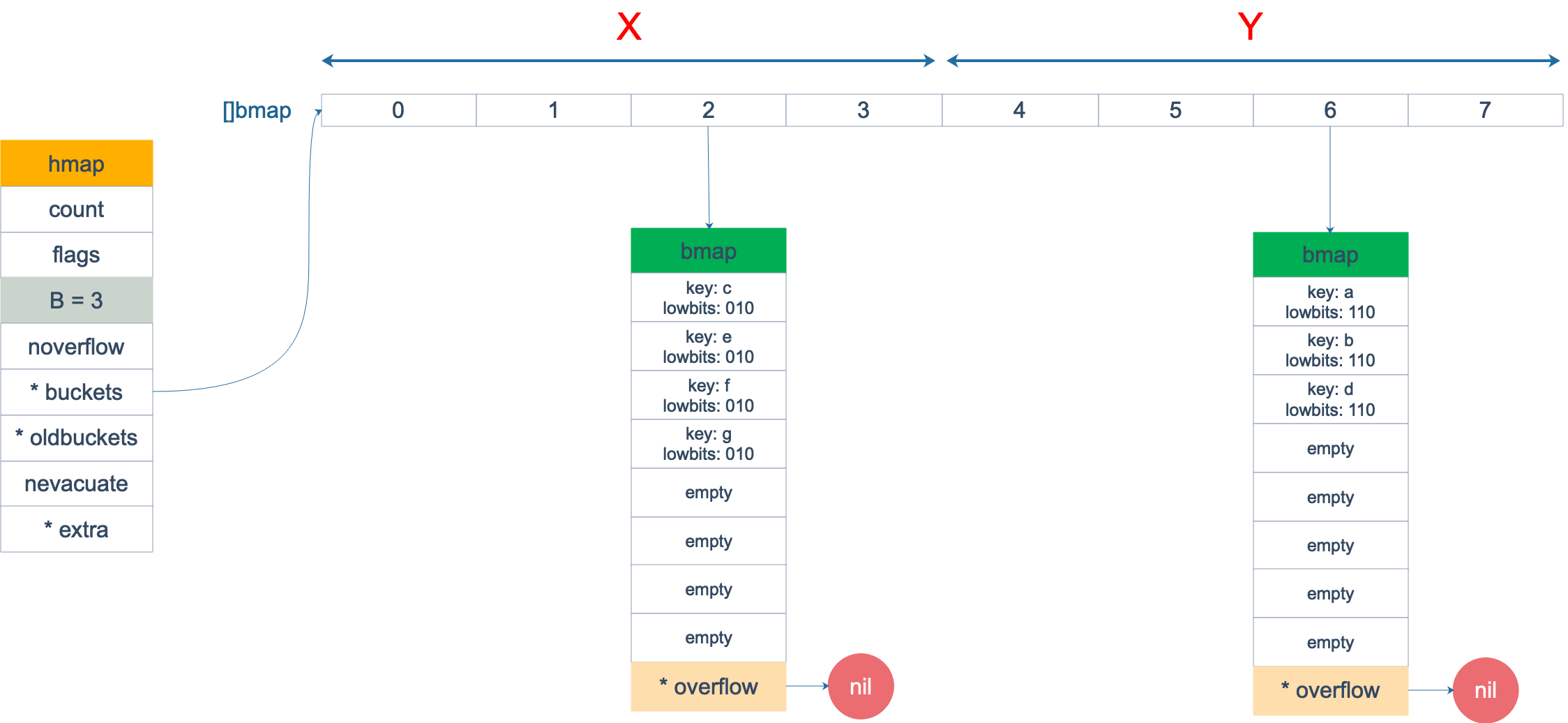
这个rehash过程,是渐进式完成的,每次只搬迁一个bucket。由nevacuate指示当前搬迁的进度,hash后定位到小于此的bucket查询new buckets,大于此的查询oldbuckets.
