MyBlog
A Quick Refresh of Key Bigdata Topics
last modified: 2023-01-19 16:09

- 数仓模型
- Flink
- Spark
- 数据架构kappa/lambda/流批一体
- Apache Hudi(Hadoop Upsert Delete and Incremental)
- HDFS
- 存储(CK/Druid/HBase/Doris)
- End.
数仓模型
3NF(Normal Forms)范式建模
ER(Entity Relationship)模型
1NF(属性原子性)
- the attribute of every tuple is either single valued or a null value
不符合1NF表设计:
| Student_id | Name | Subjects |
|---|---|---|
| 100 | Akshay | Computer Networks, Designing |
修正,使其符合1NF:
| Student_id | Name | Subjects |
|---|---|---|
| 100 | Akshay | Computer Networks |
| 100 | Akshay | Designing |
2NF(唯一主属性)
- Relation already exists in 1NF.
- No partial dependency exists in the relation.
2NF要求,非主属性完全依赖主属性,即不存在partial dependency。
不符合2NF表设计的例子(存在partial dependency):
| Student_id | Name | Subject_id | Score |
|---|---|---|---|
| 100 | Akshay | 6 | 2 |
其中学分(Score) depend on 课程(Subject_id),而姓名(Name)depend on 学号(Student_id),即存在Partitial dependency.
存在的问题如:更新课程学分,则所有选择该课程的行都要调整。
修正,拆表使其符合2NF:
学生表:
| Student_id | Name |
|---|---|
| 100 | Akshay |
课程表:
| Subject_id | Score |
|---|---|
| 6 | 2 |
学生选课表:
| Student_id | Subject_id |
|---|---|
| 100 | 6 |
此时更新学分,只需要更新课程表中的一行。
3NF(不存在相关非主属性)
- Relation already exists in 2NF.
- No transitive dependency exists for non-prime attributes.
3NF要求,非主键属性之间独立无关,即不存在transitive dependency。
下表设计符合2NF(因为主键是单个属性Student_id),但不符合3NF(因为存在transitive dependency: College->College_mobile):
| Student_id | Name | Age | College | College_mobile |
|---|---|---|---|---|
| 100 | Akshay | 22 | Soft Engineering | 7052445 |
修正,拆分学生和学院表,
学生表:
| Student_id | Name | Age | College_id |
|---|---|---|---|
| 100 | Akshay | 22 | 2 |
学院表:
| College_id | Name | Mobile |
|---|---|---|
| 2 | Soft Engineering | 7052445 |
维度建模
按照事实和维度表来构建数据仓库、数据集市。在维度建模中,维度是描述事实的角度,事实是要度量的指标。
星型模型、雪花模型都属于维度模型。

维度建模四步曲:选定业务过程、声明粒度、确定维度、构建事实。—— by Kimball
维度建模的优点是易于理解,建模出来的表与业务的直观感受相符,使用起来方便。并且没有数据冗余。
缺点是查询要关联多张维度表,比起宽表性能要差。另外事实表中业务发生时的维度值,可能与维度表中记录的不一致,如果业务需要,则要做维度的snapshot.
具体实践中,维度模型可以与宽表结合使用。
Flink
架构
Flink的运行时由两种类型的进程组成:一个JobManager,和一个或者多个TaskManager ™。