扩容中状态的hmap,每次写入和删除都会触发一次bucket的搬迁,
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}
sync.Mutex
最简单的mutex,可以使用CAS和semaphore实现,
- 原子的set一个变量(CAS)
- 通过semaphore,在mutex释放时唤醒等待该mutex的其它thread或coroutine
关于semaphore和cond的一点背景知识:Difference between Semaphore and Condition Variable
这也是Go V1版本mutex的实现方式,其后经过了多轮优化,
- V1: CAS + semaphore实现了最简单的mutex
- V2: V1版本等待mutex lock的goroutine是在一个FIFO队列,保证公平竞争,但性能不足。V2版本使新来的new goroutine也有机会先获取到lock(因为new goroutine已经持有CPU,省去了context切换的开销)
- V3: 版本使new goroutine获取到lock的机率提高(在block前spin一段时间,这段时间如果mutex unlock,则立即能lock)
- V4: 版本解决goroutine starvation问题(V3可能导致old goroutine等待很久或永远lock不了)
V1版本
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
// The structure of the mutex, containing two fields
type Mutex struct {
key int32 // Indication of whether the lock is held
sema int32 // Semaphore dedicated to block/wake up goroutine
}
// Guaranteed to successfully increment the value of delta on val
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// request lock
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { // Add 1 to the ID, if it is equal to 1, the lock is successfully acquired
return
}
semacquire(&m.sema) // Otherwise block waiting
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // Subtract 1 from the flag, if equal to 0, there are no other waiters
return
}
semrelease(&m.sema) // Wake up other blocked goroutines
}
V1版本是最简单的mutex,它的问题在于,它的lock等待是FIFO的,在某些场景下性能不足。
例如:
如果block的old goroutine(g1)当前没有持有CPU,则其被唤醒后,需要进行context切换。而如果一个new goroutine(g2)这时进来,它是已经持有CPU的。
如果lock给g2,它会立即执行而省去context切换的工作,因此总体的效率更高。V2就是实现这个方案。
V2版本
// A Mutex is a mutual exclusion lock.
// Mutexes can be created as part of other structures;
// the zero value for a Mutex is an unlocked mutex.
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexWaiterShift = iota
)
V2使用新的state代替key变量,其仍是int32但含义却发生了变化。
新的state低1位表示lock状态,低2位表示是否有new goroutine(woken goroutine, 上面描述的g2),高位表示有多少goroutine在等待lock这个mutex上。
当mutex unlock时,如果有一个g2(new goroutine,woken置位),则lock直接给g2(unlock不调用semrelease).否则走正常FIFO队列唤醒流程。
V3版本
通常情况,goroutine lock成功访问临界区的耗时,比起goroutine唤醒+context切换的时间要短的多。V2中new goroutine只有一次机会获取lock,而V3的改进是,让new goroutine spin一段时间,如果在这段时间mutex unlock了,new goroutine就可以立即lock成功,从而避免了block在队列头的goroutine唤醒和进行context切换的时间,提升整体性能。
核心改动是runtime_canSpin和runtime_doSpin,
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if raceenabled {
raceAcquire(unsafe.Pointer(m))
}
return
}
awoke := false
iter := 0
for {
old := m.state
new := old | mutexLocked
if old&mutexLocked != 0 {
if runtime_canSpin(iter) {
// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
continue
}
new = old + 1<<mutexWaiterShift
}
if awoke {
// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&mutexLocked == 0 {
break
}
runtime_Semacquire(&m.sema)
awoke = true
iter = 0
}
}
if raceenabled {
raceAcquire(unsafe.Pointer(m))
}
}
V4版本
V3版本使new goroutine有更多机会拿到lock,但却带来了old goroutine starvation问题:old goroutine长时间都拿不到lock。V4解决这个问题。
state又有了变更,加入了starving标志位(S位),
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving // separate out a starvation token from the state field
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)

什么情况下,当前lock被判定starved状态?
- old goroutine被唤醒了,但lock被new goroutine拿走了(old goroutine被唤醒什么也没做,又重新block了)
- goroutine被block的时间超过阈值(默认1ms)
对于starved lock的处理策略,
- 当前lock starved状态时,new goroutine不再spin
- 对于再次被block的old goroutine,它被放在blocking queue的队头,下次会优先唤醒它
- 再次被唤醒的old goroutine,不再需要跟new goroutine竞争lock,被唤醒后它会直接拿到lock
Pprof
CPU/Memory/Block/Mutex/Goroutine Profiling
数据结构
Hashtable
参考:Go map原理
LRU
LRU(Least Recently Used)使用一个双向链表和一个map来实现,双向链表中元素按最近访问时间排序,map中存放元素的key与其在链表中位置的映射,用于时间在链表中定位元素。链表的元素要包含key和value,因为cache满时有Remove Back操作,需要拿到key同步从map中删除。
一个Go语言版本,使用了标准库的container/list双向链表。
package main
import (
"container/list"
"fmt"
"sync"
)
func main() {
lru := NewLRUCache(5)
lru.Put("1", "2141")
lru.Put("2", "1243124")
lru.Put("2", "zaay")
lru.Put("3", "123123")
lru.Put("4", "346t24626t2")
lru.Put("5", "1234124124")
lru.Put("6", "asdfad")
lru.Get("7")
lru.Get("2")
lru.Get("4")
// 4, 2, 6, 5, 3
}
type Element struct {
Key string