JobManager
JobManager进程由3个模块组成,
- ResourceManager: 管理task slots
- Dispatcher: 提供REST接口,负责job提交
- JobMaster: 管理单个JobGraph执行,协调checkpoint,处理task failover等
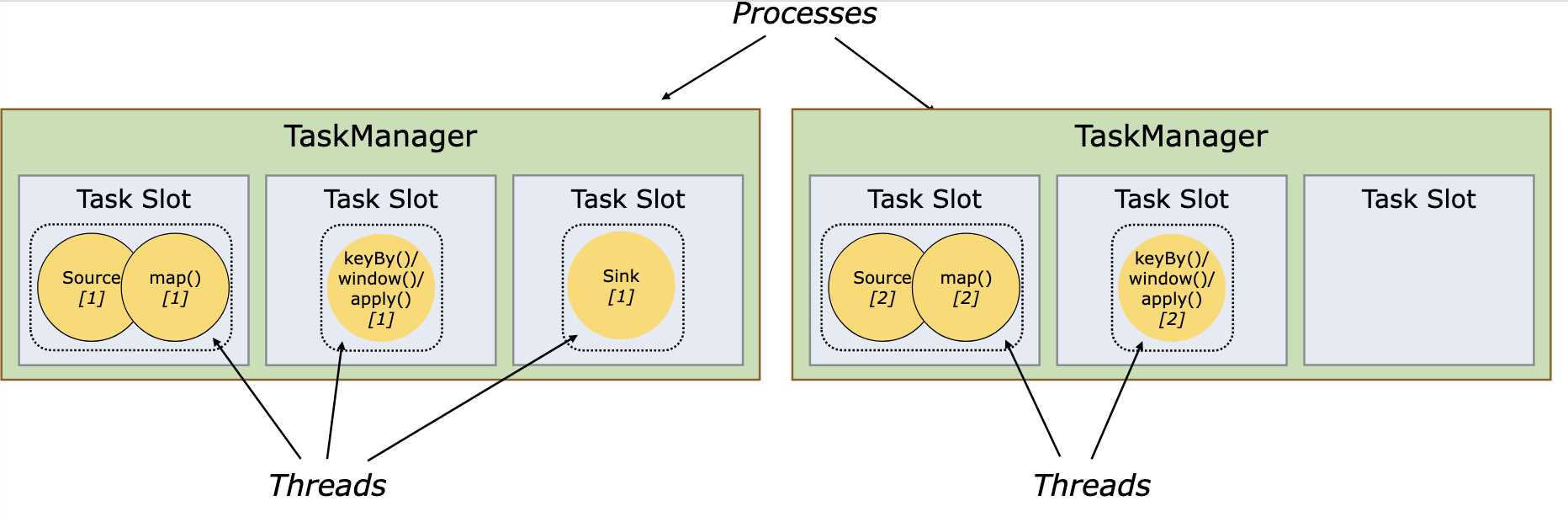
TaskManager
TM中资源调度的最小单位是task slot。
task slot的数量表示可并发处理的subtask数量,一个task slot可以运行多个subtask。task slot独享内存,task slot之间共享CPU、TCP链接和心跳等信息。
task与subtask:
- task是一个阶段多个功能相同subtask的集合
- subtask是flink的任务最小执行单元。一个subtask可以包含多个算子。如下图,红框代表task,黑框代表subtask,共有3个task和5个subtask
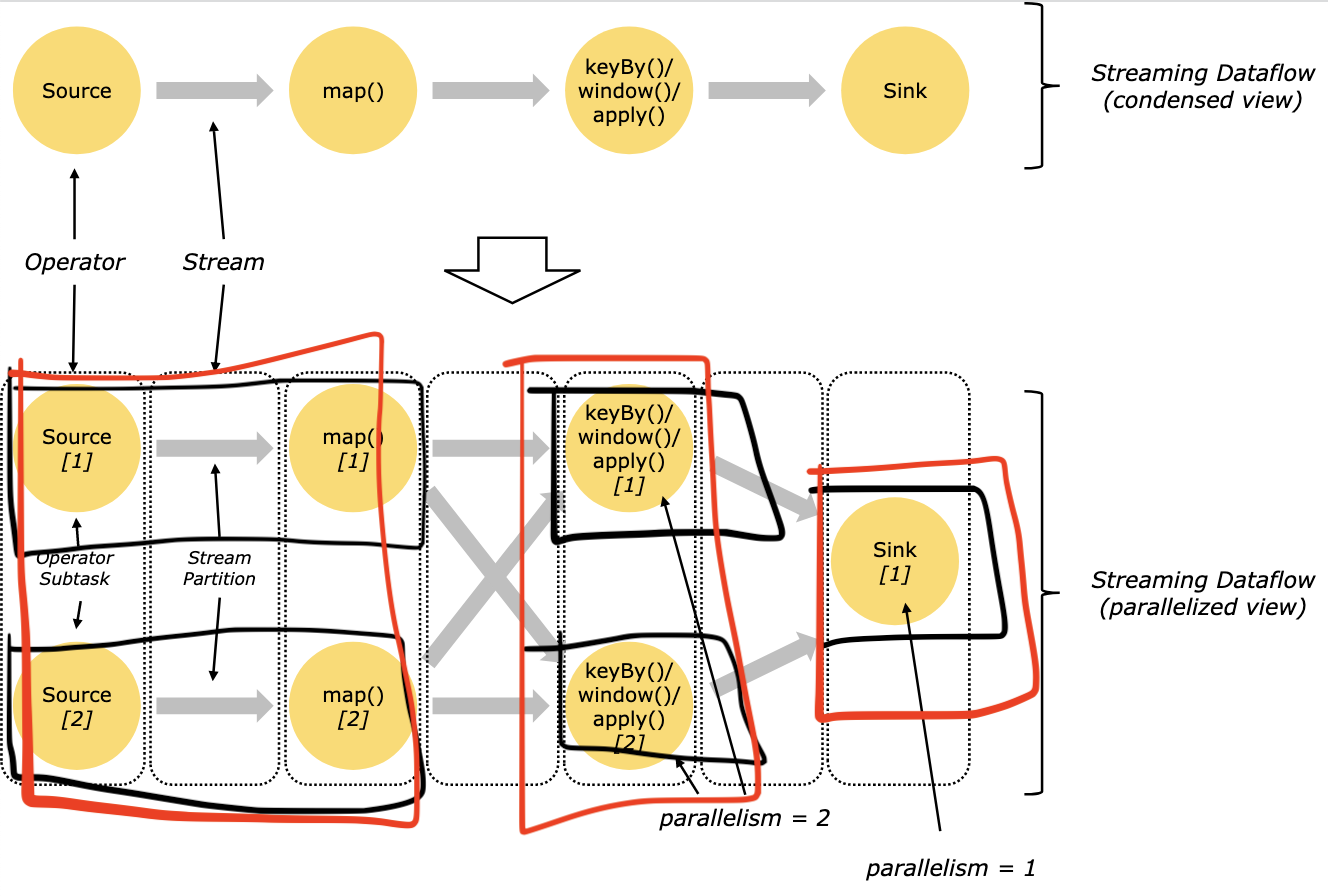
以TM的视角看,5个subtask分配到5个task slot中,每个slot是TM进程下的一个子线程:
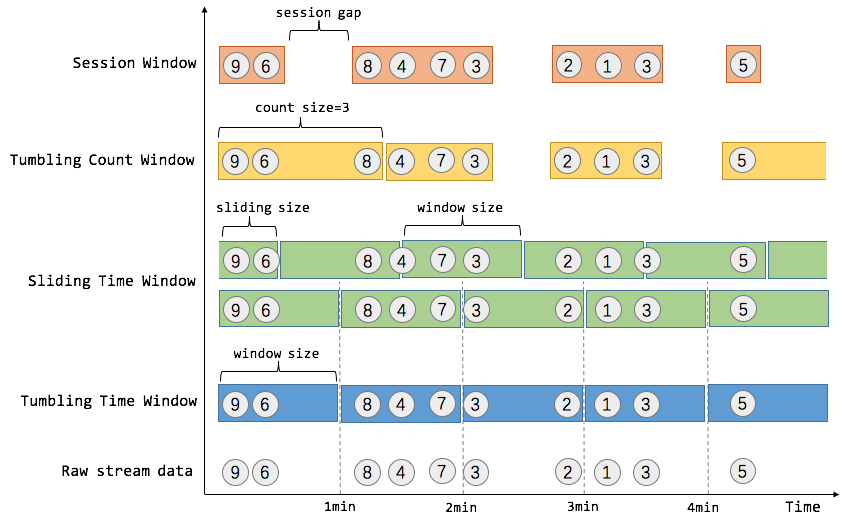
Window
在unbounded的流上做计算,要用到Window。Window的类型有,
Flink中Window的实现机制(下图的组件都位于一个Window Operator中),
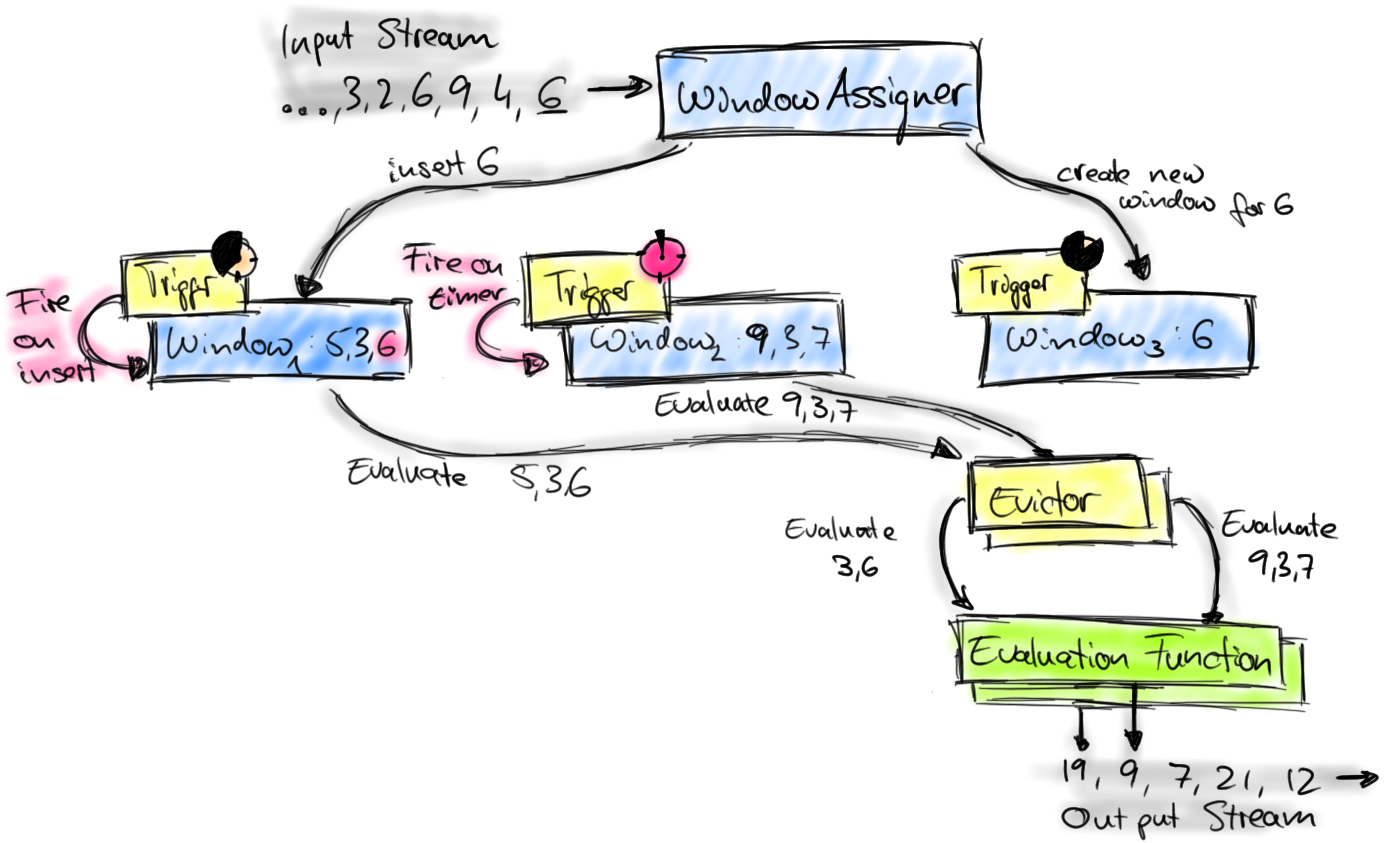
- input stream中的元素6首先到达Window Assigner。(位于图中最上)
- Window Assinger决定将元素6放到某个Window(也可以新开Window,比如Sliding Window的情况,图中最右即新开Winwow)
- 每个Window都有一个Trigger,Trigger有两个触发条件:定时器超时,或新元素进入Window
- Trigger触发的结果可能是:continue(不做任何操作),fire(处理Window数据),purge(移除Window和Window中的数据)
- 当Trigger fire了,由图中最下面的Evalution Function进行计算并输出output stream
Evictor不用管,它是一个过滤器,若指定了Evictor则不能在Window中做计算,而要保留元素本身,因为Evictor过滤时需要遍历之。(实际元素并不是在Window中保存,数据是存在flink state中的,key为Window,value为元素集合或者计算结果)
Watermark
在unbounded的流中,Window需要被触发计算,不能无限期的等下去。而Watermark是在数据乱序场景下,保证Window触发的一种机制。
Watermark本质是timestamp,一般在source算子生成(source的每个subtask独立生成Watermark),当它到达下游算子,会推进算子的当前event time,表示该event time之前的所有数据都已到达,算子中结束时间在此之前的Window都可以被触发了。
对于有多个输入channel的算子,取最小的event time。

Watermark通常Periodic生成(实际有Periodic和Punctuated2种方式),需要实现2个方法,
- onEvent:流数据到达时通过event timestamp算currentMaxTimestamp
- onPeriodicEmit:周期性将Watermark发送到下游算子
最常用的 BoundedOutOfOrderness 生成示例:
public class BoundedOutOfOrdernessGenerator implements WatermarkGenerator<MyEvent> {
private final long maxOutOfOrderness = 3500; // 3.5 seconds
private long currentMaxTimestamp;
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// emit the watermark as current highest timestamp minus the out-of-orderness bound
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
上文,event time取上游最小值,若一个上游一直没数据怎么办?以Kafka source为例,可能某个Partition没有数据,导致Watermark不能推进。
为此flink提供了一个WatermarkStrategy,将某个input标记为idle,
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
Window触发后,迟到的数据又来了怎么办?
一是Allowed Lateness机制,它允许Window被Watermark触发后,仍存在一段时间(state不马上purge),这段时间如果late数据到达,则重新触发Window计算。
二是如果超过了allowedLateness仍不想丢弃的话,可以通过Side Output机制将其输出。
脏数据,比如消息中带的是未来的event timestamp,将Watermark推高怎么办?
可以在onEvent时,取min(currentMaxTimestamp, now())。
EOS(Exactly-Once Semantics)
由三部分共同保障:
- Source端可回溯:如kafka offset机制
- Flink自身:分布式快照算法->state checkpoint机制
- External state支持幂等写或2PC:如kafka
Back Pressure问题
flink 1.5及之前采用tcp-based back pressure. 之后采用credit-based back pressure.
Analysis of Network Flow Control and Back Pressure
发现Back pressure
Flink Web UI的back pressure监控提供了subtask级别的back pressure监控。监控的原理是通过Thread.getStackTrace()采集在TM上正在运行的所有线程,收集在缓冲区请求中阻塞的线程数(意味着下游阻塞),并计算缓冲区阻塞线程数与总线程数的比值rate。其中,rate < 0.1 为 OK,0.1 <= rate <= 0.5 为 LOW,rate > 0.5为HIGH。

定位原因
(1)数据倾斜
- 通过Subtask的Records Sent和Records Received判断
- 通过在Checkpoint中查看各Subtask的Checkpointed Data Size判断