Value string
}
type LRU struct {
sync.RWMutex
cache map[string]*list.Element
link *list.List
size int
capacity int
}
func NewLRUCache(capacity int) *LRU {
return &LRU{
cache: make(map[string]*list.Element),
link: list.New(),
capacity: capacity,
}
}
func (l *LRU) Get(key string) (string, error) {
l.RLock()
defer l.RUnlock()
v, ok := l.cache[key]
if !ok {
return "", fmt.Errorf("key not found")
}
l.link.MoveToFront(v)
return v.Value.(Element).Value, nil
}
func (l *LRU) Put(key string, value string) {
l.Lock()
defer l.Unlock()
v, ok := l.cache[key]
if !ok {
e := l.link.PushFront(Element{Key: key, Value: value})
l.cache[key] = e
l.size += 1
if l.size > l.capacity {
h := l.link.Back()
l.link.Remove(h)
delete(l.cache, h.Value.(Element).Key)
l.size--
}
} else {
if v.Value.(Element).Value == value {
l.link.MoveToFront(v)
} else {
l.link.Remove(v)
e := l.link.PushFront(Element{Key: key, Value: value})
l.cache[key] = e
}
}
}
LFU
LFU(Least Frequently Used)实现的一个思路是在LRU上做改造,有两点,
- Element中除了key, value,还需要记录元素访问次数freq
- 链表中的元素要先按freq排序,freq相同的再按访问(包含Get和Put)timestamp排序
但这里有个问题,因为LRU中元素只按访问时间排序,只需要把元素PushFront即可,因此才实现的复杂度。而按访问次数排序则不行,需要遍历链表来确认元素的新位置( 复杂度)。
复杂度)。
二叉查找树和skip list等都可以做到的插入和查找复杂度,因此可以拿来替换链表,将性能从优化到。
但仔细想想,我们其实并不需要所有元素的整体freq rank,而是只要知道freq且timestamp最小的那一个元素就可以了,为了这个目的使用小堆不划算。因此还能继续优化,
定义两个hashtable(map),一个minFreq变量,
- freq_table,freq作为key,value是该freq的元素组成的链表,链表按元素访问时间排序
- key_table,跟LRU一样,value为上述链表中的元素地址,用于定位元素
- 一个minFreq变量,记录缓存中的最小使用freq,为删除操作服务。当元素个数超过capacity时,通过它能快速在freq_table中拿到访问频率最低的链表,从链表尾部可以拿到访问时间最早的元素,删除之即可
这是一个的算法。
Skip list是一种增删改查都为的数据结构,它在有序链表上增加了多级(level)索引,通过索引来实现快速查找(二分思想)。因其实现简单且空间复杂度优秀,常被用来代替查找树使用。

索引的level数在实现中会设置一个限制,比如redis的skip list实现中默认限制为64层,而有序链表的每个元素是否建立索引,建立多少level,由投骰子随机决定。
Redis的ZSET使用skip list来实现score rank的查询功能,它的range和rank功能使用查找树(如rb-tree)均可以实现,但skip list拥有更好的空间性能。