(2)代码问题
对TM进行CPU profile,若CPU跑满,则分析CPU花在哪个函数上。若未跑满,则分析TaskThread阻塞在哪里,可能是用户函数自身的问题,如有同步调用,也可能是checkpoint/GC等系统活动等原因导致的。
(3)TM的内存以及GC
通常是频繁的Full GC,通过-XX:+PrintGCDetails打印GC日志观察之。
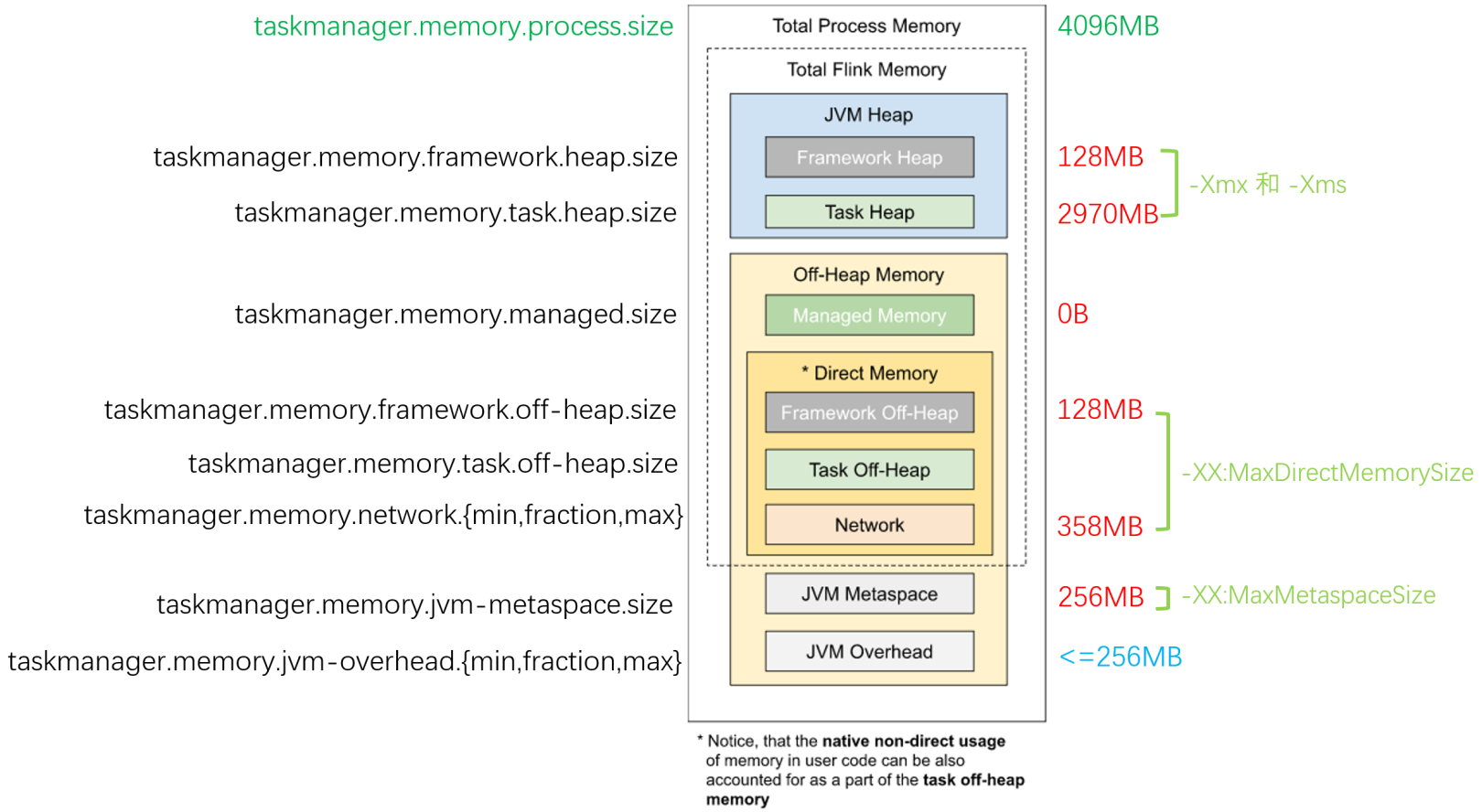
资源优化及问题定位
Flink任务问题的排查思路,
- 看核心metrics:吞吐量、延迟,及GC是否正常
- 看是否有back pressure,通常最后一个被压高的subtask的下游一般就是job的瓶颈
- 看checkpoint,时长及size,checkpoint过长影响job吞吐
一些优化方向,
JobManager/TM JVM参数调优
防止Full GC等,追求最优使用率。一般不使用RocksDB作为状态后端的话,managed memory可以省掉。
调整并行度(setParallelism)
追求TM利用率,提升并行处理性能,
并行度的上限是TM slot的数量,但并不是并行度越大越好,还要考虑资源利用效率。一般core/mem是固定的,我们设置合适利用率下的最小并行度即可
设计合理的分区(keyBy)
防止subtask的数据倾斜
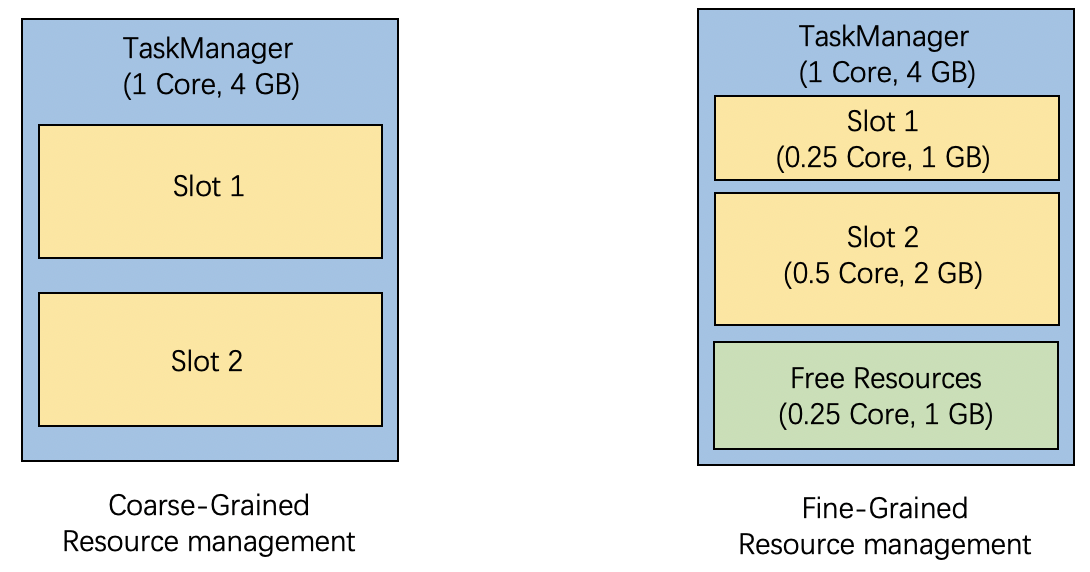
细粒度TM内存调节(Fine-Grained Resource Management)
对于大型任务,
1)task有明显并行度差异(拥有fewer task的slot需要较少资源,固定分配就浪费了)
2)Pipeline太大,单个slot/TM装不下(因此被切成多个SSGs/slot sharing groups,而每个SSG所需资源不同)
JM将同一SSG的operators/tasks放到同一个slot。具体用法为:
1)定义SSG以及它包含的算子,2)为SSG指定不同资源配置参数
Checkpoint参数调节
interval,timeout, unaligned
Spark
架构模式:MapReduce
目的:MapReduce中间计算结果落盘,在迭代计算的场景下效率低下,因为迭代计算下一步依赖上一步结果
实现:设计一种内存结构(Spark中的RDD:Resilient Distributed Dataset),中间结果不落盘,而是通过网络在worker内存间传递
RDD
只读
RDD是只读的,一个RDD通过转化生成另一个RDD(通过transformations算子)
分区
RDD是逻辑的,实际有物理的分区,分区使能在RDD上做并行计算
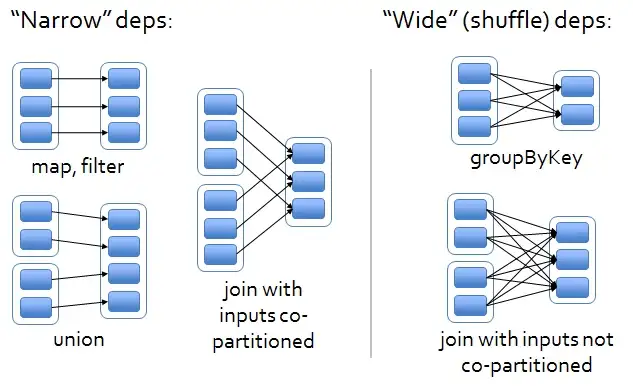
依赖
RDD从一个或多个上游RDD转化而来,RDD间这种血缘关系叫依赖,RDD间通过依赖构成DAG(Directed acyclic graph)。依赖分宽、窄依赖
窄依赖:RDDs之间分区是一一对应的
宽依赖:下游RDD的每个分区与上游RDD的每个分区都有关,是多对多的关系
高可用
当RDD的某个分区数据失败或丢失,可以通过血缘关系重建
但是对于迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据持久化
物理架构
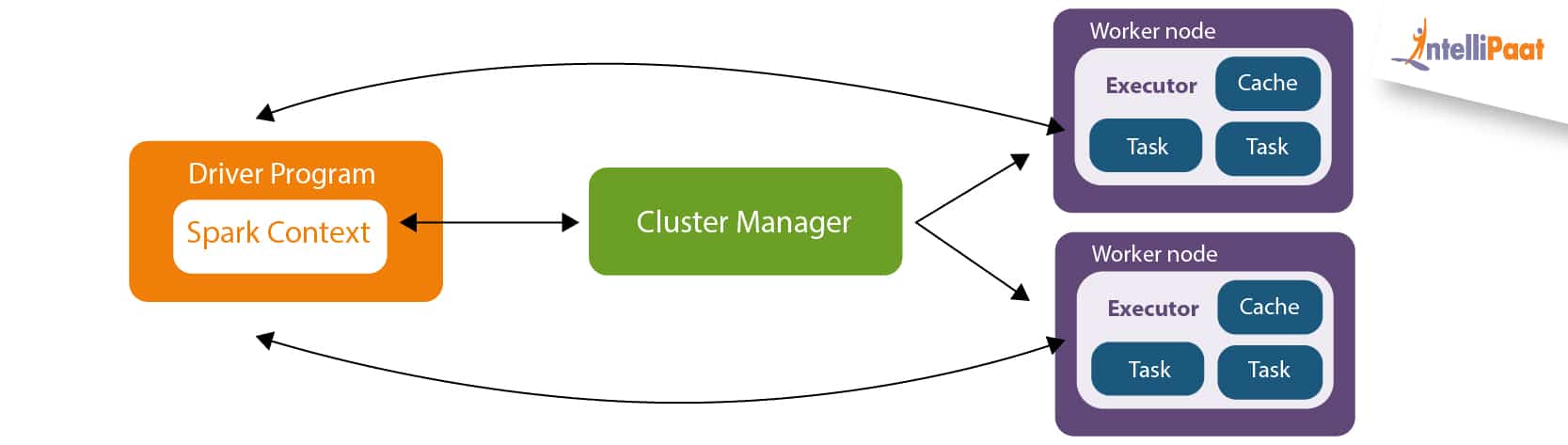
Driver
(MapReduce Master)Driver调用main函数,创建SparkContext. 包括DAG Scheduler, Task Scheduler,它把用户代码转化成job(consist of stages and tasks),提交至cluster执行
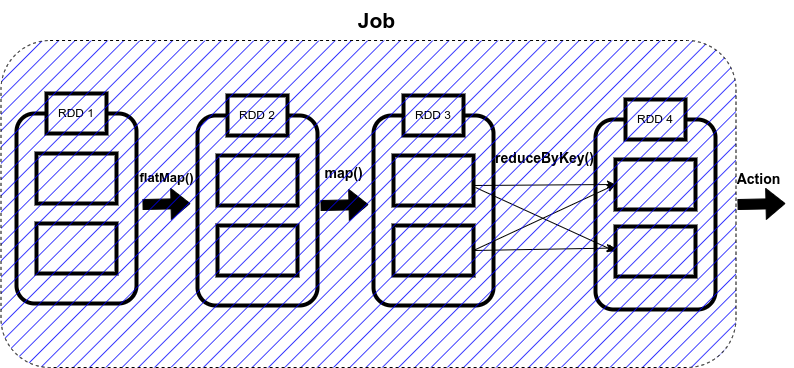
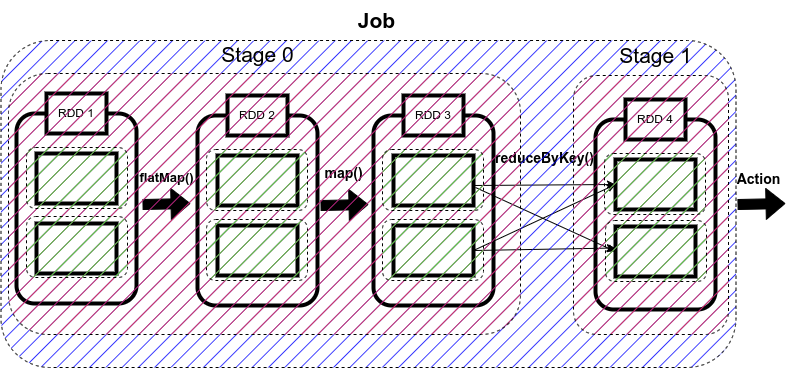
Job由stages组成,当shuffling时生成stage

Stage由tasks构成,task是spark的最小执行单元
Cluster Manager
负责job资源分配
Worker
(MapReduce Worker)负责执行tasks(由executor具体负责执行),它执行算子,生成并缓存RDD,并上报状态给driver
JOIN
- shuffle hash join
- broadcast hash join
- sort merge join
hash join
SELECT *
FROM order, item
WHERE item.id = order.item_id
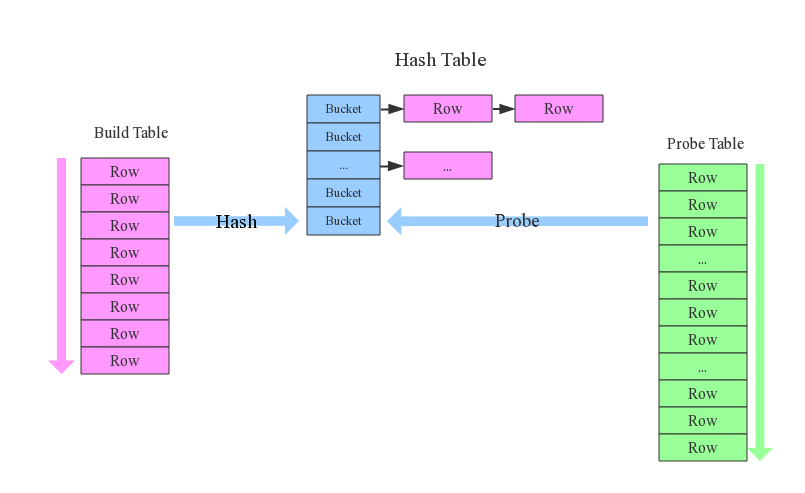
join 步骤:
- 确定Build Table以及Probe Table:Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table(因为最好全部加载到内存)
- 构建Hash Table:依次读取Build Table 的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket
- 探测:扫描Probe Table的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件,如果匹配成功就可以将两者join在一起
hash join 分布式改造,
broadcast hash join
将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景
怎么算小表,在 spark 上:spark.sql.autoBroadcastJoinThreshold,默认为10M
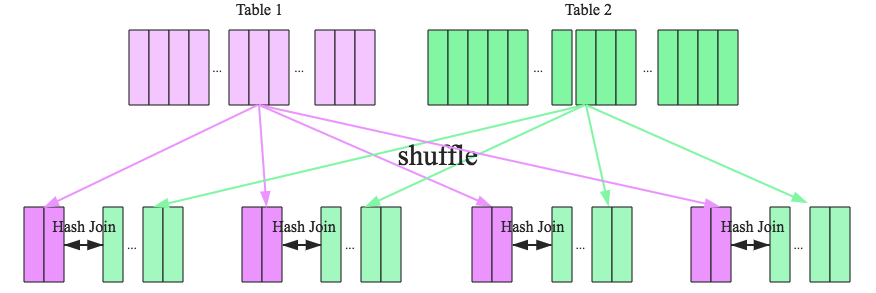
shuffle hash join
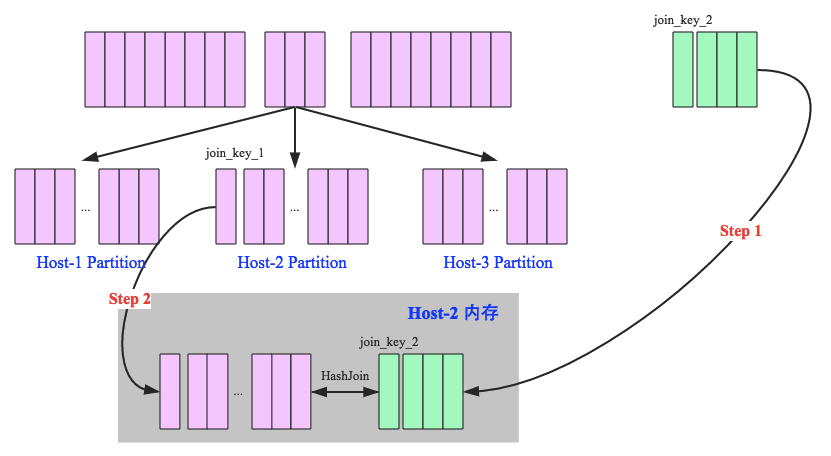
一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之
步骤,
- shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle
- hash join阶段:每个分区节点上的数据单独执行单机hash join算法
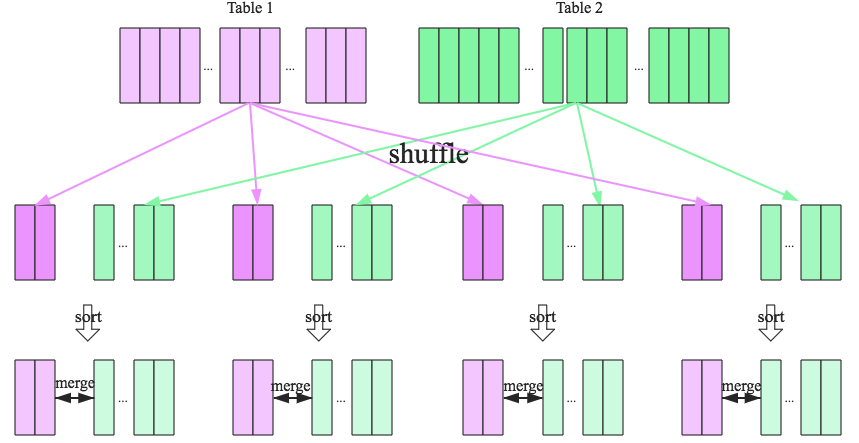
sort merge join
适应于两张大表的join,步骤,
- shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理
- sort阶段:对单个分区节点的两表数据,分别进行排序
- merge阶段:对排好序的两张分区表数据执行join操作,join的过程类似多路归并排序算法