127.0.0.1:6379> ZADD "id" 1 "Mark"
(integer) 1
127.0.0.1:6379> ZADD "id" 2 "Arthur"
(integer) 1
127.0.0.1:6379> ZADD "id" 3 "Monica"
(integer) 1
查看排名前两位的人,
127.0.0.1:6379> ZRANGEBYSCORE "id" 0 2
1) "Mark"
2) "Arthur"
Skip list的插入过程,
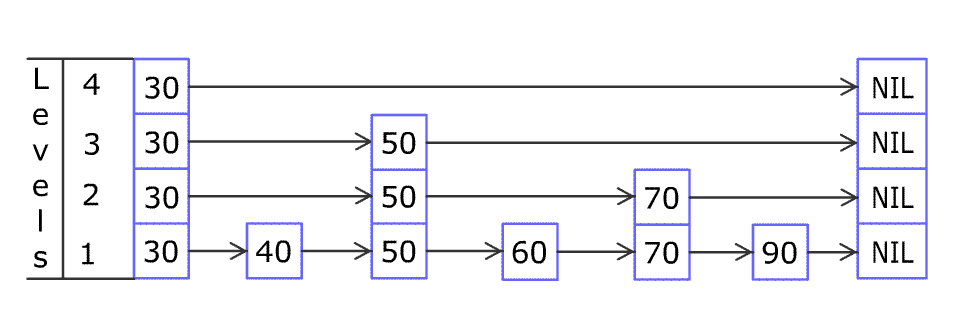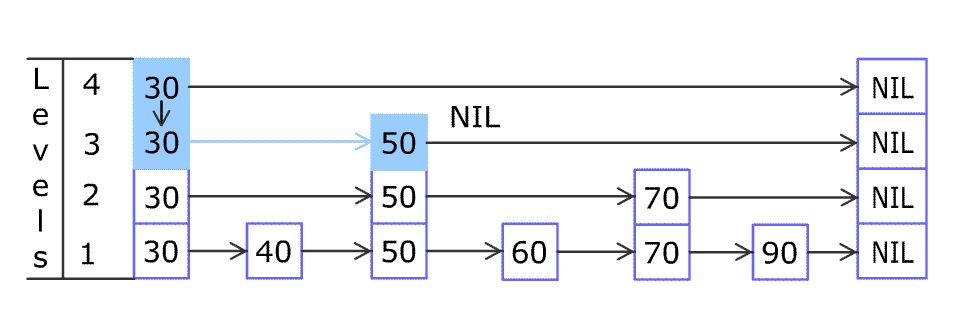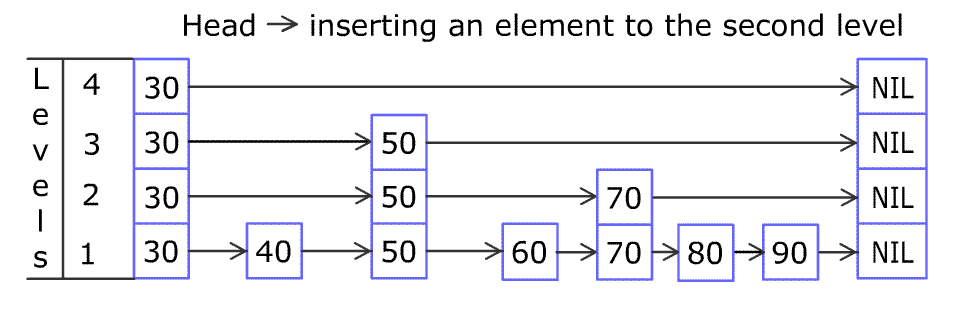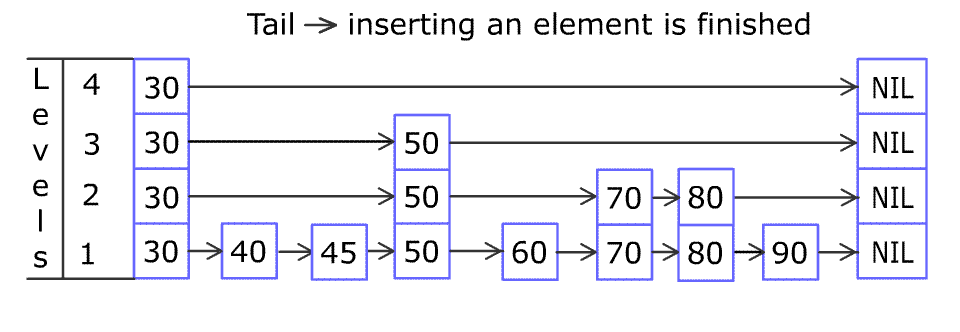
- 自top level至low level遍历索引,找到位置插入元素
- 从low level到top level,通过投骰子,建立索引
Ring buffer
Go channel的结构体中,有一个核心的数据结构是环形队列,环形队列可以用circular linked list实现,也可以用ring buffer(array)实现。
ring buffer对比1)普通数组,删除操作不需要移动元素,对比2)普通链表,入队和出队不需要频繁的内存申请和释放,因此不存在内存碎片的问题,对比3)circular linked list,它少了指针,占用内存更少。因此ring buffer整体是比较优的一个数据结构。
ring buffer的实现很简单,一个固定大小的ring数组,一个head指针和一个tail指针,数据在tail处写入,在head处读取。当写入速度大于读取速度时,即tail追上了head,要么覆盖,要么block,怎么实现都行。
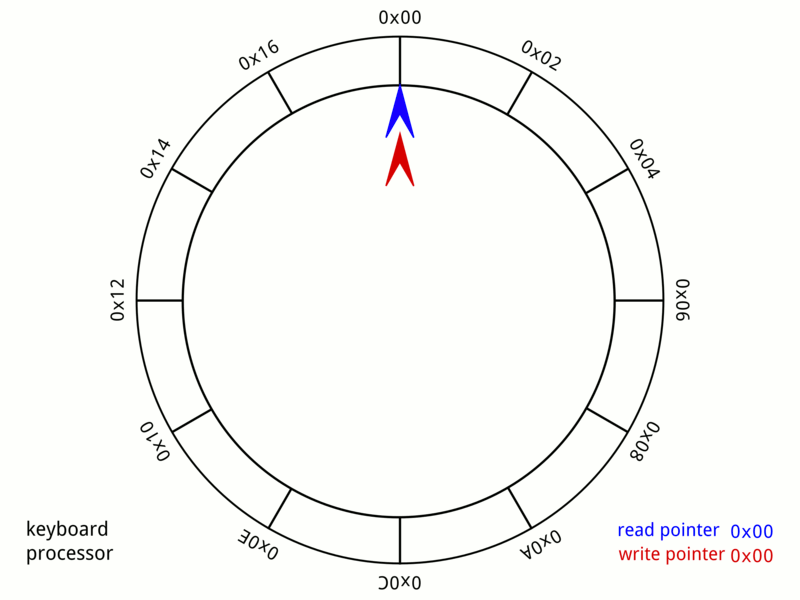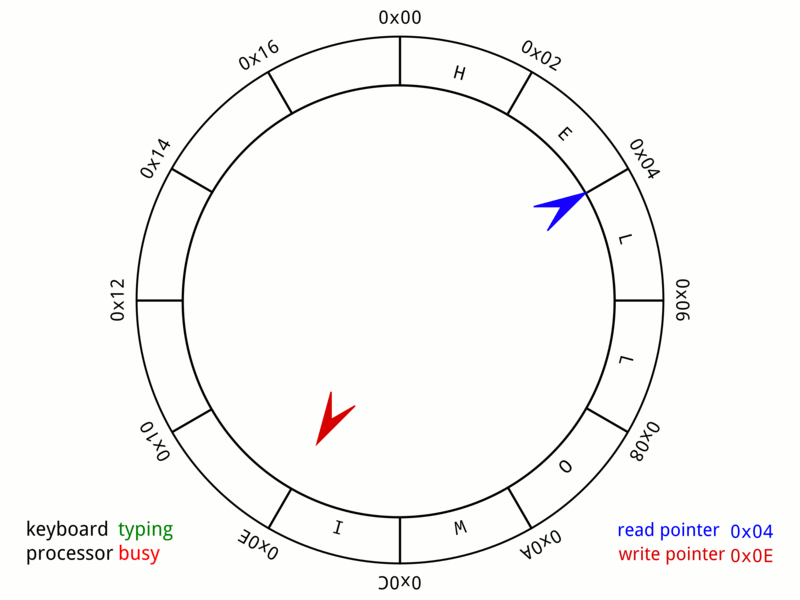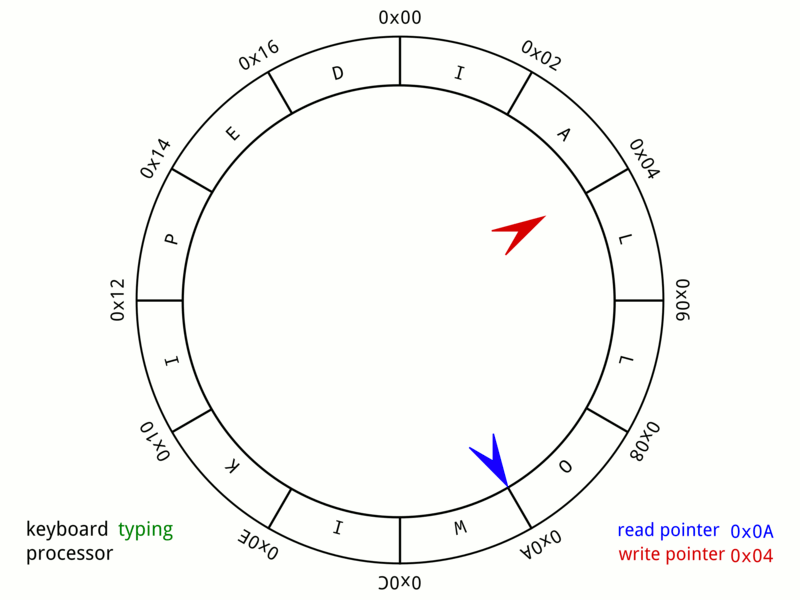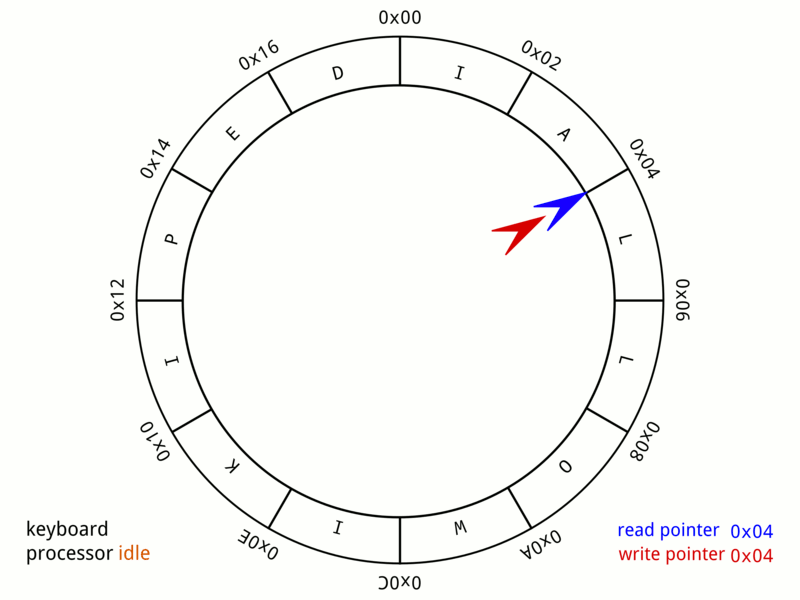