实际是,spark的shuffle是sort based shuffle,1/2是一起完成的
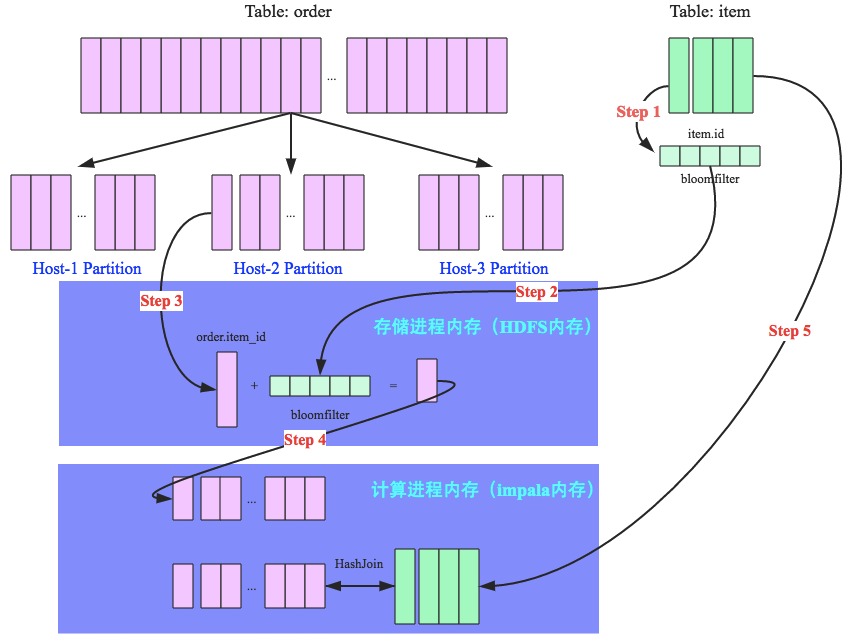
Runtime Filter(谓词下推)
## 取出category为book的所有order
SELECT item.name, order.*
FROM order, item
WHERE order.item_id = item.id
AND item.category = 'book'
假设:订单很多,但book category的商品不多,则优化过程为,
- 构建 category 为 book 的 item_id 的 BF
- 将该 BF 发到 order 存储机器上
- 在将 order 发送到 join 计算节点前,先在本地过滤出 BF 对应的order
- 过滤后的 order 发到计算节点
- hash join
因此,order 表(大表)数据不需要全部发送到计算,BF 过滤掉的订单越多,性能提升越明显。
数据架构kappa/lambda/流批一体
Lambda架构
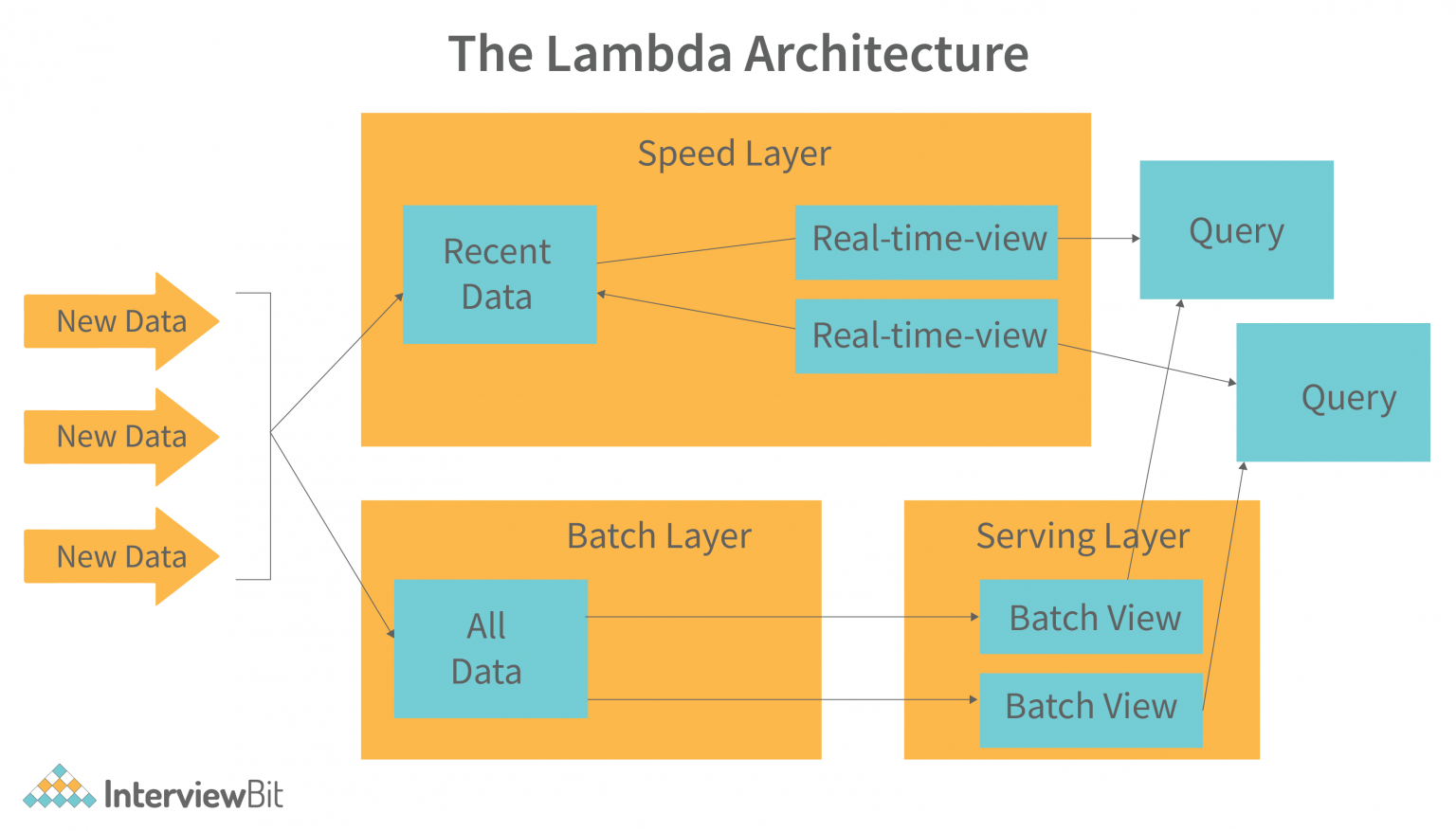
核心思想是将不可变的数据以追加的方式并行写到批和流处理系统内,随后将相同的计算逻辑分别在流和批系统中实现,并且在查询阶段合并流和批的计算视图并展示给用户。
Lambda的提出者Nathan Marz还假定了批处理相对简单不易出现错误,而流处理相对不太可靠,因此流处理器可以使用近似算法,快速产生对视图的近似更新,而批处理系统会采用较慢的精确算法,产生相同视图的校正版本。
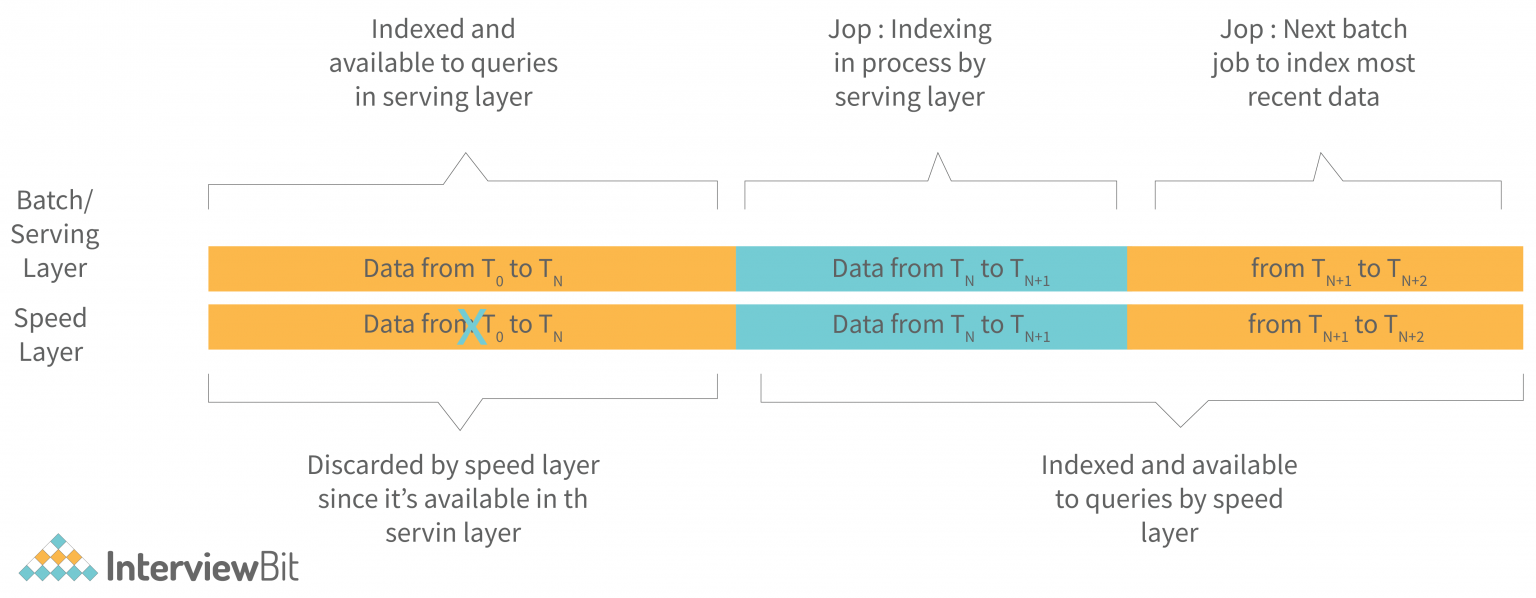
| 角色 | 功能 |
|---|---|
| Batch layer | 1.管理master dataset,存储的是不可变、追加写的全量数据 2.预计算batch view |
| Serving layer | 对batch view建立索引,支持低延迟查询,ad-hoc查询 |
| Speed layer | 实时计算近似的real-time view,作为高延迟的batch view的补偿快速视图 |
Lambda架构的问题
- 数据写入:Lambda 没有对数据写入进行抽象,而是将双写流批系统的一致性问题反推给了写入数据的上层应用
- 存储:以HDFS为代表的 master dataset 不支持数据更新,持续更新的数据源只能以定期拷贝全量 snapshot 到 HDFS 的方式保持数据更新,数据延迟和成本比较大
- 计算:计算逻辑需要分别在流批框架中实现和运行
- 展示:结果视图要支持低延迟的查询分析,通常还需要将数据写到OLAP存储上
对于问题3,一些框架如flink已经开始支持流批一体的计算。
Kappa架构

Kappa 架构由 Jay Kreps 提出,不同于 Lambda 同时计算流计算和批计算并合并视图,Kappa 只会通过流计算一条的数据链路计算并产生视图。Kappa 同样采用了重新处理事件的原则,对于历史数据分析类的需求,Kappa 要求数据的长期存储能够以有序 log 流的方式重新流入流计算引擎,重新产生历史数据的视图。
Kappa方案通过精简链路解决了1-数据写入和3-计算的问题,但它依然没有解决存储和展示的问题。
Kappa是Lambda的精简版,比较适合于数据append only的场景,比如时序数据,更新的场景其回溯数据很难(性能,资源使用)。
Kappa+ 架构
Kappa+是Uber提出流式数据处理架构,它的核心思想是让流计算框架直读HDFS类的数仓数据,一并实现stream和batch计算。
Uber开发了Apache Hudi框架来存储数仓数据,hudi支持更新、删除已有数据,也支持增量消费数据更新部分,从而系统性解决了问题2-存储的问题。
Uber Kappa+ detail:

Uber Kappa+ summarize:
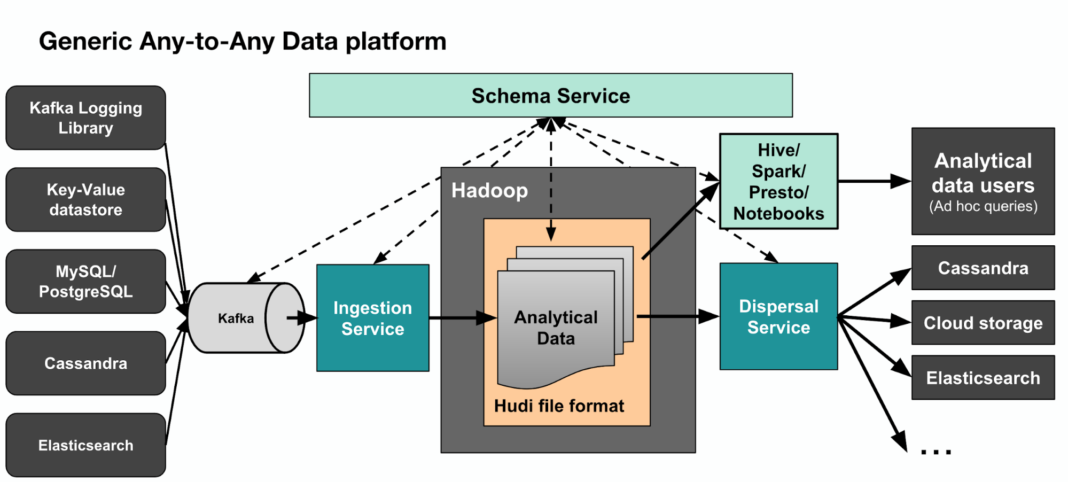
Apache Hudi(Hadoop Upsert Delete and Incremental)
Hudi最初的设计目标,从名字就可以看出:在hadoop上实现update和delete操作。
Hudi是uber发明的,为什么要让hadoop支持update和delete呢?
最初uber使用的是Lambda架构,但是有个问题是计算逻辑分为stream和batch两种,要保持两者的逻辑完全一致很困难(毕竟是两套代码)。
然后uber转向了Kappa架构,使得两套代码变为一套,但是存储依然有两套,分别支持stream写入和batch写入。
为了把存储也统一起来,就需要让负责batch写入的存储系统也能支持stream写入,这就产生了update和delete的需求。
这里核心要解决的问题是,
如何在只支持overwrite的hadoop上实现upsert(update+insert+delete)?
一个最朴素的思路,
把一个完整的文件拆分为多个“小文件”,当需要更新其中某条记录时,只要把包含这条记录的“小文件”给重写一遍即可。
Upsert实现 & COW(Copy On Write)
首先,假设向一张Hudi表中预先写入了5行数据,如下,
| txn_id | user_id | item_id | amount | date |
|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 20220101 |
| 2 | 2 | 1 | 1 | 20220101 |
| 3 | 1 | 2 | 3 | 20220101 |
| 4 | 1 | 3 | 1 | 20220102 |
| 5 | 2 | 3 | 2 | 20220102 |
这时在HDFS(hadoop)里面,会有下面2个目录,以及1个隐藏的.hoodie目录(里面保存了hudi的元数据)。
warehouse
├── .hoodie
├── 20220101
│ └── fileId1_001.parquet
└── 20220102
└── fileId2_001.parquet
文件名分为两部分,fileId是Hudi中的一个概念,后面会做解释,001则是commitId。画成图就是,

可以看到,属于20220101分区的3条数据保存在一个parquet文件:fileId1_001.parquet,属于20220102分区的2条数据则保存在另一个parquet文件:fileId2_001.parquet。
然后我们再写入3条新的数据。其中有2条数据是新增,1条数据是更新。写入的数据如下,
| txn_id | user_id | item_id | amount | date |
|---|---|---|---|---|
| 3 | 1 | 2 | 5 | 20220101 |
| 6 | 1 | 4 | 1 | 20220103 |
| 7 | 2 | 3 | 2 | 20220103 |
写入完成后,hdfs里面的文件结构会变成这样,
warehouse
├── .hoodie
├── 20220101
│ ├── fileId1_001.parquet
│ └── fileId1_002.parquet
├── 20220102
│ └── fileId2_001.parquet
└── 20220103
└── fileId3_001.parquet
画成图就是,

可以看到,更新的那一条记录,实际被写入到了同一个分区下的新文件:fileId1_002.parquet。这个新文件的fileId和上一个相同,只不过commitId变成了002。
同时还有一个新文件:fileId3_001.parquet。
Upsert到这里就算完成了,那么使用这张表的用户又是如何读到更新以后的数据呢?
Hudi客户端在读取这张表时,会根据.hoodie目录下保存的元数据信息,获知需要读取的文件是:fileId1_002.parquet,fileId2_001.parquet,fileId3_001.parquet。这些文件里保存的正是最新的数据。

Upsert细节
Hudi使用spark接口进行upsert的代码,
df.write.format("hudi").
option(RECORDKEY_FIELD_OPT_KEY, "txn_id").
option(PARTITIONPATH_FIELD_OPT_KEY, "date").
option(TABLE_NAME, tableName).
mode(Overwrite).
save()
两个必填的配置项:
- RECORDKEY_FIELD_OPT_KEY: 指定作为recordKey的字段名
- PARTITIONPATH_FIELD_OPT_KEY: 指定作为partitionPath的字段名
Upsert的过程整体分为3步(这里省略了很多不太重要的步骤):
- 根据partitionPath进行重新分区
- 根据recordKey确定哪些记录需要插入,哪些记录需要更新。对于需要更新的记录,还需要找到旧的记录所在的文件。(这个过程被称为tagging)
- 把记录写入实际的文件
MOR(Merge On Read)
回顾一下COW,这里只更新了txn_id=3这一行,却将同一个文件但没更新的数据也复制了一遍(txn_id=1和txn_id=2)。同时还存在定位txn_id=3这一行所在文件的过程,因此其写入性能较差。
Hudi引入了MOR表来优化这个问题,MOR表在更新时只会把更新的那部分数据写入一个.log文件,因为不涉及tagging,又是顺序写入的,所以写入会非常快。而当客户端要读取数据时,会有两种选择:
- 读取时动态地把.log文件和原始数据文件(称为base文件)进行merge
- 异步地把.log文件和base文件merge,如果merge还没完成,只能读到上个版本的数据
第一种办法snapshot query,优点是数据保证最新,缺点是读取的性能较差。
第二种办法read optimised query,优点是读取的性能和COW表相同,缺点是异步merge(称为compaction)有一定的延迟。
MVCC与增量读
Hudi支持Incremental Query(增量查询),是通过多版本实现的,每次更新删除数据,都会生成一个新版本记录,下图为例,有V1和V2两个版本的文件列表。
要读V2这个commit的增量更新,只需要读两个文件:fileId01_002和fileId03_001. 但会读到txn_id=1和txn_id=2的未更新记录,hudi为每个record记录了一个隐藏列:_hoodie_commit_time,hudi在增量查询是会根据这个字段过滤掉不属于时间范围的记录。

HDFS
Chain Replication
The Small Files Problem
解决方案,
计算时合并
repartition, distribute by,引入shuffle过程,只能控制文件数量,不能做到perfect划分,需要每个job单独调参,实现复杂不具体通用性
commit前合并
plugin的方式,commit前计算文件大小,做到perfect的文件大小控制,job执行时间变久一些
开发单独的归档job做异步合并
利用hive不读.开头文件的特性,及mv命令的原子性
文件格式及压缩
- 格式:Parquet,ORC
- 压缩:Zstd(Zstandard,推荐用之代替snappy)
存储(CK/Druid/HBase/Doris)
| 存储 | 数据 | 索引 | 分区 | 副本 |
|---|---|---|---|---|
| ClickHouse(ROLAP) MPP |
列式存储 | LSM-tree,primary key + order by索引,稀疏索引。由主键索引(primary.idx)+数据标记文件(.mrk文件)构成 | 建分布式表指定sharding key,hash分区 | Primary copy的异步复制,可通过参数指定同步复制:insert_distributed_sync |
| HBase Master-slave,富客户端 |
列式(Hfile),存储在HDFS | LSM-tree(优化:major/minor campaction,bloom filter,block cache) | Range partition(Region), region auto split。设计合适rowkey | HDFS副本机制 |
| Druid(MOLAP) Master-slave,有router/broker节点专门负责query |
列式,存储在deep storage(通常HDFS) | Segment level | Range partition(时间分区,druid本质是一个时序数据库),称为chunk,一个chunk可能包含一个或多个segment。chunk是逻辑的,segment是物理的 | 依赖deep storage的副本机制 |
| Doris |
HBase
数据架构