上图是wiki上一个键盘缓冲的ring buffer实例,它的大小是24bytes。红色是tail位置,蓝色是head位置,当队列满了时,即红针追上蓝针,则写入被block,继续输入电脑会咚咚提示。
普通实现的队列不是线程安全的,比如:DeQueue一个元素和tail移动不是个原子操作。要实现线程安全的队列,一种方式是加锁,读写时锁住整个队列,另一种方式是使用CAS实现lock free的队列。
Implementing Lock-Free Queues 介绍了实现方法,
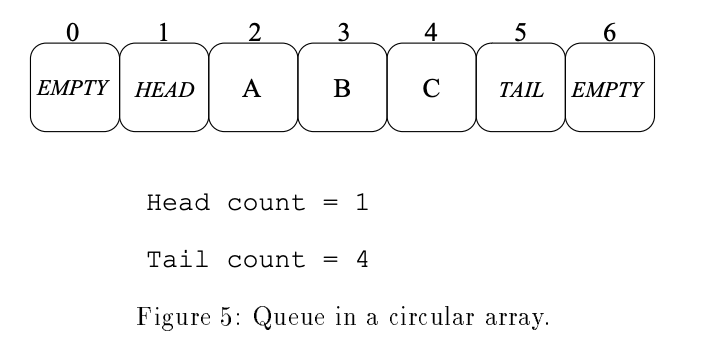
- 一个ring buffer数组,数组中元素有4种可能的值:HEAD,TAIL,EMPTY及数据本身
- 数组一开始全部初始化成EMPTY,有两个相邻的元素要初始化成HEAD和TAIL,这代表空队列
- EnQueue操作。假设数据x要入队列,定位TAIL的位置,使用double-CAS方法把(TAIL, EMPTY) 更新成 (x, TAIL)。需要注意,如果找不到(TAIL, EMPTY),则说明队列满了
- DeQueue操作。定位HEAD的位置,把(HEAD, x)更新成(EMPTY, HEAD),并把x返回。同样需要注意,如果x是TAIL,则说明队列为空
Roaring bitmap
Bitmap大小固定,存放稀疏数据时比较浪费空间。Roaring bitmap可以解决这个问题,以32位无符号整数存储为例。
首先按照高16位分桶,即最多可能有2^16个桶(论文内称为container)。存储数据时,按照数据的高16位找到container,再将低16位放入container中。
Container有两种不同类型:ArrayContainer和BitmapContainer,当container内数据的基数不大于4096时使用ArrayContainer存储,当container内数据的基数大于4096时使用BitmapContainer存储,BitmapContainer本质是一个普通bitmap。