RegionServer架构

Compaction
- 算法:k-way merge sort(多路归并排序)
- Mirror compaction:把两个或多个小的HFiles合并成一个
- Major compaction:pick up region上所有的HFiles,合并成一个
ClickHouse(ROLAP)
Druid(MOLAP)
物理架构
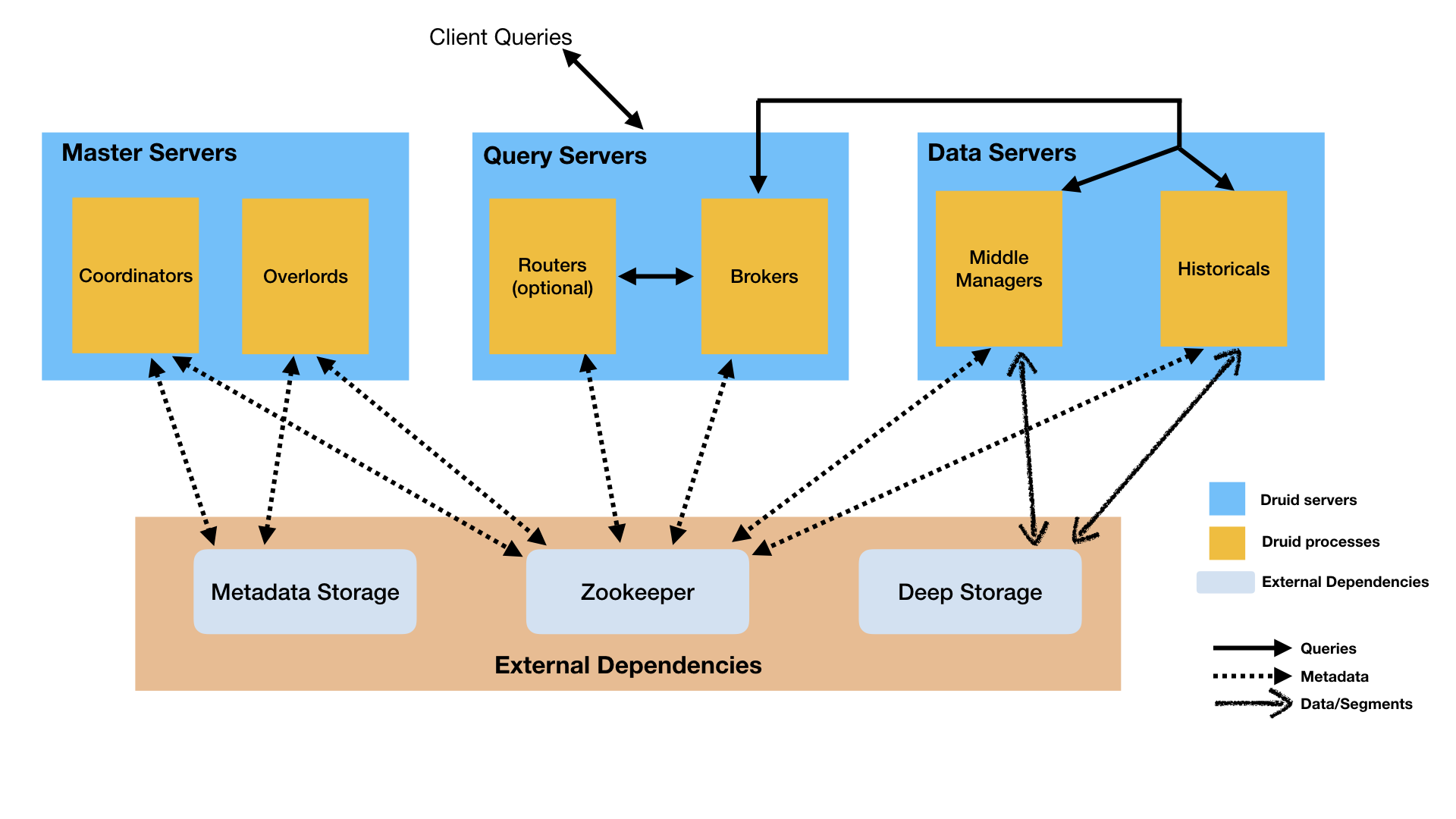
| 节点 | 功能 |
|---|---|
| Coordinator | 负责集群高可用,数据分布 |
| Overlord | 负责管理数据ingestion workloads |
| broker | 负责处理客户端的查询请求 |
| router(optional) | 负责路由请求到broker,coordinator和overlord |
| Historical | 数据存储 |
| MiddleManager | 实际进行数据ingest的节点,数据到hostorical前在这里serve |
数据架构
数据写入datasource,类似RDBMS中table的概念。datasource按time partition,每个partition叫time chunk。
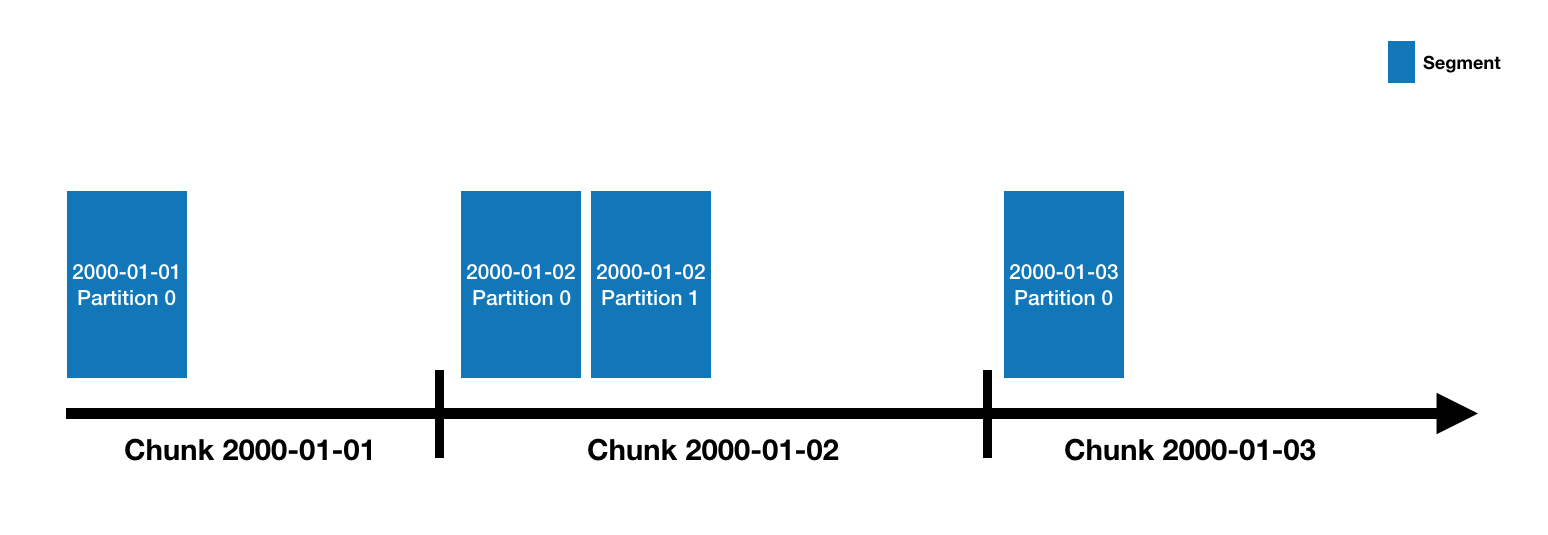
time chunk由segments组成。segment是列式存储的,列有3种类型,timestamp、dimension和metric。segment由MiddleManager创建,起初为*mutable*和*uncommitted*状态(此时已经可以serve查询了)。
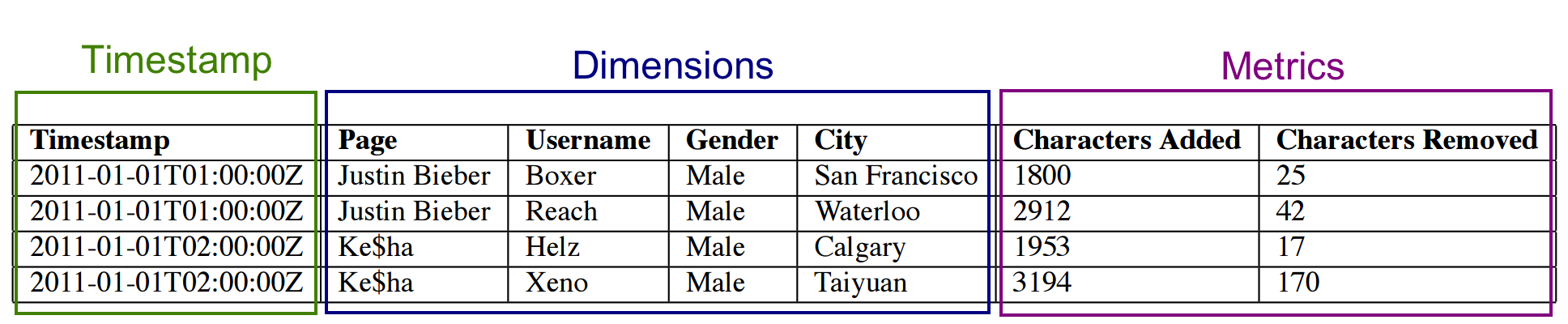
周期性的,segments被发送到deep storage,变成committed和 published状态,并且变成immutable. 这部分数据的serve也由MiddleManager交到Historical.
granularitySpec
"granularitySpec": {
"segmentGranularity": "day",
"queryGranularity": "none",
"intervals": [
"2013-08-31/2013-09-01"
],
"rollup": true
}
| 参数 | 说明 |
|---|---|
| segmentGranularity | time chunk的粒度,比如设置没week,则该week的数据都在这个time chunk中,如果week中某一天的数据有追加,则需re-build整个week的数据。因此如果有这种场景,最好将week改为day |
| queryGranularity | 数据rollup的粒度,查询的最小粒度,比如设置为hourly,则hourly内数据被rollup,不能再查更细粒度如minutely的数据了 |
| intervals | Batch ingestion时使用,指定ingest数据的time chunks范围,example: [“2021-12-06T21:27:10+00:00/2021-12-07T00:00:00+00:00”] |
| rollup | 是否rollup,按queryGranularity配置进行rollup。如果不配置,相同timestamp的数据也会rollup. |
相比于ClickHouse,Druid的架构设计更复杂(体现在不同的process type),运维成本更大。