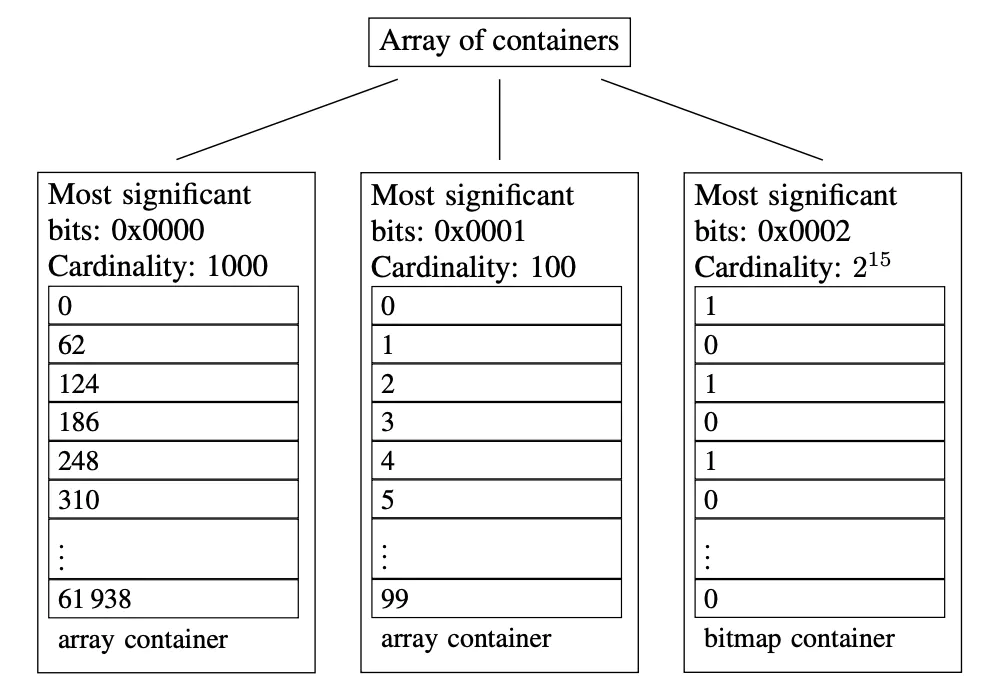
低于4096时ArrayContainer比较省空间,高于它时BitmapContainer比较省空间,ArrayContainer存储稀疏数据,BitmapContainer存储稠密数据,可以最大限度地避免空间浪费。
HyperLogLog
非精准的基数计数,原理是基于伯努力实验。Redis中HLL类型占12K,能对2^64个数进行计数,误差在0.81%.
伯努力实验
在同样条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生(抛硬币是一种典型的伯努力实验)。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验。
抛硬币
出现正反面的概率都是1/2,一直抛硬币直到出现正面,记录投掷次数k,这种多次抛硬币直到出现正面的过程就是一次伯努利试验。
对于n次伯努利过程,我们会得到n个出现正面的投掷次数值:k1,k2……kn,其中最大值记为kmax,那么可以得到下面结论:
- n 次伯努利过程的投掷次数都不大于 kmax:𝑃𝑛(𝑋≤𝑘𝑚𝑎𝑥)=(1−1/2𝑘𝑚𝑎𝑥)𝑛
- n 次伯努利过程,至少有一次投掷次数等于 kmax:𝑃𝑛(𝑋≥𝑘𝑚𝑎𝑥)=1−(1−1/2𝑘𝑚𝑎𝑥−1)𝑛
结合极大似然估算,得出:n = 2^(k_max)。即n次抛硬币试验,记录首次抛到正面的次数k,则可以用2^kmax 估算n的大小。
Redis实现
具体实现中,Redis中一个HLL分了2^14个桶(register,每个桶6bit,总共占12K),每个64bit数字高14位定位桶,低50位中,从右向左计算首次出现1的位置k,将k与桶中旧值比较,大于则替换旧值,否则丢弃。
在计算基数时,分别计算每个桶中的值,再带入HLL公式中,得出最终估算的基数。(公式略)
Bloom filter

False positive问题。BF告诉在的并不一定在。